图像分割损失函数最详细总结,含代码
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

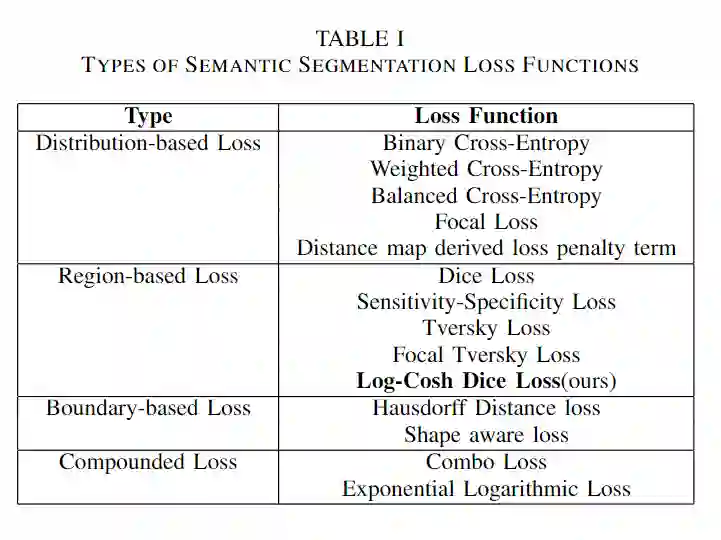
这是一篇关于图像分割损失函数的总结,具体包括:
Binary Cross Entropy
Weighted Cross Entropy
Balanced Cross Entropy
Dice Loss
Focal loss
Tversky loss
Focal Tversky loss
log-cosh dice loss (本文提出的新损失函数)
简介
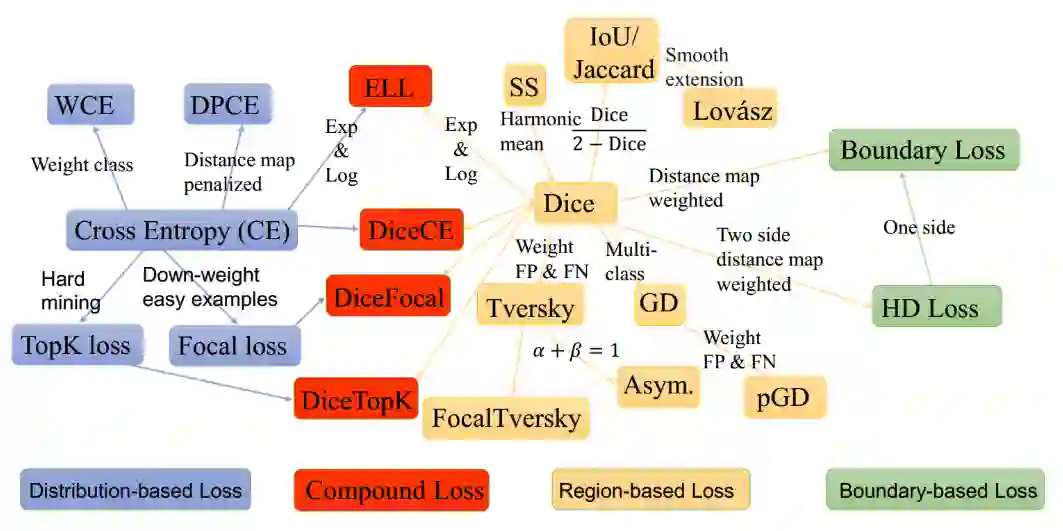
Distribution-based loss

 表示样本i的label,正类为1,负类为0。
表示样本i的label,正类为1,负类为0。
 表示预测值。如果是计算 N 个样本的总的损失函数,只要将 N 个 Loss 叠加起来就可以了:
表示预测值。如果是计算 N 个样本的总的损失函数,只要将 N 个 Loss 叠加起来就可以了:

#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn
as nn
import torch.nn.functional
as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)
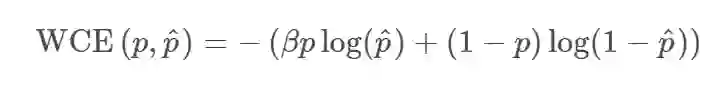
 >1,减少假阴性;设置 <1,减少假阳性。这样相比于原始的交叉熵Loss,在样本数量不均衡的情况下可以获得更好的效果。
>1,减少假阴性;设置 <1,减少假阳性。这样相比于原始的交叉熵Loss,在样本数量不均衡的情况下可以获得更好的效果。
class WeightedCrossEntropyLoss(torch.nn.CrossEntropyLoss):
"""
Network has to have NO NONLINEARITY!
"""
def __init__(self, weight=None):
super(WeightedCrossEntropyLoss, self).__init__()
self.weight = weight
def forward(self, inp, target):
target = target.long()
num_classes = inp.size()[
1]
i0 =
1
i1 =
2
while i1 < len(inp.shape):
# this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 +=
1
i1 +=
1
inp = inp.contiguous()
inp = inp.view(
-1, num_classes)
target = target.view(
-1,)
wce_loss = torch.nn.CrossEntropyLoss(weight=self.weight)
return wce_loss(inp, target)

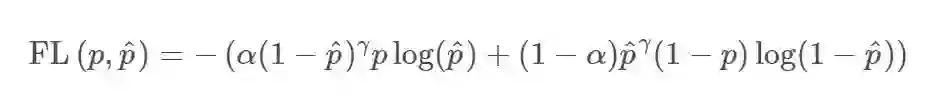
class FocalLoss(nn.Module):
"""
copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
def __init__(self, apply_nonlin=None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin
self.alpha = alpha
self.gamma = gamma
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average
if self.smooth
is
not
None:
if self.smooth <
0
or self.smooth >
1.0:
raise ValueError(
'smooth value should be in [0,1]')
def forward(self, logit, target):
if self.apply_nonlin
is
not
None:
logit = self.apply_nonlin(logit)
num_class = logit.shape[
1]
if logit.dim() >
2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(
0), logit.size(
1),
-1)
logit = logit.permute(
0,
2,
1).contiguous()
logit = logit.view(
-1, logit.size(
-1))
target = torch.squeeze(target,
1)
target = target.view(
-1,
1)
# print(logit.shape, target.shape)
#
alpha = self.alpha
if alpha
is
None:
alpha = torch.ones(num_class,
1)
elif isinstance(alpha, (list, np.ndarray)):
assert len(alpha) == num_class
alpha = torch.FloatTensor(alpha).view(num_class,
1)
alpha = alpha / alpha.sum()
elif isinstance(alpha, float):
alpha = torch.ones(num_class,
1)
alpha = alpha * (
1 - self.alpha)
alpha[self.balance_index] = self.alpha
else:
raise TypeError(
'Not support alpha type')
if alpha.device != logit.device:
alpha = alpha.to(logit.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(
0), num_class).zero_()
one_hot_key = one_hot_key.scatter_(
1, idx,
1)
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth/(num_class
-1),
1.0 - self.smooth)
pt = (one_hot_key * logit).sum(
1) + self.smooth
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
alpha = torch.squeeze(alpha)
loss =
-1 * alpha * torch.pow((
1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
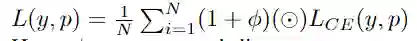
class DisPenalizedCE(torch.nn.Module):
"""
Only for binary 3D segmentation
Network has to have NO NONLINEARITY!
"""
def forward(self, inp, target):
# print(inp.shape, target.shape) # (batch, 2, xyz), (batch, 2, xyz)
# compute distance map of ground truth
with torch.no_grad():
dist = compute_edts_forPenalizedLoss(target.cpu().numpy()>
0.5) +
1.0
dist = torch.from_numpy(dist)
if dist.device != inp.device:
dist = dist.to(inp.device).type(torch.float32)
dist = dist.view(
-1,)
target = target.long()
num_classes = inp.size()[
1]
i0 =
1
i1 =
2
while i1 < len(inp.shape):
# this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 +=
1
i1 +=
1
inp = inp.contiguous()
inp = inp.view(
-1, num_classes)
log_sm = torch.nn.LogSoftmax(dim=
1)
inp_logs = log_sm(inp)
target = target.view(
-1,)
# loss = nll_loss(inp_logs, target)
loss = -inp_logs[range(target.shape[
0]), target]
# print(loss.type(), dist.type())
weighted_loss = loss*dist
return loss.mean()
Region-based loss
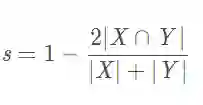
def get_tp_fp_fn(net_output, gt, axes=None, mask=None, square=False):
"""
net_output must be (b, c, x, y(, z)))
gt must be a label map (shape (b, 1, x, y(, z)) OR shape (b, x, y(, z))) or one hot encoding (b, c, x, y(, z))
if mask is provided it must have shape (b, 1, x, y(, z)))
:param net_output:
:param gt:
:param axes:
:param mask: mask must be 1 for valid pixels and 0 for invalid pixels
:param square: if True then fp, tp and fn will be squared before summation
:return:
"""
if axes
is
None:
axes = tuple(range(
2, len(net_output.size())))
shp_x = net_output.shape
shp_y = gt.shape
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[
0],
1, *shp_y[
1:]))
if all([i == j
for i, j
in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type ==
"cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(
1, gt,
1)
tp = net_output * y_onehot
fp = net_output * (
1 - y_onehot)
fn = (
1 - net_output) * y_onehot
if mask
is
not
None:
tp = torch.stack(tuple(x_i * mask[:,
0]
for x_i
in torch.unbind(tp, dim=
1)), dim=
1)
fp = torch.stack(tuple(x_i * mask[:,
0]
for x_i
in torch.unbind(fp, dim=
1)), dim=
1)
fn = torch.stack(tuple(x_i * mask[:,
0]
for x_i
in torch.unbind(fn, dim=
1)), dim=
1)
if square:
tp = tp **
2
fp = fp **
2
fn = fn **
2
tp = sum_tensor(tp, axes, keepdim=
False)
fp = sum_tensor(fp, axes, keepdim=
False)
fn = sum_tensor(fn, axes, keepdim=
False)
return tp, fp, fn
class SoftDiceLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1606.04797.pdf
"""
super(SoftDiceLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [
0] + list(range(
2, len(shp_x)))
else:
axes = list(range(
2, len(shp_x)))
if self.apply_nonlin
is
not
None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
dc = (
2 * tp + self.smooth) / (
2 * tp + fp + fn + self.smooth)
if
not self.do_bg:
if self.batch_dice:
dc = dc[
1:]
else:
dc = dc[:,
1:]
dc = dc.mean()
return -dc
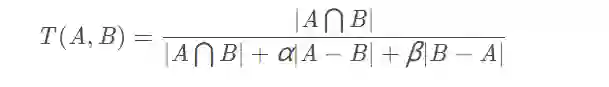
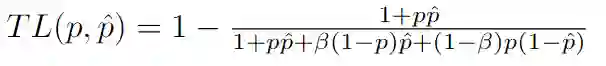
class TverskyLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1706.05721.pdf
"""
super(TverskyLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.alpha =
0.3
self.beta =
0.7
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [
0] + list(range(
2, len(shp_x)))
else:
axes = list(range(
2, len(shp_x)))
if self.apply_nonlin
is
not
None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
tversky = (tp + self.smooth) / (tp + self.alpha*fp + self.beta*fn + self.smooth)
if
not self.do_bg:
if self.batch_dice:
tversky = tversky[
1:]
else:
tversky = tversky[:,
1:]
tversky = tversky.mean()
return -tversky
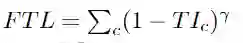
class FocalTversky_loss(nn.Module):
"""
paper: https://arxiv.org/pdf/1810.07842.pdf
author code: https://github.com/nabsabraham/focal-tversky-unet/blob/347d39117c24540400dfe80d106d2fb06d2b99e1/losses.py#L65
"""
def __init__(self, tversky_kwargs, gamma=0.75):
super(FocalTversky_loss, self).__init__()
self.gamma = gamma
self.tversky = TverskyLoss(**tversky_kwargs)
def forward(self, net_output, target):
tversky_loss =
1 + self.tversky(net_output, target)
# = 1-tversky(net_output, target)
focal_tversky = torch.pow(tversky_loss, self.gamma)
return focal_tversky
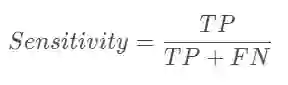
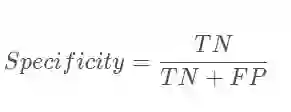
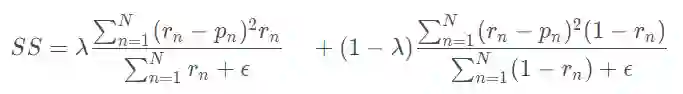
class SSLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
Sensitivity-Specifity loss
paper: http://www.rogertam.ca/Brosch_MICCAI_2015.pdf
tf code: https://github.com/NifTK/NiftyNet/blob/df0f86733357fdc92bbc191c8fec0dcf49aa5499/niftynet/layer/loss_segmentation.py#L392
"""
super(SSLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.r =
0.1
# weight parameter in SS paper
def forward(self, net_output, gt, loss_mask=None):
shp_x = net_output.shape
shp_y = gt.shape
# class_num = shp_x[1]
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[
0],
1, *shp_y[
1:]))
if all([i == j
for i, j
in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type ==
"cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(
1, gt,
1)
if self.batch_dice:
axes = [
0] + list(range(
2, len(shp_x)))
else:
axes = list(range(
2, len(shp_x)))
if self.apply_nonlin
is
not
None:
softmax_output = self.apply_nonlin(net_output)
# no object value
bg_onehot =
1 - y_onehot
squared_error = (y_onehot - softmax_output)**
2
specificity_part = sum_tensor(squared_error*y_onehot, axes)/(sum_tensor(y_onehot, axes)+self.smooth)
sensitivity_part = sum_tensor(squared_error*bg_onehot, axes)/(sum_tensor(bg_onehot, axes)+self.smooth)
ss = self.r * specificity_part + (
1-self.r) * sensitivity_part
if
not self.do_bg:
if self.batch_dice:
ss = ss[
1:]
else:
ss = ss[:,
1:]
ss = ss.mean()
return ss
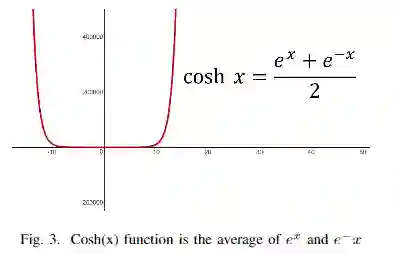
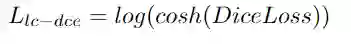
def log_cosh_dice_loss(self, y_true, y_pred):
x = self.dice_loss(y_true, y_pred)
return tf.math.log((torch.exp(x) + torch.exp(-x)) /
2.0)
Boundary-based loss

class DistBinaryDiceLoss(nn.Module):
"""
Distance map penalized Dice loss
Motivated by: https://openreview.net/forum?id=B1eIcvS45V
Distance Map Loss Penalty Term for Semantic Segmentation
"""
def __init__(self, smooth=1e-5):
super(DistBinaryDiceLoss, self).__init__()
self.smooth = smooth
def forward(self, net_output, gt):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
# one hot code for gt
with torch.no_grad():
if len(net_output.shape) != len(gt.shape):
gt = gt.view((gt.shape[
0],
1, *gt.shape[
1:]))
if all([i == j
for i, j
in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(net_output.shape)
if net_output.device.type ==
"cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(
1, gt,
1)
gt_temp = gt[:,
0, ...].type(torch.float32)
with torch.no_grad():
dist = compute_edts_forPenalizedLoss(gt_temp.cpu().numpy()>
0.5) +
1.0
# print('dist.shape: ', dist.shape)
dist = torch.from_numpy(dist)
if dist.device != net_output.device:
dist = dist.to(net_output.device).type(torch.float32)
tp = net_output * y_onehot
tp = torch.sum(tp[:,
1,...] * dist, (
1,
2,
3))
dc = (
2 * tp + self.smooth) / (torch.sum(net_output[:,
1,...], (
1,
2,
3)) + torch.sum(y_onehot[:,
1,...], (
1,
2,
3)) + self.smooth)
dc = dc.mean()
return -dc
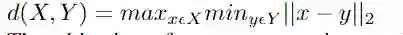
class HDDTBinaryLoss(nn.Module):
def __init__(self):
"""
compute haudorff loss for binary segmentation
https://arxiv.org/pdf/1904.10030v1.pdf
"""
super(HDDTBinaryLoss, self).__init__()
def forward(self, net_output, target):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
pc = net_output[:,
1, ...].type(torch.float32)
gt = target[:,
0, ...].type(torch.float32)
with torch.no_grad():
pc_dist = compute_edts_forhdloss(pc.cpu().numpy()>
0.5)
gt_dist = compute_edts_forhdloss(gt.cpu().numpy()>
0.5)
# print('pc_dist.shape: ', pc_dist.shape)
pred_error = (gt - pc)**
2
dist = pc_dist**
2 + gt_dist**
2
# \alpha=2 in eq(8)
dist = torch.from_numpy(dist)
if dist.device != pred_error.device:
dist = dist.to(pred_error.device).type(torch.float32)
multipled = torch.einsum(
"bxyz,bxyz->bxyz", pred_error, dist)
hd_loss = multipled.mean()
return hd_loss
Compounded loss
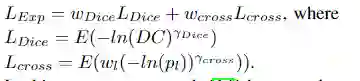
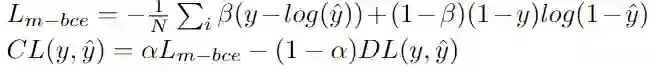
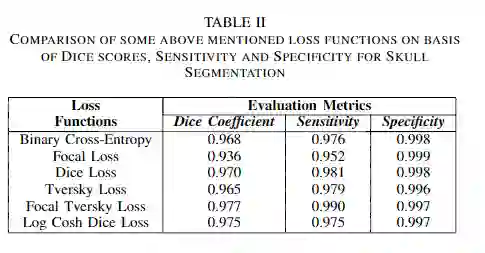
实验与结果

推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

登录查看更多
相关内容





相关VIP内容
相关资讯