使用 MediaPipe BlazePose GHUM 和 TensorFlow.js 进行 3D 姿态检测


发布人:Google 的 Ivan Grishchenko、Valentin Bazarevsky、Eduard Gabriel Bazavan、Na Li 和 Jason Mayes
姿态检测是进一步了解视频和图像中人体的一个重要步骤。我们的现有模型支持 2D 姿态检测已经有一段时间了,可能很多人都已试用过。
我们的现有模型
https://github.com/tensorflow/tfjs-models/tree/master/pose-detection
目前,我们发布了 TF.js 姿态检测 API 的第一个 3D 模型。3D 姿态检测为健身、医疗、动作捕捉等应用开启了全新的设计机会。我们发现 TensorFlow.js 社区对以上多个领域越来越感兴趣。在浏览器中通过 3D 动作捕捉来驱动角色动画就是一个很好的案例。

Richard Yee 借助 BlazePose GHUM 实现 3D 动作捕捉
(已获得使用许可,可在 3d.kalidoface.com上查看实时演示版)
此社区演示版使用了由 MediaPipe 和 TensorFlow.js 提供技术支持的多个模型(即 FaceMesh、BlazePose 和 HandPose)。更棒的是,它无需安装任何应用即可在网页中进行体验。有了这些认知后,我们不妨深入了解这个新模型,看看它的实际运用情况。

试用实时演示版
试用实时演示版
https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=blazepose


姿态检测 API 为 BlazePose GHUM 提供了两个运行时,即 MediaPipe 运行时和 TensorFlow.js 运行时。
如需安装 API 和运行时库,您可在 html 文件中使用 <script> 标签或者使用 NPM。
通过脚本标签:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script>
<!-- 如需使用TensorFlow.js 运行时,请通过如下脚本加载 -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script>
<!-- 可选:如需使用MediaPipe 运行时,请通过如下脚本加载。-->
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/pose"通过 NPM:
yarn add @tensorflow-models/pose-detection
# 如需使用 TF.js 运行时,请运行如下命令
yarn add @tensorflow/tfjs-core @tensorflow/tfjs-converter
yarn add @tensorflow/tfjs-backend-webgl
# 如需使用 MediaPipe运行时,请运行如下命令
yarn add @mediapipe/pose
要在 JS 代码中引用 API,具体操作取决于您安装库的方式。
如果是通过脚本标签安装,您可以通过全局命名空间 poseDetection 引用库。
如果是通过 NPM 安装,您需要首先导入库:
import * as poseDetection from'@tensorflow-models/pose-detection';
// 如需使用TF.js运行时,请取消下一行的注释。
// import'@tensorflow/tfjs-backend-webgl';
// 如需使用 MediaPipe 运行时,请取消下一行的注释。
// import'@mediapipe/pose';首先,您需要创建检测器:
const model = poseDetection.SupportedModels.BlazePose;
const detectorConfig = {
runtime: 'mediapipe', // 或者 'tfjs'
modelType: 'full'
};
detector = await poseDetection.createDetector(model, detectorConfig);您可从 lite、full 和 heavy 三个选项中进行选择一个适合您应用需求的 modelType。从 lite 到 heavy,准确率递增,但推断速度递减。请尝试我们的实时演示版来比较不同配置间的差异。
实时演示版
https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=blazepose
有了检测器后,您就可以传入视频串流以检测姿态:
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);如何使用输出?poses 代表了图像帧中检测到的 pose 预测数组。每个 pose 中都包含 keypoints 和 keypoints3D。keypoints 与我们之前发布的 2D 模型相同,它是一个由 33 个关键点对象组成的数组,每个对象都有以像素为单位的 x、y 轴。
keypoints3D 是另一个包含 33 个关键点对象的数组,每个对象都有 x、y、z 轴。x、y、z 轴均以米为单位。对人体进行建模,假设该模型位于一个 8 立方米的立方型空间中。每个轴的范围为 -1 到 1(因此总增量为 2 米)。该 3D 空间的原点是臀部中心 (0, 0, 0)。从原点出发,如果靠近摄像头,则 z 轴的值为正,如果远离摄像头则为负。请查看下面的输出片段示例:
[
{
score: 0.8,
keypoints: [
{x: 230, y: 220, score: 0.9, name: "nose"},
{x: 212, y: 190, score: 0.8, name: "left_eye"},
...
],
keypoints3D: [
{x: 0.5, y: 0.9, z: 0.06 score: 0.9, name: "nose"},
...
]
}
]了解有关此 API 的更多详情,您可以参阅我们的 ReadMe。
ReadMe
https://github.com/tensorflow/tfjs-models/tree/master/pose-detection
如果您开始使用 BlazePose GHUM 进行操作和开发,我们将非常期待您的反馈和贡献。如果您使用此模型进行构建,请在社交媒体上为您的作品加上 #MadeWithTFJS 标签,以便我们找到您的作品,我们非常期待看到您亲手打造的佳作。
反馈
https://github.com/tensorflow/tfjs/issues/new
贡献
https://github.com/tensorflow/tfjs-models/pulls
构建姿态模型 3D 部分的主要挑战在于获取自然环境中的真实 3D 数据。与可通过人工注释获取的 2D 注释相比,精准的 3D 人工注释可谓是一项独特的挑战。这种注释需要实验室设备或带有深度传感器的专业硬件来进行 3D 扫描,这为在数据集中保持良好的人体和环境多样性带来了额外的挑战。许多研究人员选择的另一种方法是构建一个完全合成的数据集,这又引入了另一种挑战,即针对现实世界图片的领域适应性。
我们的方法是使用一个名为 GHUM 的统计学 3D 人体模型,该模型通过人体形状和运动的大型语料库进行构建。为了获取 3D 人体姿态的实际结构,我们将 GHUM 模型与我们现有的 2D 姿态数据集进行拟合,并在度量空间中用现实世界的 3D 关键点坐标对其进行扩展。在拟合过程中,GHUM 的形状和姿态变量进行优化,从而让重建的模型与图像证据相一致。其中包括 2D 关键点和轮廓的语义分割对齐,以及形状和姿态的正则化。更多详情请参阅有关 3D 姿态和形状推断的研究(HUND、THUNDR)。
HUND
https://openaccess.thecvf.com/content/CVPR2021/papers/Zanfir_Neural_Descent_for_Visual_3D_Human_Pose_and_Shape_CVPR_2021_paper.pdf
THUNDR
https://arxiv.org/pdf/2106.09336.pdf

输入图像的 GHUM 拟合示例。从左到右:原始图像、3D GHUM 重建(不同的视角)和投影在原始图像上方的混合结果
由于 3D 到 2D 投影 (3D projection) 的性质,3D 中的多个点在 2D 中可以有相同的投影(即 X、Y 轴相同,但 Z 轴不同)。因此,对于指定的 2D 注释来说,拟合的结果可能是几个真实的 3D 人体姿态。为尽量减少这种模糊性,除了 2D 人体姿态外,我们还要求注释者提供准确的姿态骨架边缘之间的深度顺序(查看下图)。事实证明,与真正的深度注释相比,这项任务十分简单。其显示注释者之间存在高度一致性(交叉验证的一致性为 98%),并有助于将拟合 GHUM 重建的深度排序误差从 25% 减少到 3%。

“深度顺序”注释:较宽的边角表示离摄像头较近的角落(例如,在两个示例中,人的右肩比左肩更靠近摄像头)
BlazePose GHUM 采用了两步检测器-追踪器方法,追踪器在裁剪过的人体图像上进行操作。因此,该模型训练用于预测 3D 人体姿态,用度量空间的相对坐标表示,原点在受试者的臀部中心。
两步检测器-追踪器
https://blog.tensorflow.google.cn/2021/05/high-fidelity-pose-tracking-with-mediapipe-blazepose-and-tfjs.html
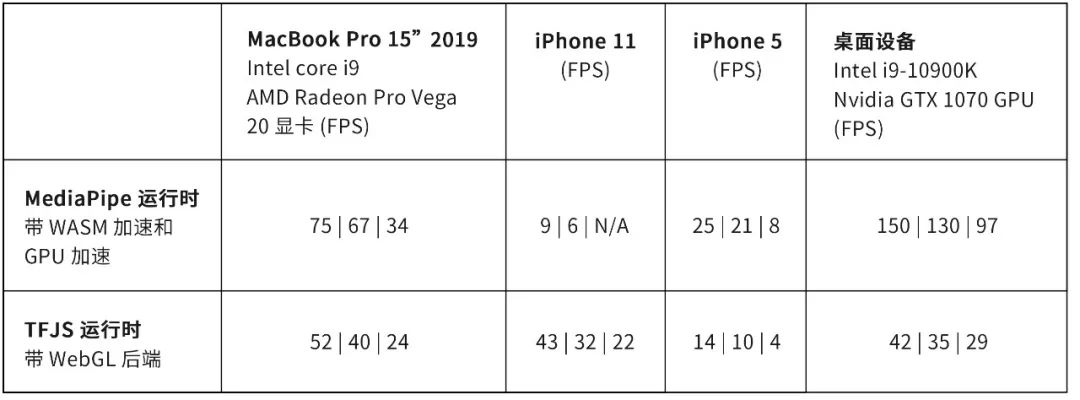
使用每种运行时都有优点和缺点。如下面的性能表所示,MediaPipe 运行时在桌面设备、笔记本电脑和 Android 手机上的推断速度较快。TF.js 运行时在 iPhone 和 iPad 上的推断速度较快。TF.js 运行时也比 MediaPipe 运行时小了大约 1 MB。
我们要对参与创建 BlazePose GHUM 3D 的同事们表示感谢:Andrei Zanfir、Cristian Sminchisescu、Tyler Zhu,以及 MediaPipe 的其他贡献者:Chuo-Ling Chang、Michael Hays、Ming Guang Yong、Matthias Grundmann,以及参与构建 TensorFlow.js 姿态检测 API 的人员:Ahmed Sabie 和 Ping Yu,当然还有利用这些模型创作优秀作品的社区成员:Richard Yee。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




