![]()
作者 | MediaPipe 团队
来源 | TensorFlow(ID:tensorflowers)
【导读】我爱计算机视觉(aicvml)CV君推荐道:“虽然它是出自Google Research,但不是一个实验品,而是已经应用于谷歌多款产品中,还在开发中,将来也许会成为一款重要的专注于媒体的机器学习应用框架,非常值得做计算机视觉相关工程开发的朋友参考。”
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 MediaPipe。
https://github.com/google/mediapipe
作为一款跨平台框架,MediaPipe 不仅可以被部署在服务器端,更可以在多个移动端 (安卓和苹果 iOS)和嵌入式平台(Google Coral 和树莓派)中作为设备端机器学习推理 (On-device Machine Learning Inference)框架。
一款多媒体机器学习应用的成败除了依赖于模型本身的好坏,还取决于设备资源的有效调配、多个输入流之间的高效同步、跨平台部署上的便捷程度、以及应用搭建的快速与否。
基于这些需求,谷歌开发并开源了 MediaPipe 项目。除了上述的特性,MediaPipe 还支持 TensorFlow 和 TF Lite 的推理引擎(Inference Engine),任何 TensorFlow 和 TF Lite 的模型都可以在 MediaPipe 上使用。同时,在移动端和嵌入式平台,MediaPipe 也支持设备本身的 GPU 加速。
在今年六月举行的 CVPR 会议上,Google Research 开源了 MediaPipe 的预览版。为方便开发者学习和使用,我们提供了多个桌面系统和移动端的示例。作为一款应用于多媒体的框架,现已开源的安卓和苹果 iOS 示例包括:
3D 手部标志追踪
![]()
人脸检测
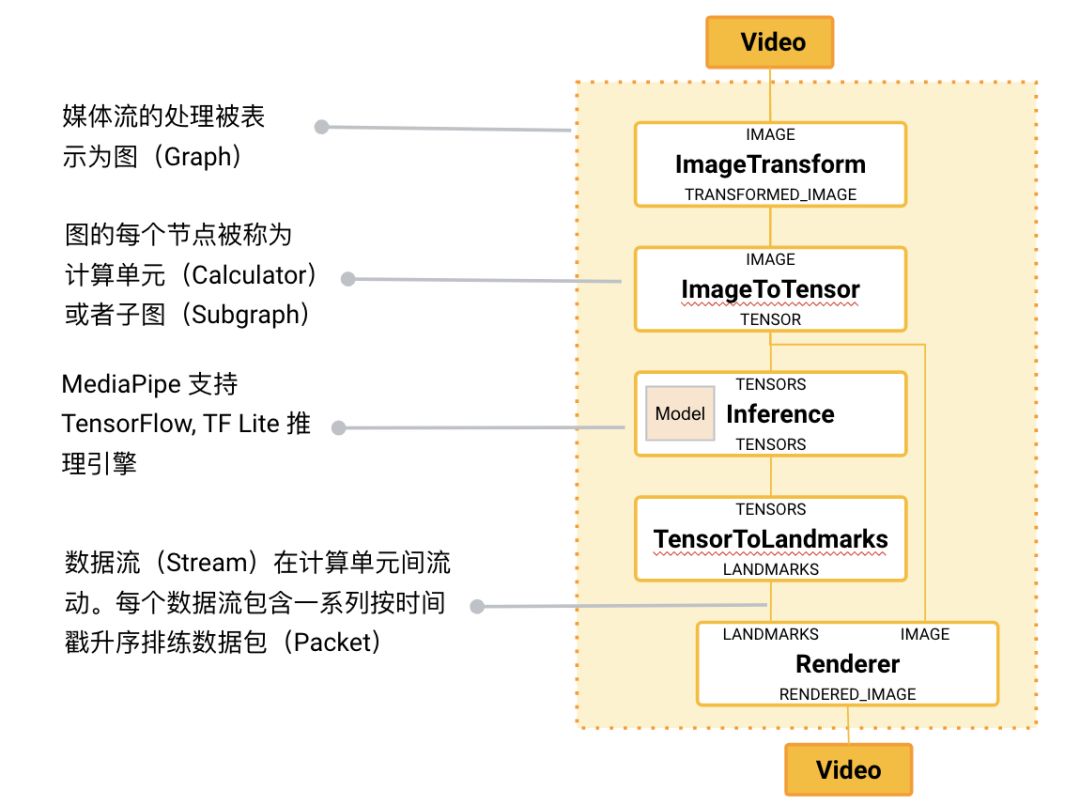
MediaPipe 的核心框架由 C++ 实现,并提供 Java 以及 Objective C 等语言的支持。MediaPipe 的主要概念包括数据包(Packet)、数据流(Stream)、计算单元(Calculator)、图(Graph)以及子图(Subgraph)。数据包是最基础的数据单位,一个数据包代表了在某一特定时间节点的数据,例如一帧图像或一小段音频信号;数据流是由按时间顺序升序排列的多个数据包组成,一个数据流的某一特定时间戳(Timestamp)只允许至多一个数据包的存在;而数据流则是在多个计算单元构成的图中流动。MediaPipe 的图是有向的——数据包从数据源(Source Calculator或者 Graph Input Stream)流入图直至在汇聚结点(Sink Calculator 或者 Graph Output Stream) 离开。
MediaPipe 在开源了多个由谷歌内部团队实现的计算单元(Calculator)的同时,也向用户提供定制新计算单元的接口。创建一个新的 Calculator,需要用户实现 Open(),Process(),Close() 去分别定义 Calculator 的初始化,针对数据流的处理方法,以及 Calculator 在完成所有运算后的关闭步骤。为了方便用户在多个图中复用已有的通用组件,例如图像数据的预处理、模型的推理以及图像的渲染等, MediaPipe 引入了子图(Subgraph)的概念。因此,一个 MediaPipe 图中的节点既可以是计算单元,亦可以是子图。子图在不同图内的复用,方便了大规模模块化的应用搭建。
https://github.com/google/mediapipe/tree/master/mediapipe/calculators
想了解更多 MediaPipe 的概念和使用方法,请移步我们的 GitHub 文档。同时,我们也提供了MediaPipe 移动端的使用教程及示例代码:
-
MediaPipe 苹果 iOS Hello World! 教程和代码
-
MediaPipe 安卓 Hello World! 教程和代码
手部关键点追踪解决方案有两部分:手掌检测(Hand Detection)及手部关键点回归 (Hand Landmark Regression)。
本文将详细讲解第一部分:手掌检测。详解第二部分手部关键点检测的文章,将于近期在谷歌 TensorFlow 的微信公众号发表。请从 MediaPipe 下载手部关键点追踪的模型和图。手掌检测应用的输出结果如下图所示:
我们训练了基于SSD 架构的 BlazePalm 模型来进行手掌检测,并对移动端进行了优化。手部检测相较人脸检测来说,是一个更加困难的问题,例如:手的大小角度会有较大范围的变动,手没有显著的纹理结构,以及存在更多遮挡的情景。因此,我们的解决方案采取了不同的思路。我们训练的模型只对手掌区域进行检测,其好处体现在以下几点:首先,手掌相对于整个手而言是一个较为受限的目标,并且由于手掌的区域较小,我们的非极大抑制(Non-Maximum Suppression)算法也会有更好的效果,例如,在两只手相握的情况下,即使手的大部分区域重叠在一起,两只手掌的区域依然可以被区分开;其次,手掌的边框可以用正方形来描述,这样可以减少 3-5 倍数量的锚定位(Anchor),从而最大化模型的容量;最后,经过实验,我们发现使用focal loss可以获得最好的检测结果。该模型在我们的测试数据集上可以达到 95.7% 的平均准确率。
注:
MediaPipe BlazePlam 手掌检测应用 链接
https://github.com/google/mediapipe/blob/master/mediapipe/docs/hand_detection_mobile_gpu.md
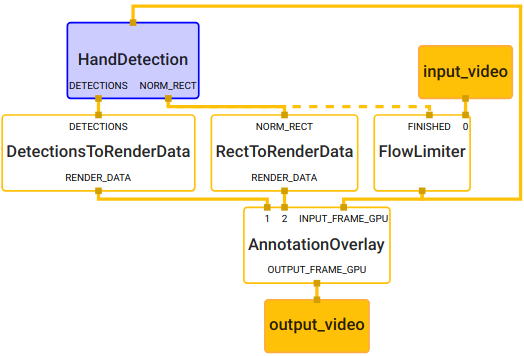
我们使用 MediaPipe 来做移动端模型推理的框架,如下图所示,input_video 为输入图像,output_video 为输出图像。为了保证整个应用的实时运算,我们使用 FlowLimiterCalculator 来筛选进行运算的输入帧数,只有当前一帧的运算完成后,才会将下一帧图像送入模型。当模型推理完成后,我们使用 MediaPipe 提供的一系列计算单元来进行输出的渲染和展示——结合使用 DetectionsToRenderDataCalculator, RectToRenderDataCalculator 及AnnotationOverlayCalculator 将检测结果渲染在输出图像上。
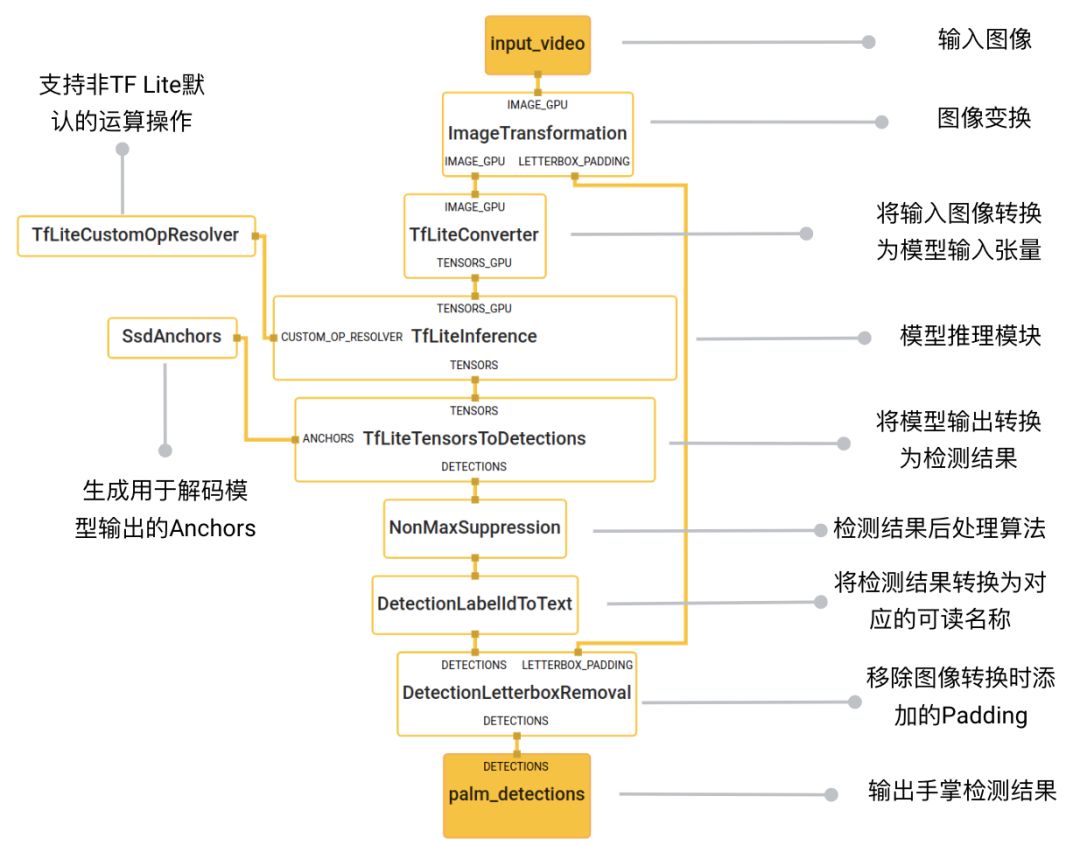
手掌检测应用的核心部分为上图中的蓝紫色模块(HandDetection子图)。如下图所示,HandDetection 子图包含了一系列图像处理的计算单元和机器学习模型推理的模块。ImageTransformationCalculator 将输入的图像调整到模型可以接受的尺寸,用以送入 TF Lite 模型的推理模块;使用 TfLiteTensorsToDetectionsCalculator,将模型输出的 Tensor 转换成检测结果;运用 NonMaxSuppressionCalculator 等计算单元做后处理;最终从HandDetection子图输出检测结果给主图。
致谢:
感谢唐久强,张颿,杨民光, 张倬领及其他 MediaPipe 团队成员。
如果您想详细了解 MediaPipe 的相关内容,请参阅以下文档:
-
https://github.com/google/mediapipe
-
https://mediapipe.readthedocs.io/en/latest/
-
MediaPipe BlazeFace 人脸检测应用
https://github.com/google/mediapipe/blob/master/mediapipe/docs/face_detection_mobile_gpu.md
-
https://github.com/google/mediapipe/blob/master/mediapipe/docs/hand_tracking_mobile_gpu.md
-
https://sites.google.com/corp/view/perception-cv4arvr/hair-segmentation
-
https://github.com/google/mediapipe/blob/master/mediapipe/docs/examples.md
-
MediaPipe 苹果 iOS Hello World! 教程和代码
https://github.com/google/mediapipe/blob/master/mediapipe/docs/hello_world_ios.md
-
MediaPipe 安卓 Hello World! 教程和代码
https://github.com/google/mediapipe/blob/master/mediapipe/docs/hello_world_android.md
-
https://viz.mediapipe.dev
-
MediaPipe Third Workshop on Computer Vision for AR/VR 论文
https://sites.google.com/corp/view/perception-cv4arvr/mediapipe