错看一头大象后,这个AI“疯了”!

作者 | 琥珀
出品 | AI科技大本营(公众号ID:rgznai100)
在一项新的研究中,计算机科学家发现,人工智能无法通过儿童可轻松完成的“视力检测”。

“这是一项聪明且重要的研究,它提醒我们所谓的‘深度学习’并非想象中的那么‘深’”,纽约大学神经科学家 Gary Marcus 表示。
在计算机视觉领域,人工智能系统会尝试识别和分类对象。他们可能会试图在街景中找到所有行人,或者只是将鸟与自行车区分开。要知道,这也是一项非常艰巨的任务,其背后的风险系数很高。随着计算机开始接管自动监控和自动驾驶等关键业务,我们会愈加希望它们的视觉处理能力与人眼一样好。
但这并不容易。这项研究任务突出了人类视觉的复杂性,以及构建模仿系统的挑战。期间,研究人员向计算机视觉系统展示了一幅客厅的场景,系统正确地识别了椅子、人和书架上的书。然后,研究人员在场景中引入了一个异常物体:一张大象的图像。接着,“恐怖”事件开始上演。
大象的存在导致系统忘记了自己。突然间,这个 AI 系统开始将椅子称为沙发,大象称为椅子,并完全忽略了它之前看到的其他物体。
“各种奇怪事件的发生,表明当前物体检测系统时多么得脆弱,”多伦多约克大学的研究员 Amir Rosenfeld 表示,他和他的同事 John Tsotsos 和 Richard Zemel 共同撰写了这项研究。
研究人员仍然想弄清楚为什么计算机视觉系统会如此脆弱。他们猜测 AI 缺乏人类那种从容处理海量信息的能力:当对某一场景产生困惑时,会再回过头重看一遍。
▌难以直面的“房中大象”
人类,只要睁大眼睛,大脑就会快速的收集、加工这些视觉信息。
相比之下,人工智能会非常费力地制造视觉印象,就好像它是用盲文阅读描述一样。不同的算法,人工智能产生了不同的表达效果。在此过程中,特定类型的 AI 系统被称为神经网络。它通过一系列“层”来传递图像。在每一层,图像细节如像素的颜色和亮度,被替换成了越来越抽象的描述。结束时,神经网络会对其正在观察的内容产生最佳猜测。
“通过获取前一层的输出,处理并将其传递到下一层,就像管道一样,都从一层移动到另一层,”Tsotsos 说。
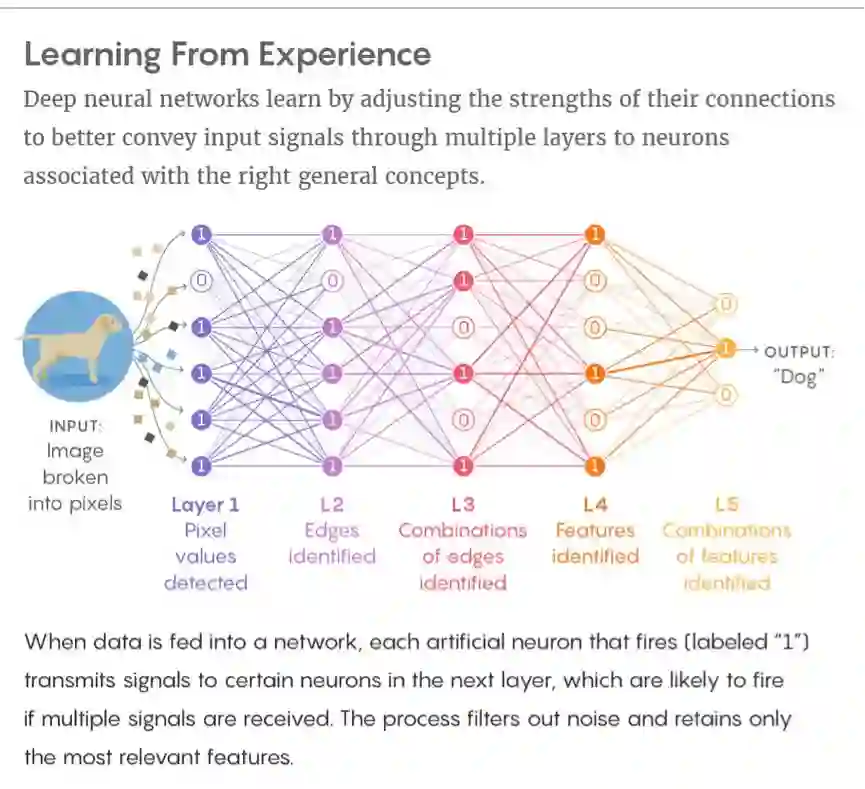
在这个过程中,神经网络擅长特定视觉事物的判断,如将物体进行类别分配。这些成果激起了人们的期望,甚至期待它们可以很快应用在城市车辆的驾驶系统中。
这项新研究具有相同的精神。三位研究人员为神经网络提供了一个客厅场景:一个坐在破旧椅子边缘的男子在玩视频游戏时向前倾斜。看过这个场景之后,神经网络正确检测到了许多具有高可信度的物体:人、沙发、电视、椅子、书籍。如下(a)图。

在(a)图中,神经网络以高概率正确识别出了杂乱的起居室场景中的许多项目。(f)图中添加了一只大象的侧身像,系统便出现了问题。左下角的椅子变成了沙发,附近的杯子消失,大象被误以为是椅子。在其他情况下,系统忽略了在此前试验中正确检测到的物体。甚至将大象从图片中移除后,也会发生这些错误。
“如果房间里真的有一头大象,那么你可能会注意到它。”“该系统甚至没有检测到它的存在。” Rosenfeld 说道。
论文中研究人员总结道:
识别是不稳定的:物体可能偶尔无法被检测到,或者在环境不经意间快速改变后才能检测到。
被识别目标的标记并非一致:根据不同的位置,目标可能会被识别为不同的类别。
被识别目标引起了非局部影响:与该目标不重叠的对象可切换标记、边框,甚至完全消失。
这些结果是图像识别中的常见问题。通过用包含训练对象的图像替换另一个图像的子区域而获得,这称之为“目标移植”。以这种方式修改图像对识别具有非局部影响。细微的变化会影响目标检测工具的识别效果。
▌为什么就不能“反思”?
当人类看到意想不到的的东西时,会反复思考。这是一个具有真实认知意义的常见现象,而这恰恰解释了为什么当场景变得怪异时,神经网络就会崩溃。
如今用于物体检测的最佳神经网络主要以“前馈”的方式工作。这意味着信息穿过神经网络时只有一个方向。它们从细粒度像素的输入开始,然后移动到曲线、形状和场景,神经网络对每一步看到的物体做出最优预测。因此,当神经网络汇集它认为知道的所有内容并进行猜测时,早期错误的观察会最终影响整个预测的效果。
设想一下,如果是让人类看到一幅包含了圆形和正方形的图像,其中一个图形为蓝色,另一个为红色。可能一眼并不能足以看清二者的颜色。但关键的是,当人类第二次看时,就会将注意力集中在方块的颜色上。
“关于人类的视觉系统,‘我还没有正确的答案,所以我必须返回去看看在哪里犯了错误’,” Tsotsos 解释道。他通过一个叫做 Selective Tuning 的理论(http://www.cse.yorku.ca/~tsotsos/Selective_Tuning/Selective_Tuning.html)来解释这个视觉认知特征的问题。
大多数神经网络缺乏这种反向能力。对于工程师们如何构建这种特质亦是困难。前馈神经网络的优势在于——通过相对简单的训练即可进行预测。
但如果神经网络要获得这种反复思考的能力。他们需要熟练掌握合适利用这种新能力,以及何时以前馈方式向前推进的能力。人脑可在这些不同的过程之间无缝切换,而神经网络需要一个新的理论框架才能做同样的事情。
一篇评论引发的讨论
其实,该项研究论文早于上月就已公开发表,但让大家得到关注的却是因为《量子杂志》专栏作者 Kevin Hartnett 的一篇评论 “ Machine Learning Confronts the Elephant in the Room” 所传递出的强烈观点。

对此,许多读者表达了自己的看法。

机器学习将会遭遇成长的痛苦……

这篇文章很有趣,但它没有说清楚该系统是否具有大象的概念(另外我认为严重裁剪像素化的大象不应算数。)
考虑到透视和照明,将豆袋称为沙发,然后是椅子,这就足够了。
所有与 AI 相关的“问题”似乎与它们的实际编码有关系。当 AI 有80%的的确定性时,人们倾向于认为这很好,而人类很少能达到这样的准确性:要么是 100% 确定(但有可能是错的),要么是 50% 的准确性甚至完全不清楚。
这就是人类会做的事情,记住物体X和Y的特征,虽然很难在特定的图像中分辨出来,但还是尽可能通过更清晰的图片核实真伪。

你可以进行简单的思考实验,看看人脑在分析图像时做了什么。首先,当我看一个场景时,我一定是对几何有所了解的。无论意义、文字、符号如何,我都可以追溯到事物的三维形状,这些是与文字无关的。
其次,我可以通过看到大象的外观模型,与“大象”这个词联系起来。我不需要颜色或细节就知道它是大象。事实上,仅凭颜色和细节,我还是很难识别出大象。
(假设我们基于大象的真实图片训练了一款神经网络)如果你将大象的白色雕塑(图片)拿给神经网络识别,那么它很可能不会输出“大象”这个词。但如果你给出一个大象的真实图片进行识别,那它可以正确识别大象。
由于大象的白色雕塑与实际图片之间的差异只是颜色等细节,这表明当训练深度学习网络识别大象时,训练的是细节(包括颜色、像素、甚至斑点),而不是三维模型……这种方式正好与人类认知相反。这是一种过度拟合的形式,单纯训练不足以帮助学习网络捕捉几何规律。我敢打赌,如果你用大象的特写照片用来训练网络,那么它在识别方面将做得更好。
我猜测:我们的思维具有特定的和遗传决定的内置几何识别算法,可以将 2D 图像转换为 3D 形状。虽然多数情况下我们专注于研究的机器学习是图像识别,但我相信大脑实际上是学习形状和几何识别的。
▌写在最后
本文开头我们引述了纽约大学神经科学家 Gary Marcus 的评价:“深度学习”并非我们想象中的那么“深”。想起此前海内外在内的不少学者专家也都曾表示,深度学习虽然引起了人工智能的新一股热潮,但深度学习并非万能,在它之外仍有很多的研究内容值得关注。
参考链接:https://arxiv.org/abs/1808.03305
--【完】--
CSDN学院《AI工程师》直通车来了!目标是通过120天的学习(线上)让你成为一名不亚于业界水平的AI工程师!
你将收获: 第一阶段:机器学习原理及推荐系统实现;第二阶段:深度学习原理及实战项目强化训练;第三阶段:四个工业级实战项目及成果展示