使用 MediaPipe 和 TensorFlow.js 进行人体分割


发布人:Google 团队 Ivan Grishchenko、Valentin Bazarevsky、Ahmed Sabie、Jason Mayes
随着人们对健康和健身的兴趣日益浓厚,去年我们看到越来越多的 TensorFlow.js 用户开始涉及这一领域,使用了我们与人体相关的现有 ML 模型,如 Face Mesh、人体姿态和手部姿态预测等。
Face Mesh
https://www.npmjs.com/package/@tensorflow-models/face-landmarks-detection
人体姿态
https://github.com/tensorflow/tfjs-models/tree/master/pose-detection
手部姿态
https://github.com/tensorflow/tfjs-models/tree/master/hand-pose-detection
日前,我们发布了两个全新的高度优化人体分割模型,这两个模型不仅准确快捷,同时也是 TensorFlow.js 中更新后的人体分割和姿态 API 的重要组成部分。
TensorFlow.js
https://tensorflow.google.cn/js
首先是 BlazePose GHUM 姿态预测模型,该模型如今可在人体分割领域提供额外支持。如下动图所示,该模型是我们提供的统一姿态检测 API 的组成部分,可以同时进行全身分割和 3D 姿态预测。例如,该模型非常适合用于分割在远距离下拍摄的全身人体,可精准捕获脚部和腿部区域。
BlazePose GHUM 姿势预测模型
https://github.com/tensorflow/tfjs-models/tree/master/pose-detection/src/blazepose_mediapipe

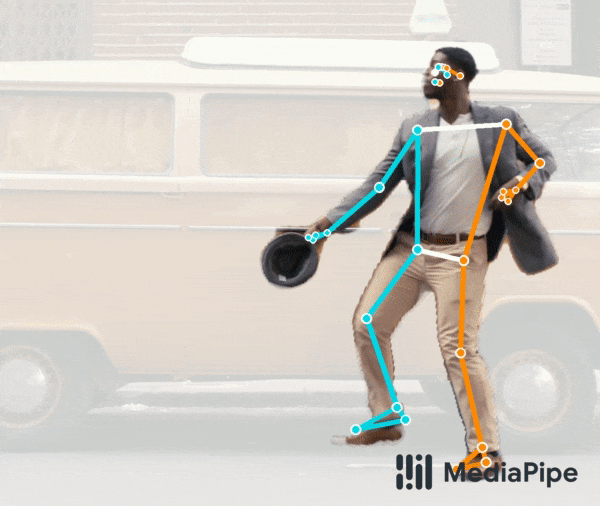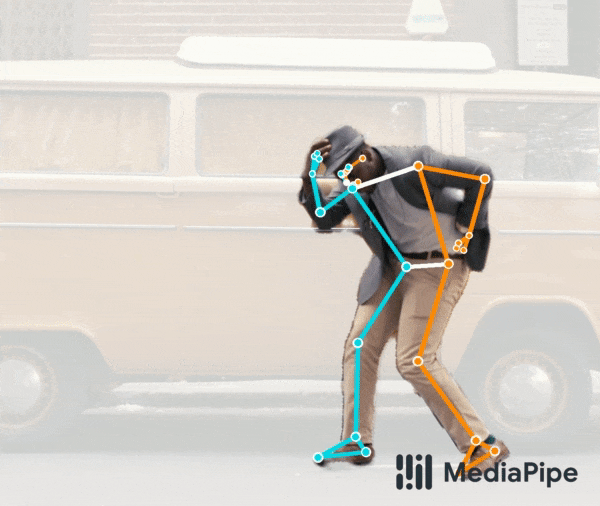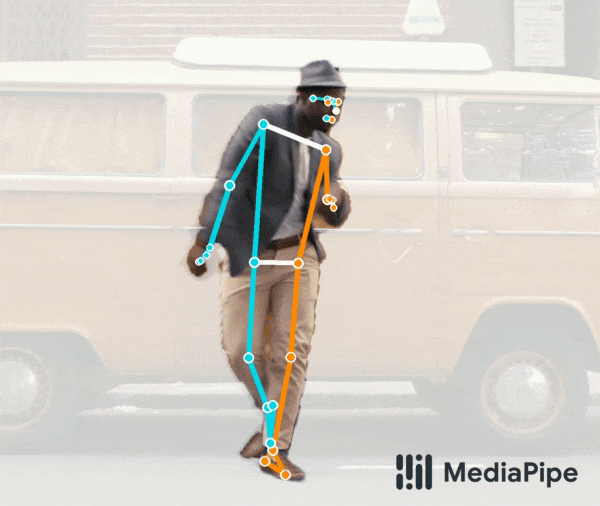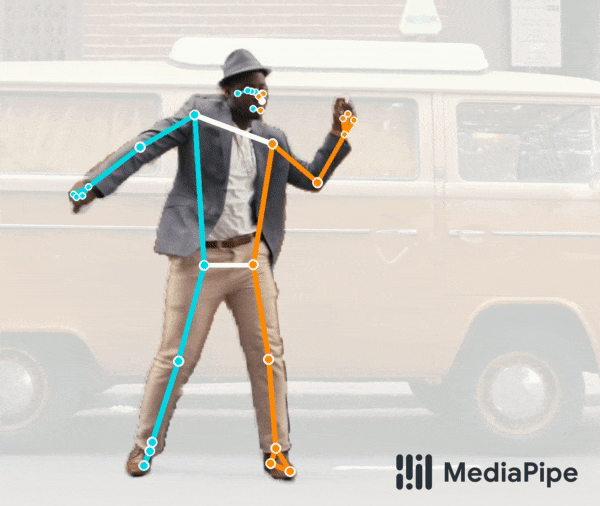
试用实时演示版!
试用实时演示版!
https://storage.googleapis.com/tfjs-models/demos/segmentation/index.html?model=blazepose
我们发布的第二个模型是自拍人像抠图模型,该模型非常适合用于人们在网络摄像头前进行视频通话的情况(距离小于 2 米),如下动图所示。该模型是我们统一人体分割 API 的组成部分,在检测上半身时可以表现出较高的准确率,但在某些情况下,检测下半身时准确率可能会降低。

试用实时演示版!
试用实时演示版!
https://storage.googleapis.com/tfjs-models/demos/segmentation/index.html?model=selfie_segmentation
这两种新模型催生了一系列以人体为中心的创新性应用,从而推动下一代 Web 应用的发展。例如,BlazePose GHUM 姿态模型可以为多种服务提供支持,例如通过数字形式将您的存在传送到世界任何地点、为线上裁缝估算身体尺寸,或者是为音乐视频制作特效等等,可能性无穷无尽。相对而言,自拍人像抠图模型则可以在基于 Web 的视频通话中实现简单易用的功能。比如在上面的演示中,您可以准确地改变或模糊背景。
通过数字形式将您的存在传送到
https://twitter.com/Google/status/1286753701491867651
为线上裁缝估算身体尺寸
https://www.youtube.com/watch?v=kFtIddNLcuM
在此次发布之前,很多用户可能已经体验过 BodyPix 模型,该模型在发布时代表了当时最先进的模型水平。我们现在发布的两个全新模型,则可以为不同案例中的设备提供更高的 FPS 和保真度。
BodyPix
https://github.com/tensorflow/tfjs-models/tree/master/body-pix


人体分割 API 可为自拍人像抠图模型提供两个运行时,分别是 MediaPipe 运行时和 TensorFlow.js 运行时。
要安装 API 和运行时库,您可在 html 文件中使用 <script> 标签或使用 NPM。
通过脚本标签:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl">
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/body-segmentation">
<!-- Optional: Include below scripts if you want to use TensorFlow.js runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter">
<!-- Optional: Include below scripts if you want to use MediaPipe runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation">通过 NPM:
yarn add @tensorflow/tfjs-core @tensorflow/tfjs-backend-webgl
yarn add @tensorflow-models/body-segmentation
# Run below commands if you want to use TensorFlow.js runtime.
yarn add @tensorflow/tfjs-converter
# Run below commands if you want to use MediaPipe runtime.
yarn add @mediapipe/selfie_segmentation要在 JS 代码中引用 API,具体操作取决于您安装库的方式。
如果是通过脚本标签安装,您可以通过全局命名空间 bodySegmentation 引用库。
如果是通过 NPM 安装,您需要首先导入库:
import '@tensorflow/tfjs-backend-core';
import '@tensorflow/tfjs-backend-webgl';
import * as bodySegmentation from '@tensorflow-models/body-segmentation';
// Uncomment the line below if you want to use TensorFlow.js runtime.
// import '@tensorflow/tfjs-converter';
// Uncomment the line below if you want to use MediaPipe runtime.
// import '@mediapipe/selfie_segmentation';首先,您需要创建分割器:
const model = bodySegmentation.SupportedModels.MediaPipeSelfieSegmentation; // or 'BodyPix'
const segmenterConfig = {
runtime: 'mediapipe', // or 'tfjs'
modelType: 'general' // or 'landscape'
};
segmenter = await bodySegmentation.createSegmenter(model, segmenterConfig);选择一个适合您应用需求的 modelType,您可从 general 和 landscape 两个选项中进行选择。从 landscape 到 general,准确率递增,但推断速度递减。请尝试我们的实时演示版来比较不同配置间的差异。
有了分割器后,您就可以传入视频串流、静态图像或 TensorFlow.js 张量来分割人体:
const video = document.getElementById('video');
const people = await segmenter.segmentPeople(video);如何使用输出结果?
上述 people 结果代表了图像帧中发现的分割后人体的数组。然而,每个模型在给定的分割条件下,语义也各有差异。
对于自拍人像抠图模型而言,数组长度刚好为 1,其中单次分割操作对应图像帧中的所有人体。每个 segmentation 中都包含 maskValueToLabel 和 mask 属性,详细信息如下所示。
mask 字段存储的对象可以提供对分割潜在结果的访问权限。然后,您可以利用提供的异步转换函数(如 toCanvasImageSource、toImageData 和 toTensor),具体取决于您想要提高效率的输出类型。
请注意:不同的模型有不同的内部数据表示。因此将一种形式的分割转换为另一种形式可能会花费大量成本。为了提高效率,您可以调用 getUnderlyingType 来确定分割的形式,这样您便可以选择保持相同的形式,以便更快地获取结果。
mask RGBA 值的语义如下所示:图像掩码的大小与输入图像相同,其中绿色和蓝色通道总是设置为 0。不同的红色值代表不同的身体部位(参见下方的 maskValueToLabel 键)。不同的 alpha 值代表像素是人体像素的可能性(最低可能性为 0,最高可能性为 255)。
maskValueToLabel 将像素的红色通道值映射到该像素的分割部位名称。此规则无需在不同模型间保持一致(例如自拍人像抠图模型由于无法分辨身体各个部分,总是会返回“person”;而类似 BodyPix 的模型会返回身体各个部位的名称,因为这类模型能够辨别每个分割后的像素)。请查看下面的输出片段示例:
[
{
maskValueToLabel: (maskValue: number) => { return 'person' },
mask: {
toCanvasImageSource(): ...
toImageData(): ...
toTensor(): ...
getUnderlyingType(): ...
}
}
]同样我们也提供可选的实用函数,以便您可以使用该函数来渲染分割结果。使用 toBinaryMask 函数将分割结果转换为 ImageData 对象。
该函数使用 5 个参数,其中后 4 个参数为可选参数:
来自以上 segmentPeople 调用的分割结果。
前景色:用于渲染前景像素的表示 RGBA 值的对象。
背景色:用于背景像素的带有 RGBA 值的对象。
绘制轮廓:如果要在所发现人员的身体周围绘制轮廓线,请使用布尔值。
前景阈值:前景像素和背景像素的临界点。该值为 0 到 1 之间的浮点值。
通过 toBinaryMask 得到 imageData 对象后,您可以使用 drawMask 函数将此对象渲染到您选择的画布上。
以下是使用这两个函数的示例代码:
const foregroundColor = {r: 0, g: 0, b: 0, a: 0};
const backgroundColor = {r: 0, g: 0, b: 0, a: 255};
const drawContour = true;
const foregroundThreshold = 0.6;
const backgroundDarkeningMask = await bodySegmentation.toBinaryMask(people, foregroundColor, backgroundColor, drawContour, foregroundThreshold);
const opacity = 0.7;
const maskBlurAmount = 3; // Number of pixels to blur by.
const canvas = document.getElementById('canvas');
const people = await bodySegmentation.drawMask(canvas, video, backgroundDarkeningMask, opacity, maskBlurAmount);如要加载和使用 BlazePose GHUM 模型,请参考统一的姿态 API 文档。该模型有三种输出结果:
姿态 API 文档
https://github.com/tensorflow/tfjs-models/tree/master/pose-detection
2D 关键点
3D 关键点
对每个发现的姿态进行的分割
如果您需要从姿态结果中获取分割结果,您只需要该姿态分割属性的引用,如下所示:
const poses = await detector.estimatePoses(video);
const firstSegmentation = poses.length > 0 ? poses[0].segmentation : null;BlazePose GHUM 模型和 MediaPipe 自拍人像抠图模型均能对画面中的突出人物进行分割。两种模型都可以在笔记本电脑和智能手机上实时运行,但正如本文开始时讨论的,预期的应用可能会有所不同。自拍人像抠图适合用于近距离(小于 2 米)的自拍效果和会议,BlazePose GHUM 则适用于距离摄像头 4 米以内的全身捕捉,如瑜伽、健身和舞蹈。

自拍人像抠图
自拍人像抠图模型可以预测人体前景的二进制分割掩码。流水线的结构完全在 GPU 上运行,无论是基于神经网络推断的图像采集还是将分割结果呈现在屏幕上。这样可避免缓慢的 CPU 到 GPU 同步,从而实现性能最大化。模型的多种变体都支持在 Google Meet 中替换背景,现可在 TensorFlow.js 和 MediaPipe 中使用更通用的模型。
在 Google Meet 中替换背景
https://ai.googleblog.com/2020/10/background-features-in-google-meet.html
TensorFlow.js
https://github.com/tensorflow/tfjs-models/tree/master/body-segmentation
MediaPipe
https://google.github.io/mediapipe/solutions/selfie_segmentation

BlazePose GHUM 2D 界标和人体分割
除了之前介绍的 2D 和 3D 界标,BlazePose GHUM 模型现在还提供人体分割掩码。使用可预测两个输出结果的单个模型,有以下两个好处。第一个好处是该模型允许输出结果相互监督和改进,因为界标只能给出语义结构,而分割只会注重边缘轮廓。其次,该模型能够保证预测的掩码和标记点属于同一个人,分开使用模型很难实现这一点。由于 BlazePose GHUM 模型只能在人像的 ROI 裁剪图像上运行(相较于全尺寸图像),所以分割掩码的质量只取决于 ROI 内的有效分辨率,当人体靠近或远离摄像头时,质量不会出现很大的变化。
2D
https://blog.tensorflow.org/2021/05/high-fidelity-pose-tracking-with-mediapipe-blazepose-and-tfjs.html
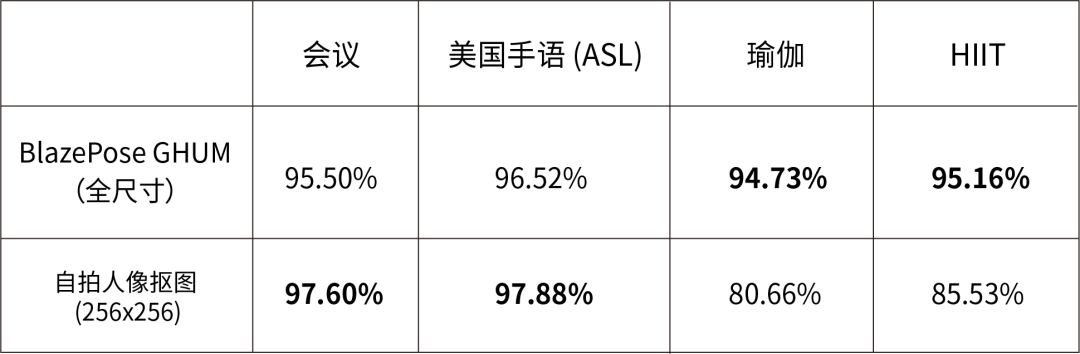
在不同领域中的 BlazePose GHUM 和自拍人像抠图 IOU
使用每种运行时都有一定的优点和缺点。如下面的性能表所示,MediaPipe 运行时在桌面设备、笔记本电脑和 Android 手机上的推断速度较快,TensorFlow.js 运行时在 iPhone 和 iPad 上的推断速度较快。
这里的 FPS 值指的是通过模型执行推断以及等待 GPU 和 CPU 同步所花费的时间。此操作是为了确保 GPU 已经完全完成基准测试,但对于只使用 GPU 进行生产的流水线来说,无需花费时间等待同步,所以这一数值仍有优化空间。对于只使用 GPU 的流水线来说,如果您使用的是 MediaPipe 运行时,您只需要使用 await mask.toCanvasImageSource();如果您使用的是 TF.js 运行时,请参考此示例,了解如何直接在 GPU 上使用纹理来达到渲染效果。
此示例
https://github.com/tensorflow/tfjs-examples/tree/master/gpu-pipeline
自拍人像抠图模型

自拍人像抠图在不同设备和运行时中的推断速度。每个单元格中的第一个数字代表横屏模型,第二个数字代表通用模型
BlazePose GHUM 模型

BlazePose GHUM 全身分割在不同设备和运行时中的推断速度。每个单元格中的第一个数字代表精简模型,第二个数字代表完整模型,第三个数字代表庞大模型。注意:可在模型参数中将 enableSegmentation 设置为 False,从而关闭分割输出结果,此操作将提升模型的性能
我们一直致力于研发新功能,并对技术质量作出改进(例如我们在 BlazePose GHUM 最初的 2D 版本发布后推出了 3D 版本更新,同时于去年进行了第三次 BlazePose GHUM 更新),所以在不远的将来我们将推出更多激动人心的更新,敬请期待!
我们想要对在创建自拍人像抠图和 BlazePose GHUM 模型,以及构建 API 的过程中,参与其中或提供帮助的各位同事表示感谢:Siargey Pisarchyk、Tingbo Hou、Artsiom Ablavatski、Karthik Raveendran、Eduard Gabriel Bazavan、Andrei Zanfir、Cristian Sminchisescu、Chuo-Ling Chang、Matthias Grundmann、Michael Hays、Tyler Mullen、Na Li、Ping Yu。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




