比FAST更快!TX2上跑1000FPS!高速VIO特征 | 基于GPU前端加速的增强型特征检测器
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者团队:苏黎世大学& ETH Zurich
代码:https://github.com/uzh-rpg/vilib
引言
本文贡献:
首先回顾了专门针对GPU进行特征检测的非极大值抑制问题,并提出了一种选择局部最大响应,施加空间特征分布并同时提取特征的解决方案。
第二个贡献是引入了一种增强的FAST特征检测器,该检测器应用了上述非极大值抑制方法。
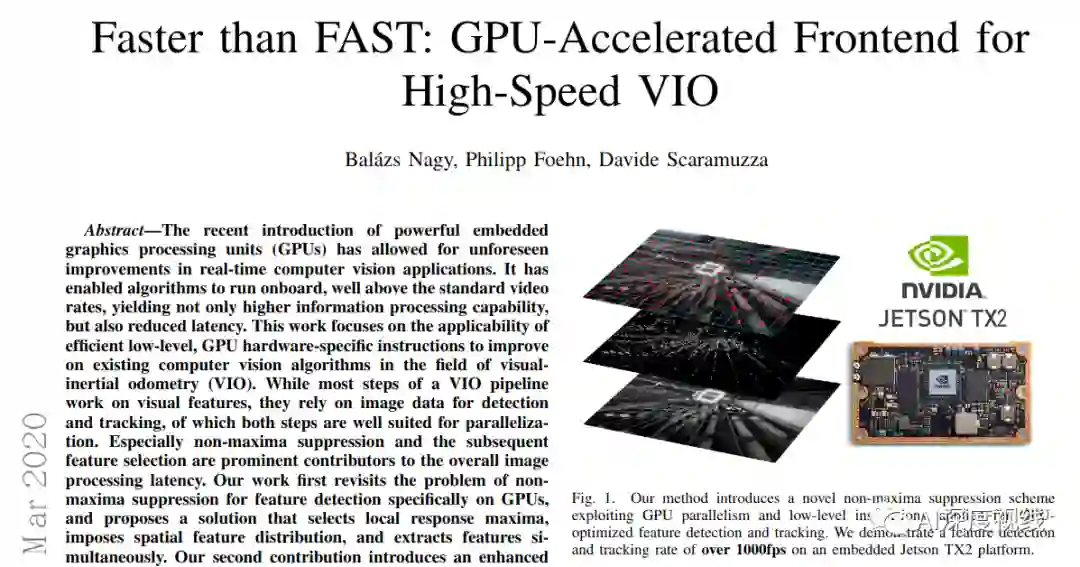
最后,与其他最新的CPU和GPU实现进行了比较,在特征跟踪和检测方面始终优于所有其他实现,从而在嵌入式Jetson TX2平台上实现了超过1000 FPS。此外,我们展示了我们的工作已集成到VIO管道中,以约200fps的速度实现了姿态评估。
问题
-
延迟
-
计算能力
-
第一种使用带有数字信号处理器(DSP)的中央处理器(CPU),因此限制了任务集;
-
第二个结合了一个CPU和可编程序逻辑(e.g.FPGA),这是多才多艺但增加开发时间;
-
第三种解决方案是一个CPU与GPU的结合,这不仅是合算的,还擅长图像处理任务由于GPU为高度并行的建造任务。
主要思路

3.1 并行化简介
-
CUDA允许开发人员卸载中央处理单元,将任务传给GPU,甚至用于非图像相关计算。
-
NVIDIA GPU体系结构是围绕可扩展的多线程流式多处理器(SM)阵列构建的。每个SM都有大量的流处理器(SP),又称为CUDA内核。
-
GPU通常每个SM具有1-20个流多处理器和128-256个流处理器。
-
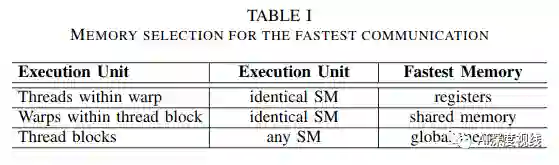
除了处理核心之外,还有各种类型的可用内存(按与处理核心的接近程度排序):寄存器文件,共享内存,各种高速缓存,片外设备和主机内存。
NVIDIA的GPGPU执行模型引入计算单元的层次结构: 线程,线程束,线程块和线程网格 。
-
最小执行单位是线程。
-
多个线程组成线程束:每个线程束包含32个线程。
-
线程束进一步组成线程块。
-
最后是线程网格,线程网格是线程块的数组。线程网格中的线程块彼此独立执行。
3.2 特征检测器概述
为了进行特征检测:
(2) 对于每种图像分辨率,通常在每个像素处评估两个函数:粗角响应函数(CCRF) 和角响应函数(CRF)。
注:CCRF是一种快速评估,可以迅速排除大多数候选者,因此速度较慢的CRF功能仅接收通过首次验证的候选者。一旦在ROI内评估了每个像素,便会应用非最大值抑制来仅选择局部最大值。

为了满足这一要求,引入了二维网格单元的概念:
将图像划分为具有固定宽度和高度的矩形
在每个单元中,只有一个特征被选中-该特征的CRF得分在该单元中最高
这种方法不仅将特征均匀地分布在图像上,而且还对提取的特征计数施加了上限。
3.3 CUDA的非极大值抑制
单元内的特征选择可以理解为归约操作,其中仅选择具有最大分数的特征。此外,邻域内的非最大值抑制也可以视为一种归约操作,可以减少对有限邻域内的单个像素位置的角点响应。
作者将角点响应图分为规则的单元格网格。为了简化说明,在32x32单元中使用了1:1的warp-to-cell映射。
-
wrap读取单元格的第一行 时,wrap内的每个线程都获得了一个像素响应。 -
整个wrap开始邻域抑制 :每个线程都验证其响应是否在其摩尔邻域内达到最大值。邻域验证完成后,一些线程可能会抑制其响应。 -
wrap继续到下一行,并重复之前的操作 。线程将在所有单元格中继续执行此操作,直到处理完整个单元格为止。
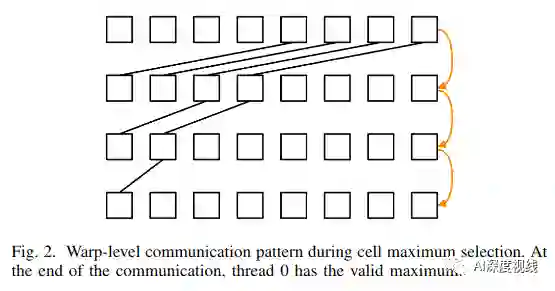
为了加快还原速度,多个warp处理一个单元,因此,在warp级别减少之后,共享内存中的最大值将减少。一旦线程块中的所有warp将其最大结果(分数,x-y位置)写入其指定的共享内存区域,则该块中的第一个线程将为每个单元选择最大值并将其写入全局内存,从而完成该单元的处理。
3.4 FAST特征检测器
FAST角点检测方法比较基础,这里不再赘述,可以归结为下式:
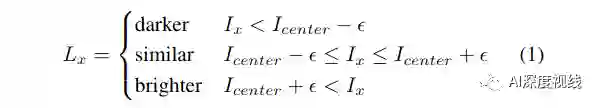
FAST中避免计算散度
如果每个线程在NVIDIA单指令多线程(SIMT)执行模型中执行(1)的比较,则if/else指令中的比较将执行不同的代码块。由于所有线程都在wrap中执行同一条指令,因此某些线程在if分支期间处于非活动状态,而其他线程在else分支期间处于非活动状态。这称为代码发散,会显著降低并行化的吞吐量。
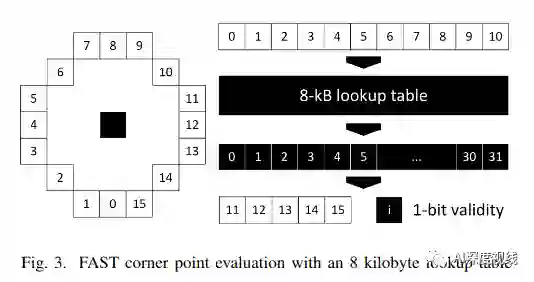
作者的方法是将16个比较的结果存储为一个位数组,用作查找表的索引。预先计算了所有可能的16位向量。由于所有2^16个向量的结果都是二进制的,因此结果可以存储在2^16位(即8KB)中。可以使用4字节整数存储这些结果,每个整数存储32个组合。该表的缓存命中率高于以前的方法,改善了延迟问题。
3.5 Lucas-Kanade特征跟踪器
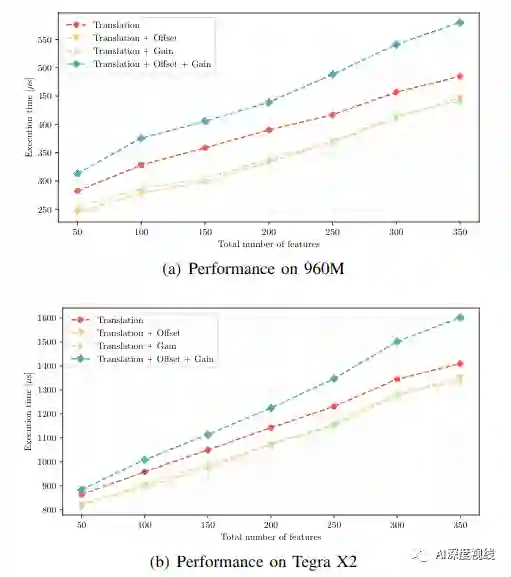
作者的方法是将金字塔逆合成Lucas-Kanade算法部署为特征跟踪器。逆合成算法是一种扩展,通过允许预先计算海森矩阵并在每次迭代中重用它,改进了每次迭代的计算复杂度。同时逆合成的Lucas-Kanade增加了仿射光照变化的估计。
该算法能够将多个金字塔级别上每个要素周围的矩形邻域中的光度学误差最小化。但是,
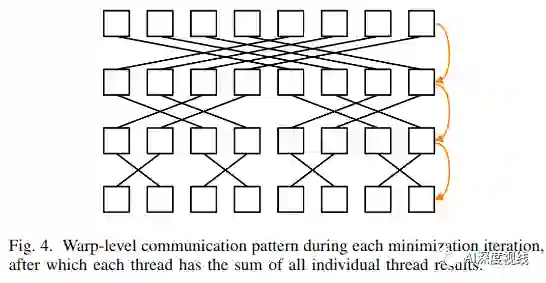
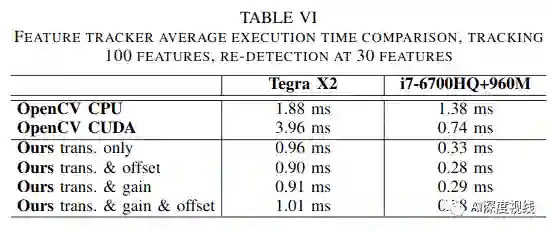
该方法的新颖之处在于线程到功能的分配。以前提出的方法使用的是一对一分配,这意味着只有较大的特征数才能使用大量线程。这会对功能计数较小的GPU上的延迟隐藏产生不利影响,这通常适用于VIO。作者的方法通过使wrap协同解决特征补丁来加快算法的速度,减少了每个线程的工作量,同时使用了最快的通信介质。
实验及结果
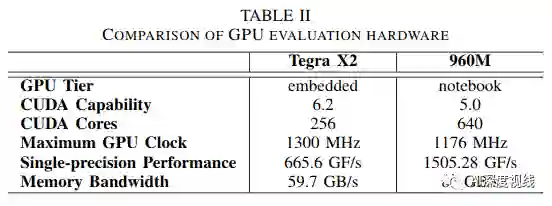
硬件
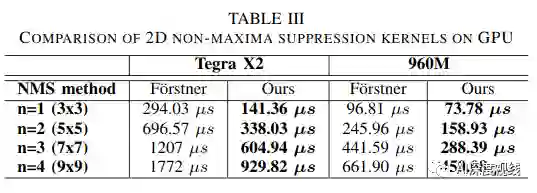
非极大抑制
特征检测器

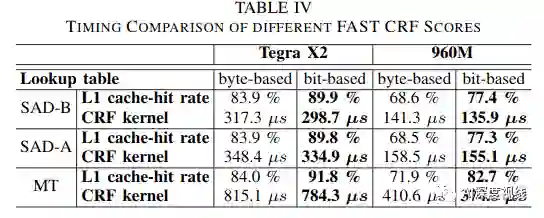
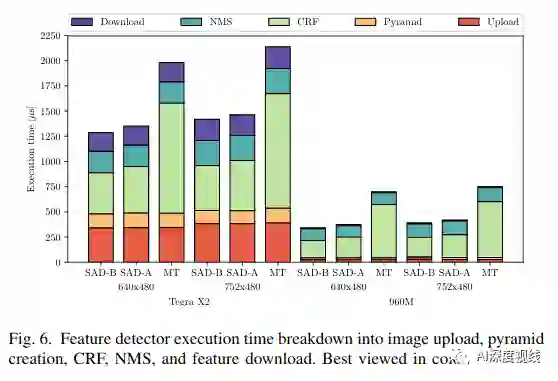
特征跟踪
视觉里程计 VIO
在嵌入式Jetson TX2平台的多个数据集上实现∼200fps。

重磅!CVer-SLAM 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-SLAM 微信交流群,目前已汇集750人!涵盖SLAM、VSLAM、视觉里程计等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如SLAM+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


