点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
作者:罗璇、Jia-Bin Huang等
本文转载自:机器之心 | 参与:魔王、张倩
还记得那个用论文外观判断论文质量的
研究吗?在那份研究中,身为顶会领域主席的作者 Jia-Bin Huang 被自己开发的系统拒了稿,引来了大批社区成员的围观。最近,他和合作者提出了一项新的计算机视觉方法,可以让厨房「水漫金山」,让天空下起「彩球雨」……
![]()
![]()
![]()
不止如此,想要猫主子不嫌弃自己拍的丑丑视频,这个方法也能拯救你!
![]()
这项研究由来自华盛顿大学、弗吉尼亚理工学院和 Facebook 的研究者合作完成。
其中第一作者罗璇现为华盛顿大学现实实验室博士,她本科毕业于上海交通大学,导师为卢宏涛教授,研究方向为立体匹配,曾在新加坡国立大学跟随颜水成钻研深度学习。
![]()
第二作者 Jia-Bin Huang 为弗吉尼亚理工学院助理教授,研究方向为计算机视觉、计算机图形学和机器学习。曾担任 WACV 2018、CVPR 2019、ICCV 2019、BMVC 2019 和 BMVC 2020 会议的领域主席。
这项研究主要探究了如何生成准确度和几何一致性更高的视频重建结果,目前该论文已被计算机图形学顶级会议 SIGGRAPH 2020 接收,代码也将在未来开源。
基于图像序列进行 3D 场景重建在计算机视觉社区中已有几十年的研究历史。毋庸置疑,最简单的 3D 重建捕捉方式就是利用智能手机手持拍摄,因为这类相机很常见,还可以快速覆盖很大的空间。如果可以利用手机拍摄的视频实现非常密集、准确的重建,这类技术将变得非常有用。但要做到这一点困难重重。
除了重建系统都要处理的典型问题,如纹理单一区域、重复图案和遮挡,基于手机拍摄的视频实现重建还面临着来自视频本身的额外挑战,如较高的噪声水平、抖动和动态模糊、卷帘快门变形,以及移动对象(如人)的出现。
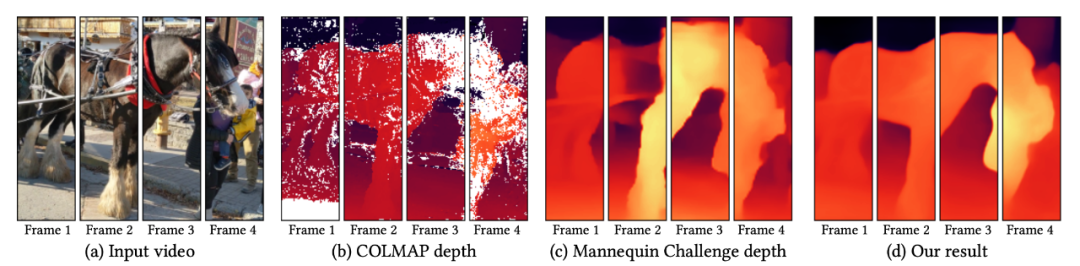
出于这些原因,现有的方法通常会遇到很多问题,如深度图中有缺失区域(见下图 b),几何和闪烁深度不一致(见下图 c)。
![]()
这篇论文提出了一种新的 3D 重建算法,可以重建单目视频中所有像素的密集、几何一致性深度。他们利用传统的 structure-from-motion(SfM)方法来重建像素的几何约束。
![]()
与传统重建方法使用特殊先验的做法不同,
该研究使用的是基于学习的先验,即为单图像深度估计训练的卷积神经网络
。在测试时,他们微调了这个网络,来满足特定输入视频的几何约束,同时保留其为视频中受约束较少的部分合成合理深度细节的能力。
定量验证结果表明,与之前的单目重建方法相比,该方法可以达到更高的准确度及几何一致性。从视觉上看,本文提出的方法也更加稳定。该方法可以处理具有中等程度晃动的手持拍摄视频,可以应用到场景重建以及基于视频的高级视觉效果。
但该方法的局限在于算力消耗太大,因此暂时无法用在实时的 AR 场景中。不过,论文作者也表示,会将速度的提升作为下一步的研究目标。
![]()
![]()
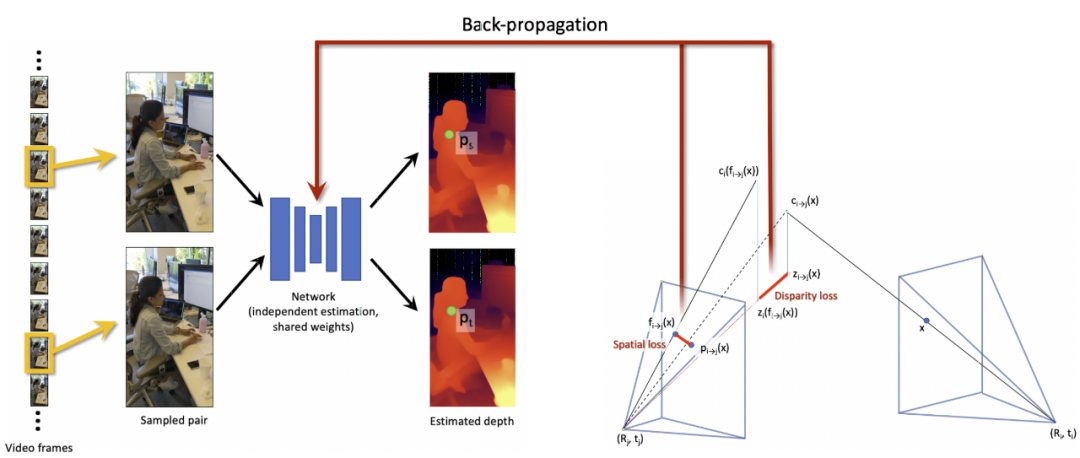
如上图 2 所示,该方法以单目视频作为输入,目的是估计相机位姿以及每个视频帧的深度和几何一致性深度图。「几何一致性」不仅意味着深度图不会随着时间的推移而闪烁(flicker),还意味着所有的深度图都是彼此一致的。也就是说,我们可以利用像素深度和相机位姿在帧与帧之间准确地投影这些像素。例如,一个静态点的所有观察结果都应该映射到世界坐标系中一个单独的普通 3D 点上,且没有漂移(drift)。
随意捕获的输入视频为深度重建增加了一些挑战。由于它们大多是手持拍摄的,相机也没有经过标定,因此经常出现动态模糊、卷帘快门变形等问题。简陋的光照条件也会造成额外的噪声及模糊。而且,这些视频通常包含动态移动的对象(如人或动物),而很多重建系统是专为静态场景设计的,这就形成了一个大的冲突。
在有问题的场景部分,传统的重建方法通常会生成「孔洞」(如果强制返回结果,会估计出噪声非常大的深度)。但在这些方法对返回结果比较有信心的部分,它们通常会返回非常准确且一致的结果,因为它们严重依赖几何约束。
近期基于学习的方法弥补了这些缺陷,它们利用一种数据驱动的强大先验来预测输入图像的合理深度。然而,对每一帧单独应用这些方法会导致几何不一致和短暂的闪烁。
本文作者提出的方法结合了以上两种方法的优点
。研究者利用了几种现成的单图像深度估计网络,这些经过训练的网络可以合成一般彩色图像的合理深度。他们利用从视频中借助传统重建方法提取的几何约束来微调网络。因此,该网络学会在特定视频上生成具有几何一致性的深度。
该研究首先使用开源软件 COLMAP 执行传统的 SfM 重建流程。
为了改善对动态运动视频的姿势估计,研究者使用 Mask R-CNN 来获取人物分割结果,并移除这些区域以获得更可靠的关键点提取和匹配结果,因为视频中的动态运动主要来自于人物。这一步可以提供准确的内部和外部相机参数,以及稀疏点云重建。
研究者还利用光流估计了视频帧对之间的稠密对应关系。相机标定(camera calibration)和稠密对应共同构成了几何损失。
在这一阶段,研究者微调预训练深度估计网络,使其生成对特定输入视频更具几何一致性的深度。
在每次迭代中,该方法使用当前的网络参数采样一对视频帧并估计其深度图。然后对比稠密一致性和利用当前深度估计结果得到的重投影,从而验证深度图是否具备几何一致性。
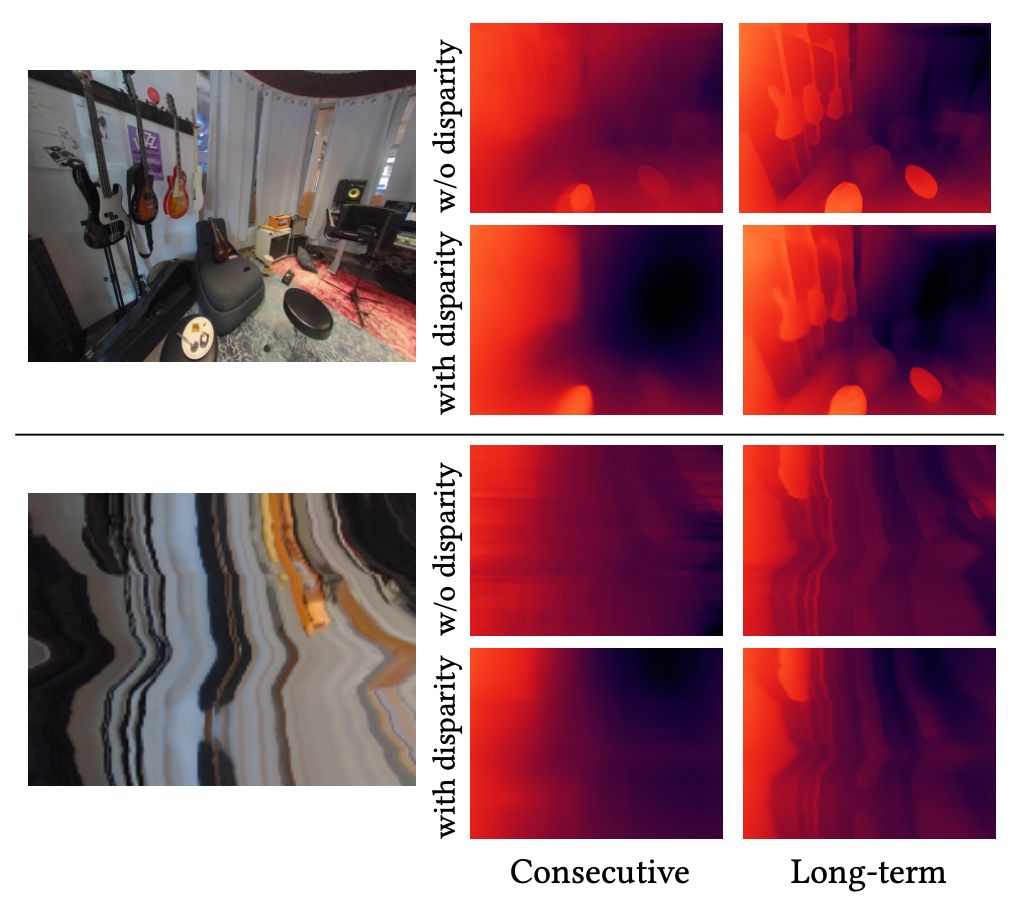
最后,研究者评估了两种几何损失:空间损失和视差损失,并将误差进行反向传播,以更新网络权重(权重对所有帧共享)。
用这种方式迭代地采样很多对视频帧,损失得到降低,网络学会估计具备几何一致性的深度,同时能够在约束较少的部分提供合理的正则化。
该方法得到的改进通常很大,最终深度图具备几何一致性,与整个视频的时序一致,且能够准确勾勒出清晰的遮蔽边界,即使是对于运动物体也是如此。有了计算得到的深度之后,研究者就可以为遮挡效应(occlusion effect)提供合适的深度边界,让真实场景的几何与虚拟事物进行交互。
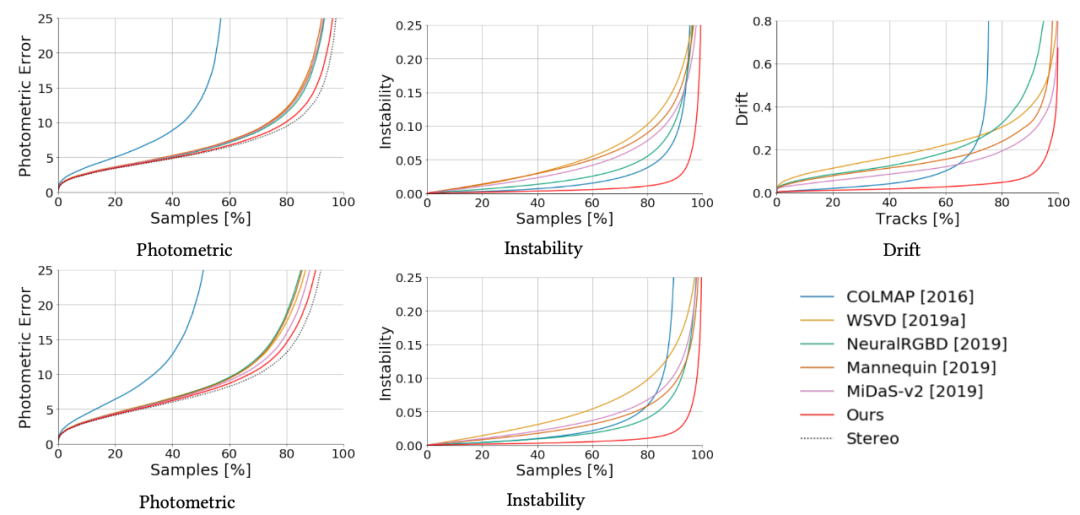
研究者对比了当前最优的深度估计算法,这些算法分为三个类别:
传统的多视角立体视觉系统:COLMAP [Schonberger and Frahm 2016];
单幅图像深度估计:Mannequin Challenge [Li et al. 2019] 和 MiDaS-v2 [Ranftl et al. 2019];
基于视频的深度估计:WSVD [Wang et al. 2019a](两帧)和 NeuralRGBD [Liu et al. 2019](多帧)。
![]()
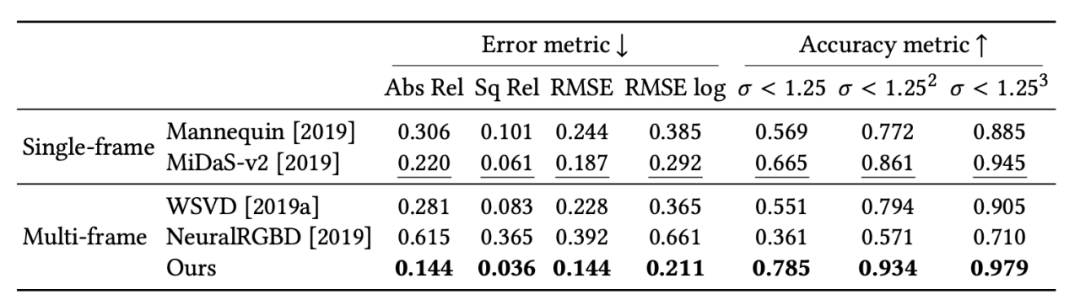
图 4:该研究提出的方法与 SOTA 方法的量化对比结果。
![]()
该研究提出的方法可以从手机摄像头随意拍摄的视频中生成具备几何一致性且没有颤动的深度估计结果。
![]()
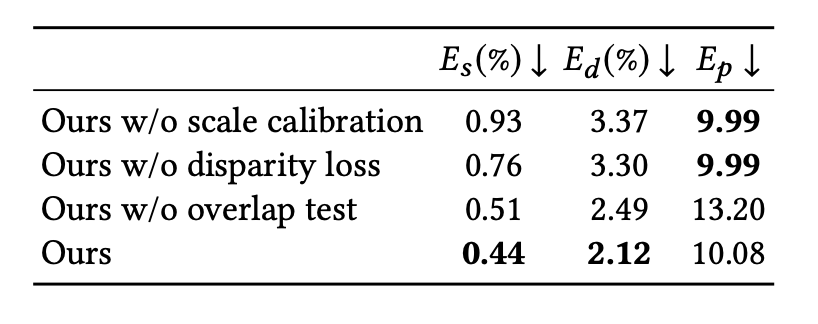
表 2:控制变量研究。该量化评估结果表明该方法的设计重要性。
![]()
![]()
![]()
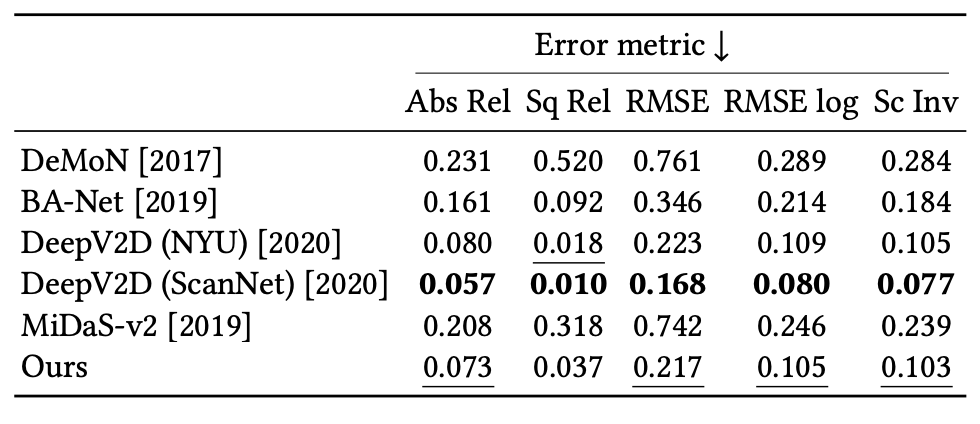
表 3:在 ScanNet 数据集上的量化对比结果。
![]()
表 4:在 TUM-RGBD 数据集上的量化对比结果。
![]()
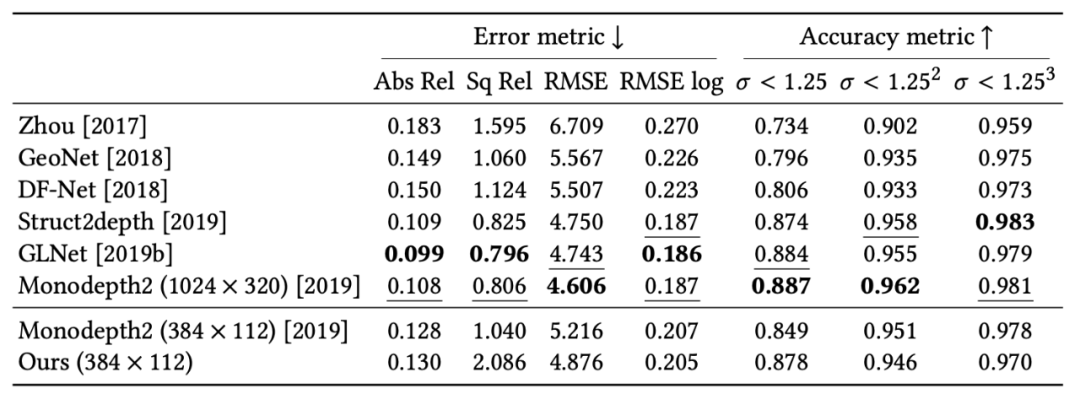
表 5:在 KITTI 基准数据集上的量化对比结果。
作者在论文中提到了该方法的四项局限之处,分别是位姿、动态运动、光流和速度。
该方法目前依赖 COLMAP,来基于单目视频估计相机位姿。而在难度较大的场景中,如相机平移有限及动态模糊的情况下,COLMAP 可能无法生成靠谱的稀疏重建结果和相机位姿估计。
较大的位姿误差也会对该方法的输出结果造成极大的负面影响,因此这限制了该方法在此类视频中的应用。
将基于学习的位姿估计和该研究提出的方法结合起来,或许是一个不错的研究方向。
该方法支持包含温和运动的视频,但如果运动较为激烈则该方法会出现问题。
该方法依赖 FlowNet2 来构建几何约束。使用前后向传播一致性检查并过滤掉不可靠的光流,但这也可能出现错误。这时该方法无法输出正确的深度。研究者尝试使用稀疏光流,但效果并不好。
该方法利用视频中所有帧提取几何约束,因此不支持在线处理。例如,对于一个包含 244 帧、708 个采样光流对的视频来说,该方法的测试时训练步耗时约 40 分钟。
此外,作者还制作了一个简短的视频,介绍了该研究的主要方法、思路和效果,参见:
重磅!CVer-深度估计 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-深度估计 微信交流群。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如深度估计+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
请给CVer一个在看!![]()