理解神经网络:从神经元到RNN、CNN、深度学习

本文为 AI 研习社编译的技术博客,原标题 :
Understanding Neural Networks. From neuron to RNN, CNN, and Deep Learning
作者 | vibhor nigam
翻译 | gezp123、Dylan的琴
校对 | 邓普斯•杰弗 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/understanding-neural-networks-from-neuron-to-rnn-cnn-and-deep-learning-cd88e90e0a90
注:本文的相关链接请访问文末【阅读原文】

神经网络是目前最流行的机器学习算法之一。随着时间的推移,证明了神经网络在精度和速度方面,比其他的算法性能更好。并且形成了很多种类,像CNN(卷积神经网络),RNN,自编码,深度学习等等。神经网络对于数据科学和或者机器学习从业者,就像线性回归对于统计学家一样。因此,对神经网络是什么有一个基本的理解是有必要的,比如,它是怎么构成的,它能处理问题的范围以及它的局限性是什么。这篇文章尝试去介绍神经网络,从一个最基础的构件,即一个神经元,深入到它的各种流行的种类,像CNN,RNN等。
神经元是什么?
正如其名字所表明,神经网络的灵感来源于人类大脑的神经结构,像在一个人类大脑中,最基本的构件就叫做神经元。它的功能和人的神经元很相似,换句话说,它有一些输入,然后给一个输出。在数学上,在机器学习中的神经元就是一个数学函数的占位符,它仅有的工作就是对输入使用一个函数,然后给一个输出。
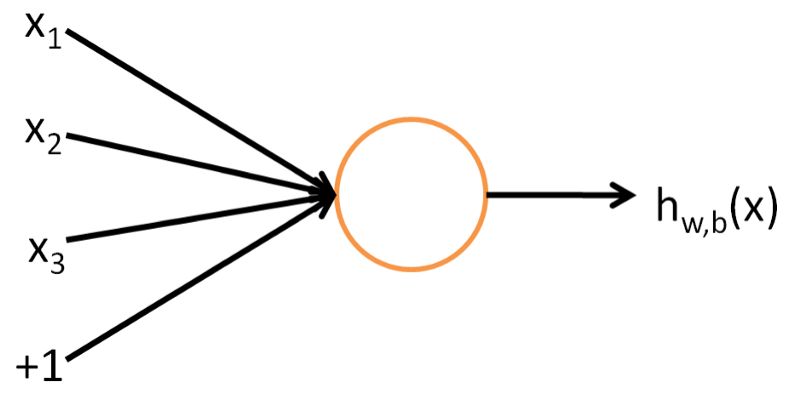
这种神经元中使用的函数,在术语上通常叫做激活函数。主要的激活函数有5种,date,step,sigmoid,tanh和ReLU。这些都将在接下来进行详细地描述。
激活函数
阶跃函数
阶跃函数定义为
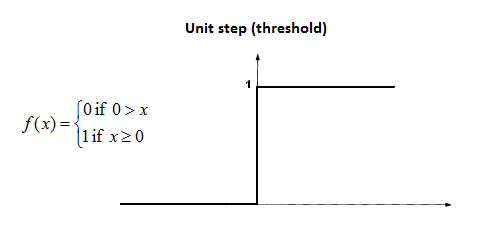
其中,如果x的值大于等于零,则输出为1;如果x的值小于零,则输出为0。我们可以看到阶跃函数在零点是不可微的。目前,神经网络采用反向传播法和梯度下降法来计算不同层的权重。由于阶跃函数在零处是不可微的,因此它并不适用于梯度下降法,并且也不能应用在更新权重的任务上。
为了克服这个问题,我们引入了sigmoid函数。
Sigmoid函数
一个Sigmoid函数或者logistic函数的数学定义如下:
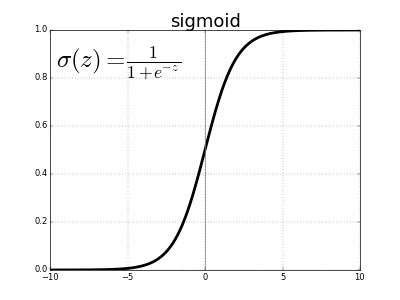
当z或自变量趋于负无穷大时,函数的值趋于零;当z趋于正无穷大时,函数的值趋于1。需要记住的是,该函数表示因变量行为的近似值,并且是一个假设。现在问题来了,为什么我们要用Sigmoid函数作为近似函数之一。这有一些简单的原因。
1. 它在可以捕获数据的非线性。虽然是一个近似的形式,但非线性的概念是模型精确的重要本质。
2. sigmoid函数在整个过程中是可微的,因此可以与梯度下降和反向传播方法一起使用,以计算不同层的权重。
3. 假设一个因变量服从一个sigmoid函数的固有假设的高斯分布的自变量,这是一个一般分布,我们可以获得许多随机发生的事件,这是一个好的的一般分布开始。
然而,sigmoid函数也面临着梯度消失的问题。从图中可以看出,一个sigmoid函数将其输入压缩到一个非常小的输出范围[0,1],并具有非常陡峭的渐变。因此,输入空间中仍然有很大的区域,即使是很大的变化也会在输出中产生很小的变化。这被称为梯度消失问题。这个问题随着层数的增加而增加,从而使神经网络的学习停留在一定的水平上。
Tanh函数
Tanh(z)函数是sigmoid函数的缩放版本,它的输出范围变成了[-1,1],而不是[0,1].
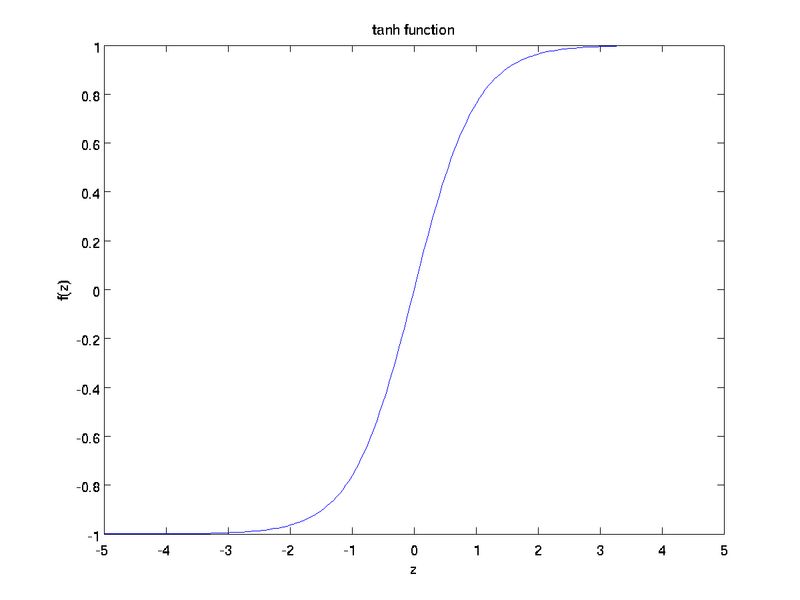
在某些地方使用Tanh函数代替sigmoid函数的原因,通常是因为当数据分布在0周围时,其导数值更高。一个更高的梯度对于更好的学习速率更有帮助。下图展示了两个函数Tanh和sigmoid的梯度值图像。
对于Tanh函数,当输入在[-1,1]之间时,得到导数值在[0.42,1]之间。
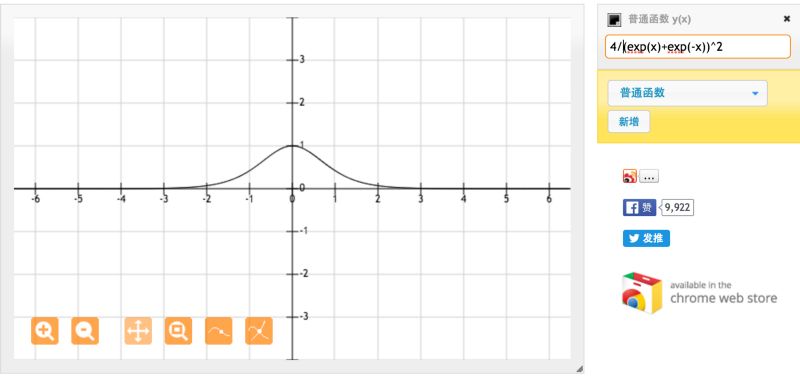
另一方面,对于sigmoid函数,当输入在[-1,1]之间时,得到导数值在[0.20,0.25]之间。
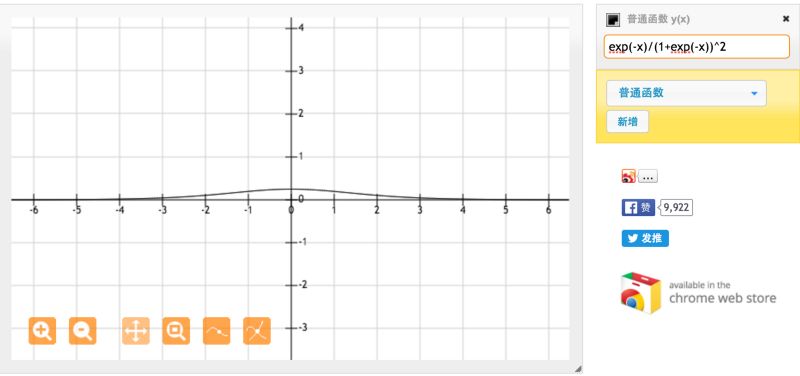
正如我们从上图看到的,Tanh函数比Sigmoid函数具有更大范围的导数,因此具有一个更好的学习速率。然而在Tanh函数中,依然会出现梯度消失的问题。
ReLU函数
在深度学习模型中,修正线性单元(ReLU)是最常用的激活函数。当函数输入负数时,函数输出0,对于任意正数x,函数输出本身。因此它可以写成f(x)=max(0,x)
其图像看起来如下:
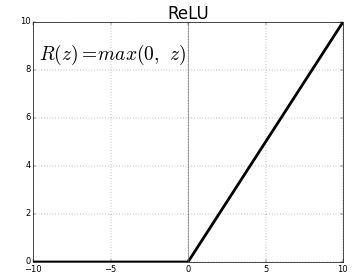
Leaky ReLU是一个其中最出名的一种变形,对于正数输入,其输出和ReLU一样,但是对于所有负数输出,不再是0,而是具有一个常数斜率(小于1).
这个斜率是在构建模型时,需要使用者设置的参数。它通常被叫做alpha,例如,使用者设置alpha=0.3.这个激活函数则表示为f(x)=max(0.3x,x)。这具有一个理论优点,通过x在所有值处都能有一个影响,使得在x中包含的信息被充分利用。
激活函数还有有其他可以替代的选择,但是对于从业者和研究人员,发现一般情况通过改变使用其他激活函数代替ReLU,并不能带来足够的收益。在平常实践中,ReLU比Sigmoid或者tanh函数表现的更好。
神经网络
到目前为止,我们已经介绍完了神经元和激活函数,它们一起是构建任意神经网络的基本构件。现在,我们更深入的了解什么是神经网络,以及它们不同的种类。我强烈的建议你,如果对于神经元和激活函数有任何的疑惑,回过头去复习一下它们。
在理解一个神经网络之前,有必要去理解神经网络中的Layer(层),一层Layer是一组有输入输出的神经元。每一个神经元的输入通过其所属的激活函数处理,例如,这是一个小型神经网络。
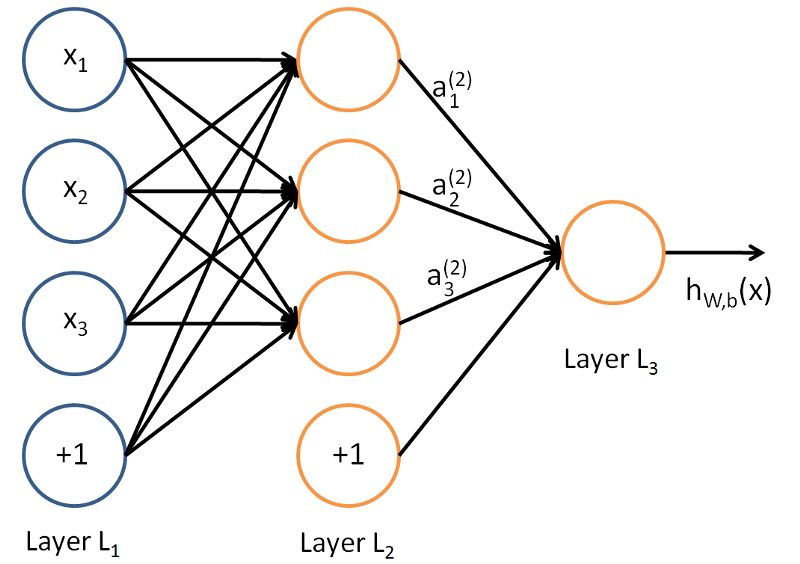
网络的最左边的layer叫做输入层,最右边的layer叫做输出层(在这个例子中,只有一个节点)。中间的layer叫做隐藏层,因为其值不能在训练集中观察到。我们也可以说,我们的神经网络例子,具有3个输入单元(不包括偏置单元),3个隐藏单元,1个输出单元。
任何神经网络都至少包含1个输入层和1个输出层。隐藏层的数量在不同的网络中不同,取决于待解决问题的复杂度。
另一个需要做笔记的重点是每一个隐藏层可以有一个不同的激活函数,例如,在同一个神经网络中,隐藏层layer1可能使用sigmoid函数,隐藏层layer2可能使用ReLU,后续的隐藏层layer3使用Tanh。激活函数的选择取决于待解决的问题以及使用的数据的类型。
现在对于一个可以做精确预测的神经网络,在其中每一层的每一个神经元都学习到了确定的权值。学习权值的算法叫做反向传播,其中的细节超过了本文的范围。
具有超过一个隐藏层的神经网络通常被叫做深度神经网络。
卷积神经网络(CNN)
卷积神经网络(CNN)是神经网络的一种,在计算机视觉领域应用非常广泛。它的名字来源于组成其隐藏层的种类。CNN的隐藏层通常包含卷积层,池化层,全连接层,以及归一化层。这些层的名字简洁的表明了,使用了卷积和池化函数等作为激活函数,而不是使用之前定义的普通激活函数。
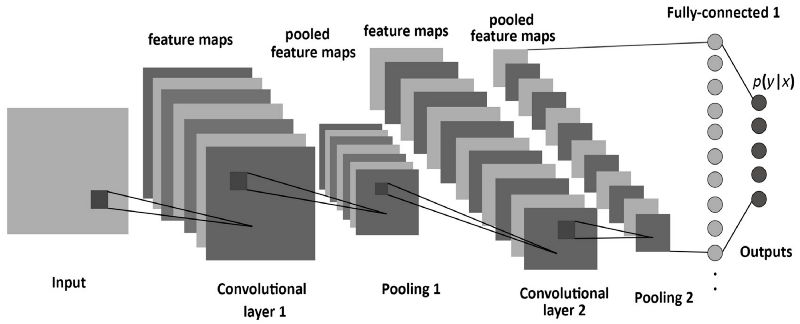
想要详细的了解CNN,需要先理解什么是卷积和池化。这些概念都来源于计算机视觉领域,定义如下:
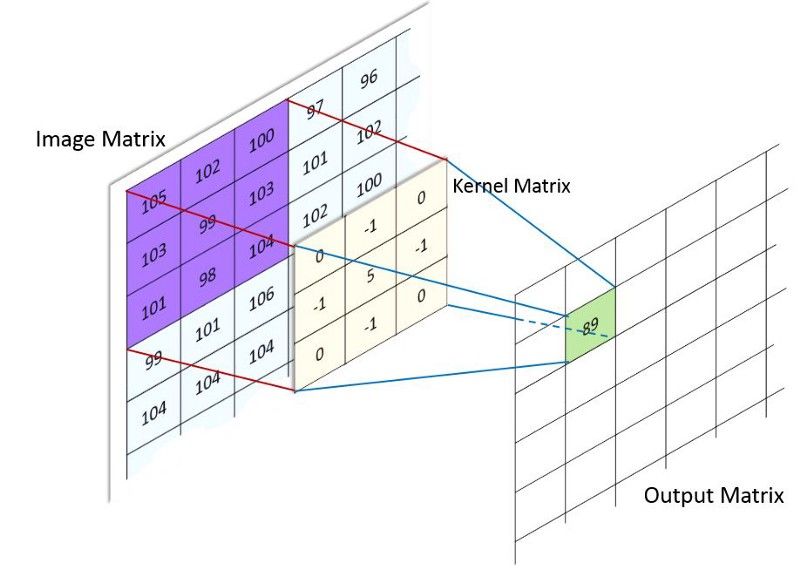
卷积:卷积作用在两个信号(1维)或者两张图片(2维)上:你可以认为其中一个作为"输入"信号(或图片),另一个作为一个"滤波器"(也叫作kernel,核),然后生成第三个信号作为输出。
用非专业的表述,就是在输入信号上使用一个滤波器。本质上,使用一个kernel(核)乘以输入信号,得到调整后的输出信号。数学上,两个函数f和g的卷积定义如下:
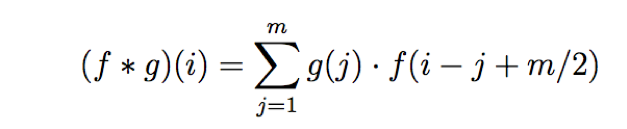
这就是输出函数和kernel(核)函数的点乘运算。
在图像处理案例中,可视化一个卷积核在整个图片上滑动是非常简单的,每个像素的值都是在这个过程中改变的。
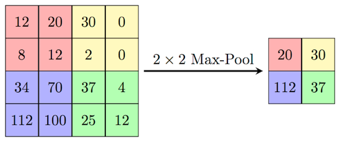
池化(pooling):池化是一个基于采样的离散化处理。它的目标是对输入(图片,隐藏层,输出矩阵等)进行下采样,来减小输入的维度,并且包含局部区域的特征。
有两个主要的池化种类,max和min pooling。正如其名字表明的,max pooling是在选择区域选择中最大值,min pooling是在选择区域中选择最小值。
因此,正如我们所看到的,卷积神经网络CNN是一个基本的深度神经网络,它包含多个隐藏层,除之前介绍的非线性激活函数之外,这些层还使用了卷积和池化函数。
更多详情可以在以下网站找到:
http://colah.github.io/posts/2014-07-Conv-Nets-Modular/
循环神经网络(RNN)
循环神经网络RNN,正如其名,是一个非常重要的神经网络种类,在自然语言处理领域应用非常广泛。在一个普通的神经网络中,一个输入通过很多层的处理后,得到一个输出,假设了两个连续的输入是互相独立不相关的。
然而这个假设在许多生活中的情节并不成立。例如,如果一个人相应预测一个给定时间的股票的价格,或者相应预测一个句子中的下一个单词,考虑与之前观测信息的依赖是有必要的。
RNNs被叫做循环,因为它们对于一个序列中的每一个元素执行相同的任务,它们的输出依赖于之前的计算。另一个理解RNN的角度是,认为它们有"记忆",能够捕捉到到目前为止的计算信息。理论上,RNN能够充分利用任意长序列中的信息,但是实践上,它们被限制在可以回顾仅仅一些步骤。
结构展示,一个RNN如下图所示。它可以想象成一个多层神经网络,每一层代表每一个确定时刻t的观测。
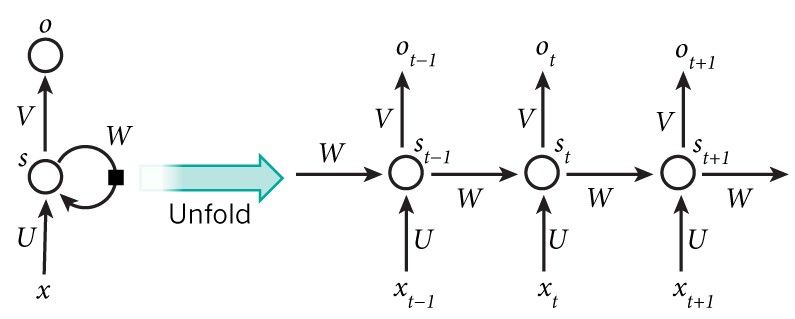
RNN在自然语言处理上展现了非常巨大的成功,尤其是它们的变种LSTM,它可以比RNN回顾得更多的。如果你对LSTM感兴趣,我建议你参考一下文章:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
在这篇文章中,我尝试去全面的介绍神经网络,从最基本的结构,一个神经元,到最有效的神经网络类型。这篇文章的目标是使更多的的读者了解神经网络如何从0开始构建,它被应用在哪一些领域,以及它的一些最成功的种类有哪些。
我明白有还有很多其他流行的神经网络种类,将打算在下一篇文章中涉及,如果你想要早一点覆盖到某些主题,请向我建议。
参考:
http://ufldl.stanford.edu/wiki/index.php/Neural_Networks
https://stats.stackexchange.com/questions/101560/tanh-activation-function-vs-sigmoid-activation-function
https://www.kaggle.com/dansbecker/rectified-linear-units-relu-in-deep-learning
http://ufldl.stanford.edu/tutorial/supervised/MultiLayerNeuralNetworks/
https://www.cs.cornell.edu/courses/cs1114/2013sp/sections/S06_convolution.pdf
http://machinelearninguru.com/computer_vision/basics/convolution/image_convolution_1.html
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1580

点击阅读原文,查看本文更多内容↙



