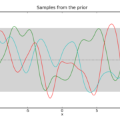
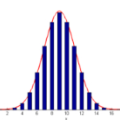
图文详解高斯过程(一)——含代码
编者按:高斯过程(Gaussian process)是概率论和统计学中的一个重要概念,它同时也被认为是一种机器学习算法,广泛应用于诸多领域。为了帮助入门者更好地理解这一简单易用的方法,近日国外机器学习开发者Alex Bridgland在博客中图文并茂地解释了高斯过程,并授权论智将文章分享给中国读者。
注:本文为系列第一篇,虽用可视化形式弱化了数学推导,但仍假设读者具备一定机器学习基础。
现如今,高斯过程可能称不上是机器学习领域的炒作核心,但它仍然活跃在研究的最前沿。从AlphaGo到AlphaGo Zero,Deepmind在MCTS超参数自动调优上一直表现出对高斯过程优化的信心,而这的确是它的优势领域。当涉及丰富的建模可能性和大量随机参数时,高斯过程十分简单易用。
但是,掌握高斯过程不是一件简单的事,尤其是如果你已经用惯了深度学习常用的那些模型。为了解决这个问题,我特意撰写了这篇文章,并用一种直观地、可视化的方式结合理论向初学者介绍。我已在github上传了我的Jupyter Notebook,建议读者前往下载,并结合函数图像和代码来对整个概念建立清晰认识。
什么是高斯过程?
高斯过程(GP)是一种强大的模型,它可以被用来表示函数的分布情况。当前,机器学习的常见做法是把函数参数化,然后用产生的参数建模来规避分布表示(如线性回归的权重)。但GP不同,它直接对函数建模生成非参数模型。由此产生的一个突出优势就是它不仅能模拟任何黑盒函数,还能模拟不确定性。这种对不确定性的量化是十分重要的,如当我们被允许请求更多数据时,依靠高斯过程,我们能探索最不可能实现高效训练的数据区域。这也是贝叶斯优化背后的主要思想。
如果你给我几张猫和狗的图片,要我对一张新的猫咪照片分类,我可以很有信心地给你一个判断。但是,如果你给我一张鸵鸟照片,强迫我说出它是猫还是狗,我就只能信心全无地预测一下。 ——Yarin Gal
为了更好地介绍这一概念,我们假定一个没有噪声的高斯回归(其实GP可以扩展到多维和噪声数据):
假设有一个隐藏函数:f:ℝ→ℝ,我们要对它建模;
fx
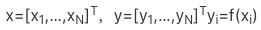
用高斯建模函数
GP背后的关键思想是可以使用无限维多变量高斯分布来对函数进行建模。换句话说,输入空间中的每个点都与一个随机变量相关联,而它们的联合分布可以被作为多元高斯分布建模。
这是什么意思呢?让我们从一个简单的例子开始:二维高斯分布。
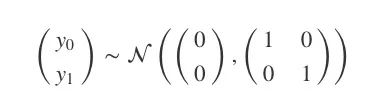
上式可以被可视化为一个3D的钟形曲线,其中概率密度为其高度。如果我们不把它作为一个整体来看,而是从它的分布中抽样,那会怎么样?比如说,我们一次从图中抽取两点,反复进行10次,并把第一个值记录在x=0,第二个值在x=1,然后在两点间绘制线段。
def plot_unit_gaussian_samples(D):
p = figure(plot_width=800, plot_height=500,
title='Samples from a unit {}D Gaussian'.format(D))
xs = np.linspace(0, 1, D)
for color in Category10[10]:
ys = np.random.multivariate_normal(np.zeros(D), np.eye(D))
p.line(xs, ys, line_width=1, color=color)
return p
show(plot_unit_gaussian_samples(2))
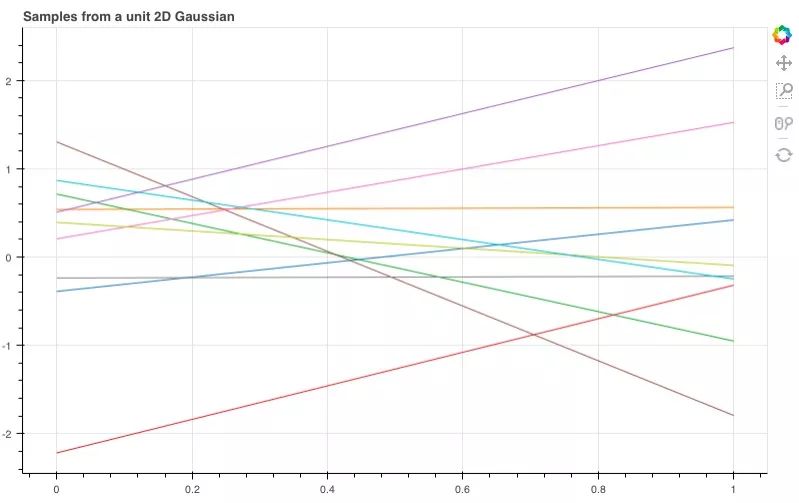
如图所示,这10根线条就是我们刚才抽样的10个线性函数。那如果我们扩展到20维,它们会呈怎样的分布呢?
show(plot_unit_gaussian_samples(20))
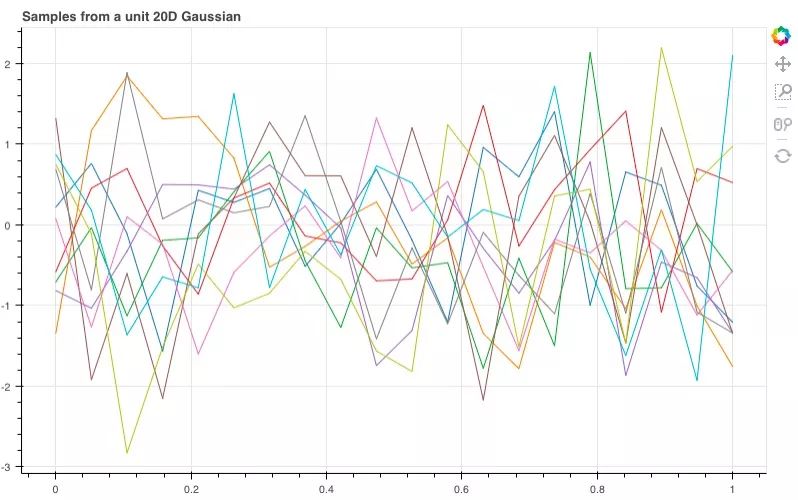
经过调整,我们得到了这样的函数曲线,虽然整体非常杂乱,但它们包含了许多有用的信息,能让我们推敲想从这些样本中获得什么,以及如何改变分布来获得更好的样本。
多元高斯分布有两个重要参数,一个是均值函数,另一个是协方差函数。如果只改变均值,那我们改变的只有曲线的整体趋势(如果均值函数是上升的,例:np.arange(D),曲线就会有一个整体的线性上升趋势),而锯齿状的噪声形状依然存在。鉴于这个特征,我们一般倾向于设GP的均值函数为0(即使不改变均值,GP也能对许多函数建模)。
解决了曲线形态,那么接下来,我们就要为它们增加一些平滑度(smoothness)。例如,如果两个样本非常接近,那我们自然会希望它们的函数值,即y值也非常相近。而把这个放进我们的模型中,就是样本附近的随机变量对应到它们联合分布(高维协方差)上的值应当和样本对应的值十分接近。
现在,这些点的协方差被定义在高斯协方差矩阵中,考虑到我们有的是一个N维的高斯模型:y0,…,yN,那么这就是一个N×N的协方差矩阵Σ,那么矩阵中的(i,j)就是Σij=cov(yi,yj)。换句话说,协方差矩阵Σ是对称的,它包含了模型上所有随机变量的协方差(一对)。
用核函数实现平滑
那么我们该如何定义我们的协方差函数呢?这时高斯过程的一个重要概念核函数(kernel)就要登场了。为了实现我们的目的,我们可以设一个平方形式的核函数(最简形式):
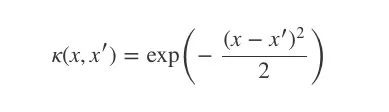
当x=x′时,核函数k(x,x′)等于1;x和x′相差越大,k越趋向于0。
def k(xs, ys, sigma=1, l=1):
"""Sqared Exponential kernel as above but designed to return the whole
covariance matrix - i.e. the pairwise covariance of the vectors xs & ys.
Also with two parameters which are discussed at the end."""
# Pairwise difference matrix.
dx = np.expand_dims(xs, 1) - np.expand_dims(ys, 0)
return (sigma ** 2) * np.exp(-((dx / l) ** 2) / 2)
def m(x):
"""The mean function. As discussed, we can let the mean always be zero."""
return np.zeros_like(x)
我们可以这样绘制核函数的曲线,并观察图像变化:当x=x′时,函数值最大;当两个输入变得越来越不同,曲线逐渐呈平滑下降趋势。
N = 100
x = np.linspace(-2, 2, N)
y = np.linspace(-2, 2, N)
d = k(x, y)
color_mapper = LinearColorMapper(palette="Plasma256", low=0, high=1)
p = figure(plot_width=400, plot_height=400, x_range=(-2, 2), y_range=(-2, 2),
title='Visualisation of k(x, x\')', x_axis_label='x',
y_axis_label='x\'', toolbar_location=None)
p.image(image=[d], color_mapper=color_mapper, x=-2, y=-2, dw=4, dh=4)
color_bar = ColorBar(color_mapper=color_mapper, ticker=BasicTicker(),
label_standoff=12, border_line_color=None, location=(0,0))
p.add_layout(color_bar, 'right')
show(p)
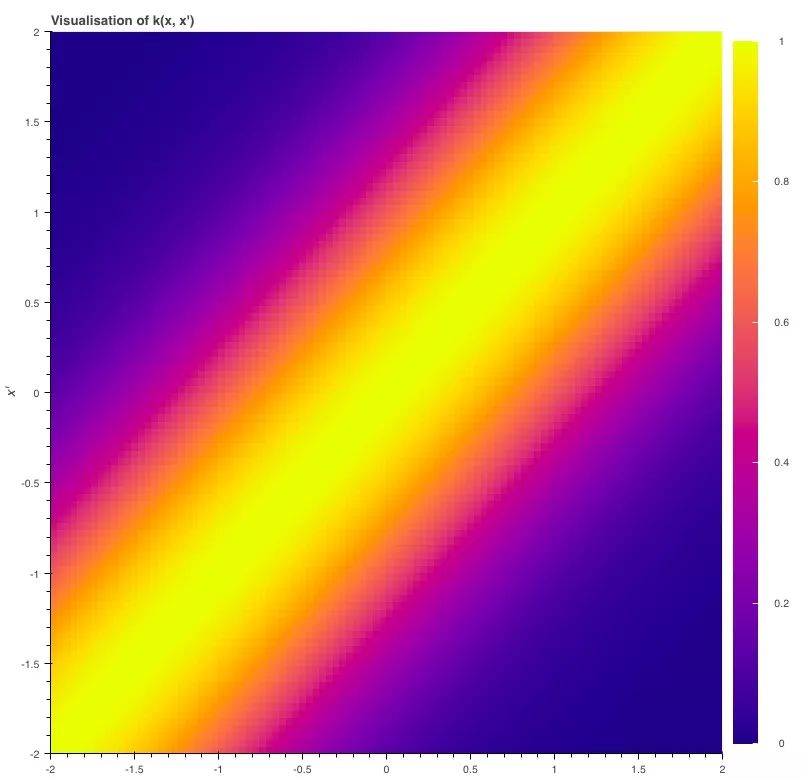
为了实现平滑度,我们会希望xi和xj的协方差yi和yj就等于核函数k(xi,xj)——xi、xj越接近,协方差越高。
利用上文中的函数,我们可得矩阵(xs,xs)。接下来,让我们从20维高斯分布中抽取另外10个样本,不同的是,这一次我们用了新的协方差矩阵。
p = figure(plot_width=800, plot_height=500)
D = 20
xs = np.linspace(0, 1, D)
for color in Category10[10]:
ys = np.random.multivariate_normal(m(xs), k(xs, xs))
p.circle(xs, ys, size=3, color=color)
p.line(xs, ys, line_width=1, color=color)
show(p)
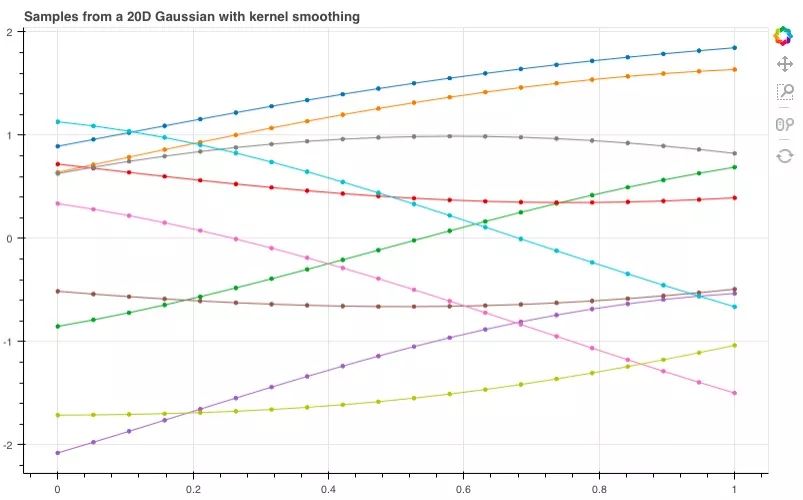
现在,我们似乎获得了一些看起来有点用的函数分布。随着维数增加,我们甚至不再需要连接各个点,因为我们可以为任何可能的输入指定一个点。
那么,如果进一步提高维数,比如到100维呢?
n = 100
xs = np.linspace(-5, 5, n)
K = k(xs, xs)
mu = m(xs)
p = figure(plot_width=800, plot_height=500)
for color in Category10[5]:
ys = np.random.multivariate_normal(mu, K)
p.line(xs, ys, line_width=2, color=color)
show(p)
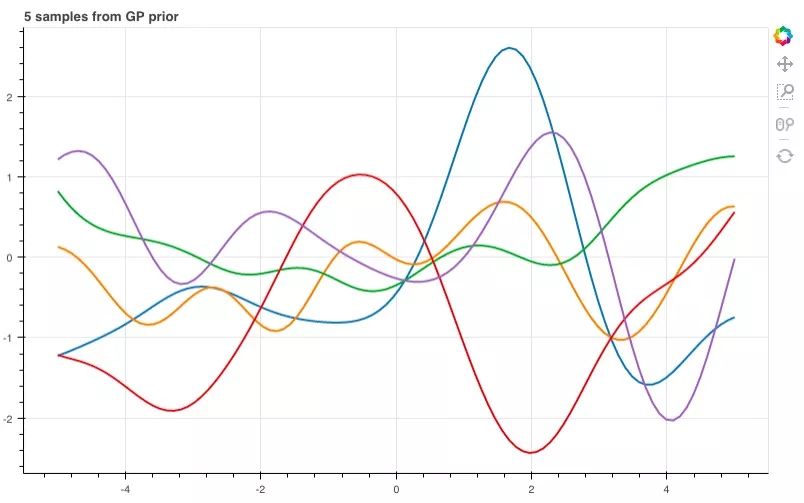
用先验和观察进行预测
现在我们已经有了一个函数分布,之后就要用训练数据来模拟那个隐藏函数,从而预测y值。
首先,我们需要一些训练数据。
隐藏函数f
为了介绍它,我先用一个5次方程:
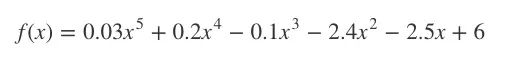
之所以这么选,是因为它的图适合讲解,事实上我们可以随便设。
# coefs[i] is the coefficient of x^i
coefs = [6, -2.5, -2.4, -0.1, 0.2, 0.03]
def f(x):
total = 0
for exp, coef in enumerate(coefs):
total += coef * (x ** exp)
return total
xs = np.linspace(-5.0, 3.5, 100)
ys = f(xs)
p = figure(plot_width=800, plot_height=400, x_axis_label='x',
y_axis_label='f(x)', title='The hidden function f(x)')
p.line(xs, ys, line_width=2)
show(p)
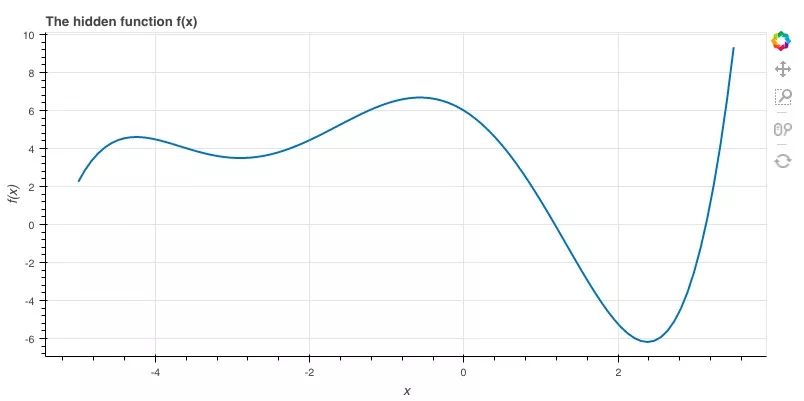
数学计算
现在我们到了GP的核心部分,需要涉及一点点数学计算,但它其实只是我们用来调整观测数据联合分布的一种方法。
我们用多元高斯分布对p(y|x)建模:
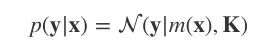
K=κ(x,x),均值函数m(x)=0。
这是一个先验分布,表示在观察任何数据前,我们期望在输入x后获得的输出y。
之后,我们导入一些输入为x的训练数据,并输出y=f(x)。接着,我们设有一些新输入x∗,需要计算y∗=f(x∗)。
x_obs = np.array([-4, -1.5, 0, 1.5, 2.5, 2.7])
y_obs = f(x_obs)
x_s = np.linspace(-8, 7, 80)
我们将所有y和y∗的联合分布建模为:
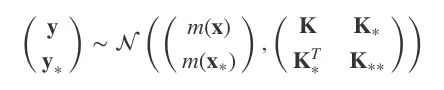
其中,K=κ(x,x), K∗=κ(x,x∗), K∗∗=κ(x∗,x∗),均值函数为0。
现在,模型成了p(y,y∗|x,x∗),而我们需要的是y∗。
调节多元高斯分布
比起反推回去,其实我们可以利用这个标准结果。由于我们已有y和y∗的联合分布,在这个基础上我们想对y的数据做条件处理,那就会得到:
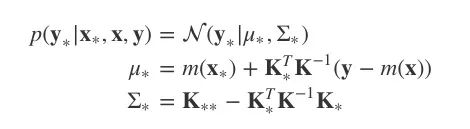
这就是基于先验分布和观察值计算出的关于y∗的后验分布。
注:由于K条件不当,以下代码可能是不准确的,我会在第二篇文章中介绍一种更好的方法。
K = k(x_obs, x_obs)
K_s = k(x_obs, x_s)
K_ss = k(x_s, x_s)
K_sTKinv = np.matmul(K_s.T, np.linalg.pinv(K))
mu_s = m(x_s) + np.matmul(K_sTKinv, y_obs - m(x_obs))
Sigma_s = K_ss - np.matmul(K_sTKinv, K_s)
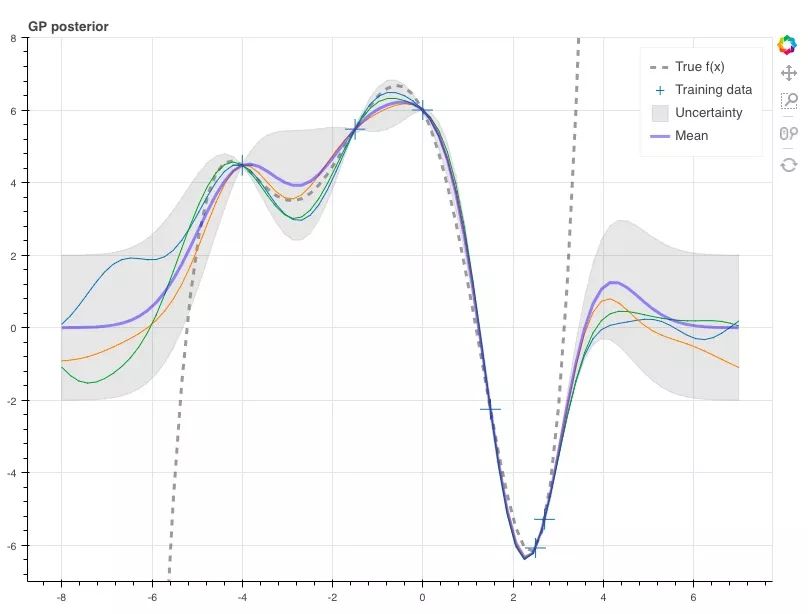
这样,我们就能根据这两个参数从条件分布中抽取样本。在这里,我们设真函数f(x)与它们相对应。由于使用了GP,每个随机变量的方差中会包含不确定性,而矩阵中第i个随机变量的协方差是Σ∗ii,也就是矩阵Σ∗的一个对角元素,所以在这里,我们得到样本的标准差为±2。
p = figure(plot_width=800, plot_height=600, y_range=(-7, 8))
y_true = f(x_s)
p.line(x_s, y_true, line_width=3, color='black', alpha=0.4,
line_dash='dashed', legend='True f(x)')
p.cross(x_obs, y_obs, size=20, legend='Training data')
stds = np.sqrt(Sigma_s.diagonal())
err_xs = np.concatenate((x_s, np.flip(x_s, 0)))
err_ys = np.concatenate((mu_s + 2 * stds, np.flip(mu_s - 2 * stds, 0)))
p.patch(err_xs, err_ys, alpha=0.2, line_width=0, color='grey',
legend='Uncertainty')
for color in Category10[3]:
y_s = np.random.multivariate_normal(mu_s, Sigma_s)
p.line(x_s, y_s, line_width=1, color=color)
p.line(x_s, mu_s, line_width=3, color='blue', alpha=0.4, legend='Mean')
show(p)
下篇预告
在实现中,为了获得更好的训练效果,我们往往要做更多调整计算。你也许已经注意到了,GP包含两个非常重要的参数σ和l,如果你在之前采集样本的时候尝试改变过它们,那你会发现图像在垂直和水平方向上的神奇变化。例如,如果我们期望更大范围的输出,我们就需要相应地放大参数σ。事实上,和所有会用到核函数的方法一样,如果有需要,我们甚至可以完全改变核函数。
尽管选择核函数是专家学者们的事,但是通过控制loss最小化,我们可以自动选择参数,而这正是高斯过程带给我们的。
此外,我们还要考虑样本不完美,即出现噪声数据的情况。在这时,我们需要把这种不确定性归于模型并做一些泛化调整。
在下篇文章中,我将集中讲解高斯过程回归和噪声数据,敬请期待!
原文地址:bridg.land/posts/gaussian-processes-1
Github:gist.github.com/Bridgo/429594942ff51037ecc703905e40c562