YOLACT++:更强的实时实例分割网络,可达33.5 FPS/34.1mAP!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

编辑:Amusi
前言
近期推出的实例分割(Instance Segmentation)论文很多,有时间 Amusi 出一期:一文看尽实例分割系列。同时值得关注的实例分割论文也很多,比如前几天沈春华老师团队推出的的SOLO,详见:超越EfficientNet:metaKernel;实例分割新网络:SOLO
本文要速递介绍的这篇实例分割论文,是收录在ICCV 2019的实时实例分割YOLACT的改进版:YOLACT++。这里简单介绍一下YOLACT的由来:You Only Look At CoefficienTs(这里要cue一下YOLO)。
YOLACT++
《YOLACT++: Better Real-time Instance Segmentation》

论文:https://arxiv.org/abs/1912.06218
作者团队:加利福尼亚大学戴维斯分校
时间:2019年12月16日
注:在 COCO 上,34.1 mAP,速度高达 33.5 FPS!
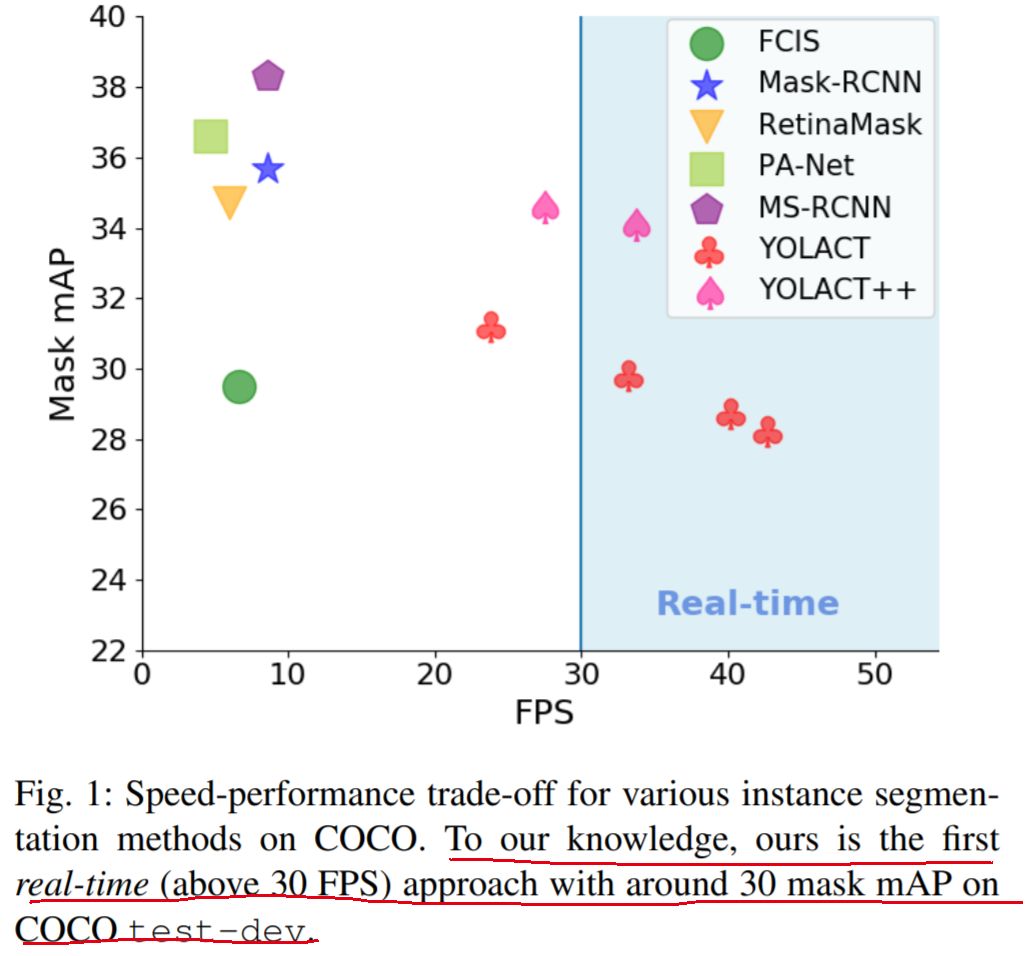
摘要:我们为实时(> 30 fps)实例分割提供了一个简单的全卷积模型,该模型在单个Titan Xp上评估的MS COCO上取得了SOTA结果,这比以前的任何最新的方法都快得多。此外,我们仅在一个GPU上训练后即可获得此结果。我们通过将实例分割分为两个并行的子任务来完成此任务:(1)生成一组原型(prototype) masks,以及(2)预测每个实例的mask 系数。然后,我们通过将原型与模板系数线性组合来生成实例 masks。我们发现,由于此过程不依赖于 repooling,因此此方法可产生非常高质量的masks。此外,我们分析了 prototype 的 emergent 行为,并显示了它们是完全卷积的。我们还提出了快速NMS,这是对标准NMS的12毫秒快速替代,仅会有点影响性能。最后,通过将可变形(deformable)卷积合并到骨干网络中,使用更好的 anchor 尺度和长宽比优化预测head,并添加新颖的快速 masks 重新评分分支,我们的YOLACT ++模型可以在MS COCO上以33.5 FPS的实现34.1 mAP。
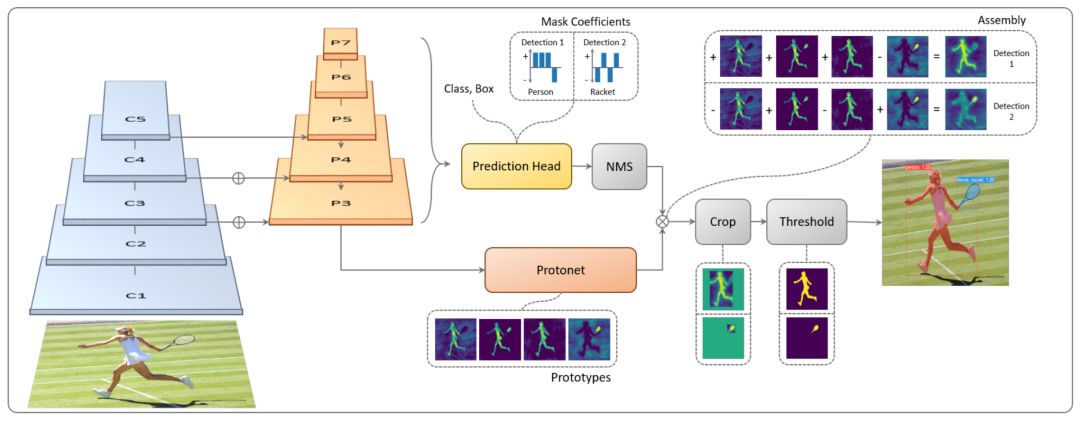
YOLACT 网络结构
因为YOLACT++是基于YOLACT改进来的,所以相同的地方不再重复介绍,大家结合CVer推过的YOLACT文章一起阅读,下面只解释创新点。
加州大学提出:实时实例分割算法YOLACT,可达33 FPS/30mAP!现已开源!
1 Fast Mask Re-Scoring Network
Mask 评分分支由6个具有ReLU非线性的卷积层和1个全局池化层组成。由于没有特征级联,也没有fc层,因此速度开销仅为〜1 ms。
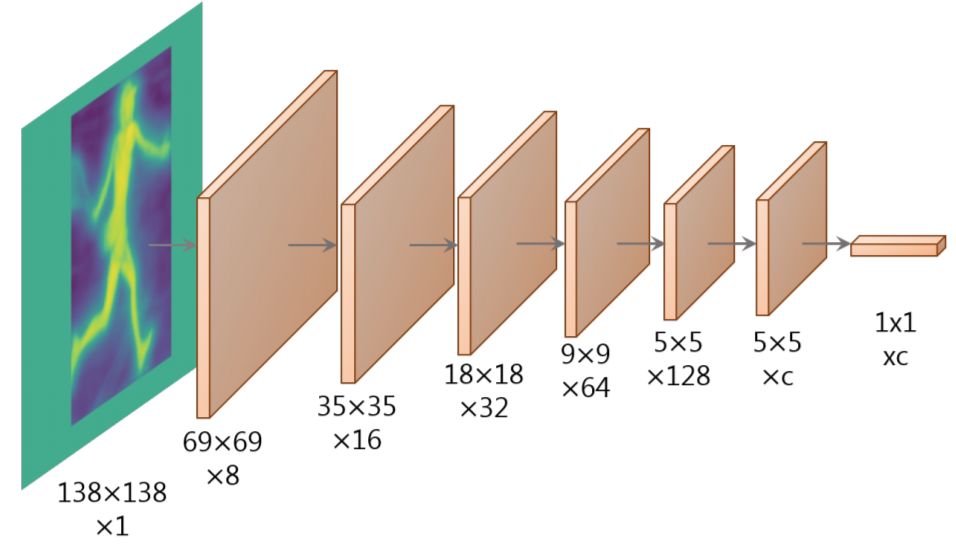
Fast Mask Re-Scoring Network
2 Deformable Convolution with Intervals
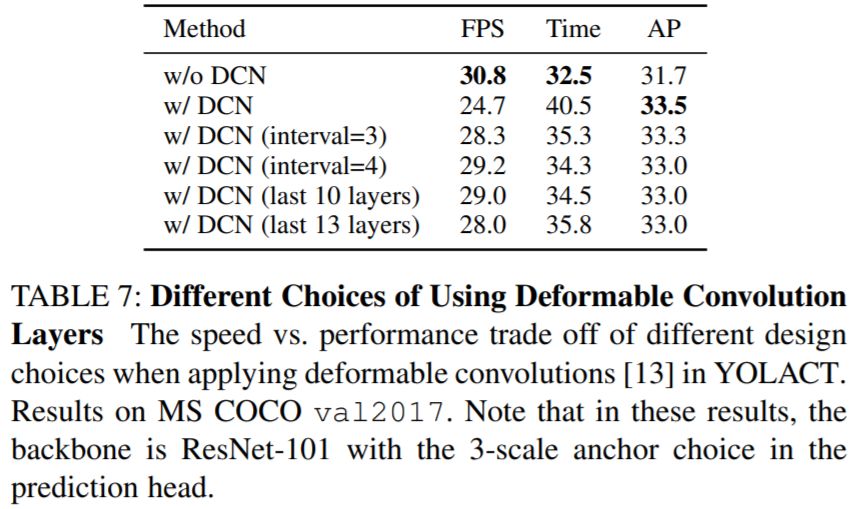
3 Optimized Prediction Head
作者尝试两种变体:(1)保持尺度不变,同时将anchor长宽比从[1,1 / 2,2]增加到[1,1 / 2,2,1 / 3、3],以及(2)保持 长宽比不变,同时将每个FPN level 的比例增加三倍([1x,2^(1/3)x,2^(2/3) x])。与YOLACT的原始配置相比,前者和后者分别增加了5/3倍和3倍的 anchors 数量
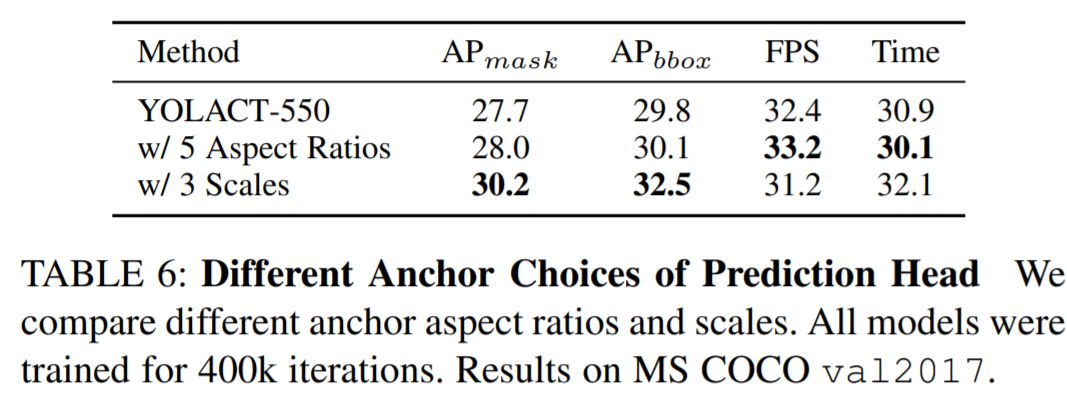
实验结果
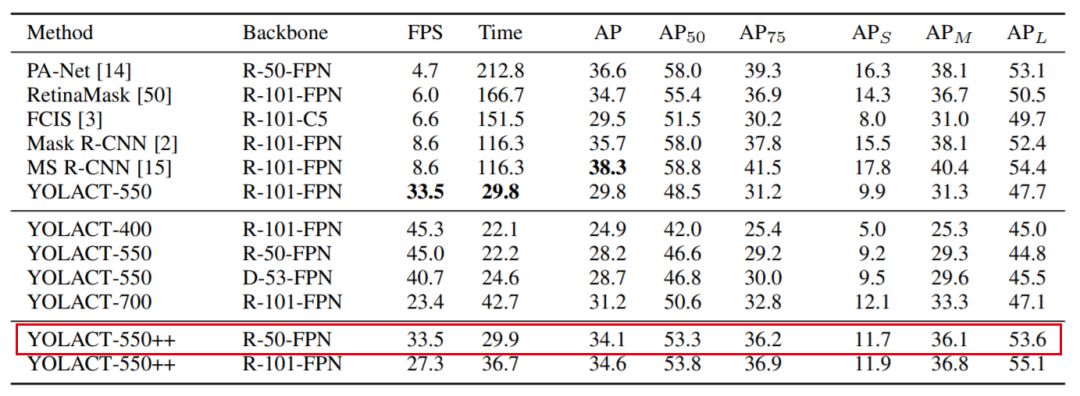
mask mAP and speed on COCO test-dev

YOLACT vs YOLACT++
虽然YOLACT++还没有开源,但各位CVers可以看一下已经开源的YOLACT:
https://github.com/dbolya/yolact
如果YOLACT++开源了,CVer会第一时间报道,如果喜欢这样的论文推荐,欢迎点个在看,支持一下!
CVer 推荐阅读
目标检测三大开源神器:Detectron2/mmDetectron/SimpleDet
重磅!CVer-图像分割交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!



