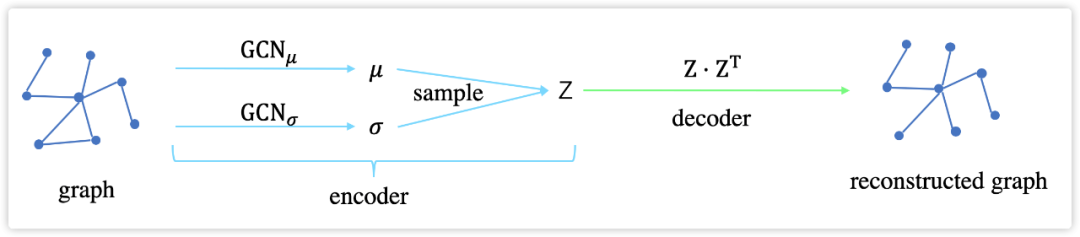
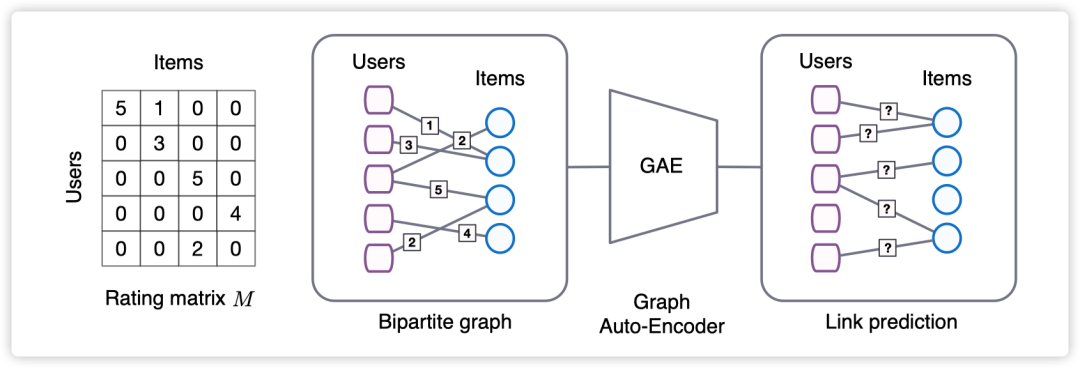
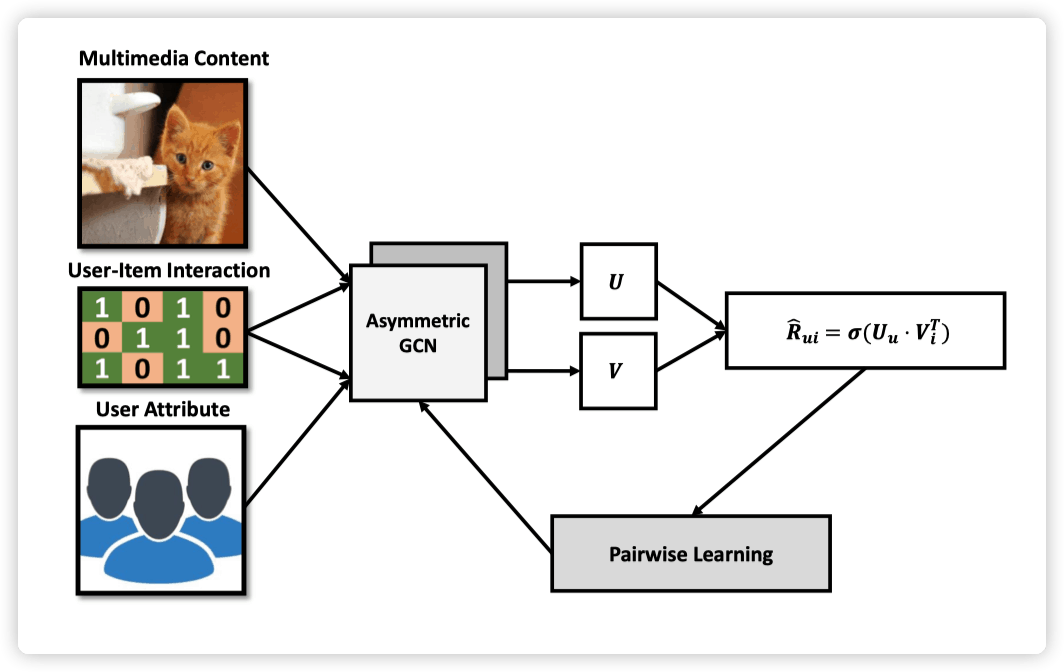
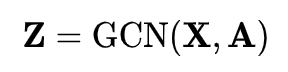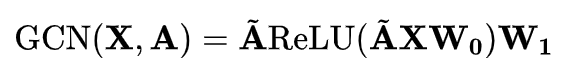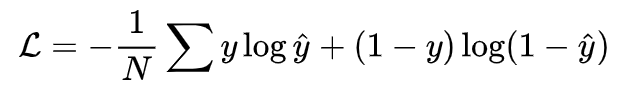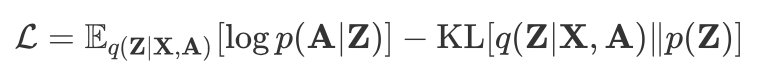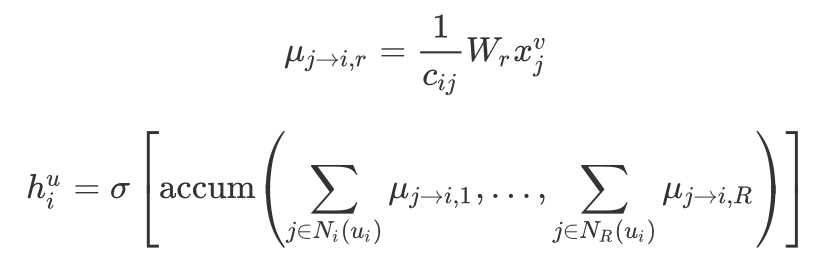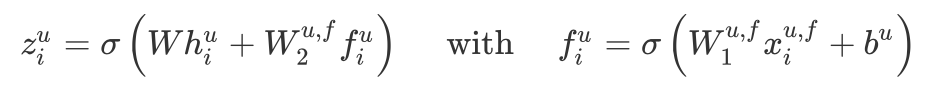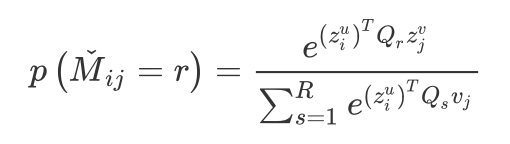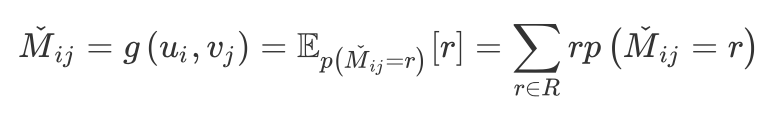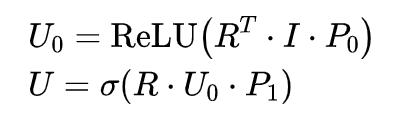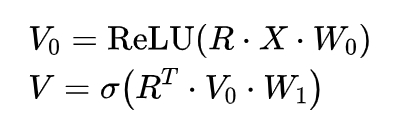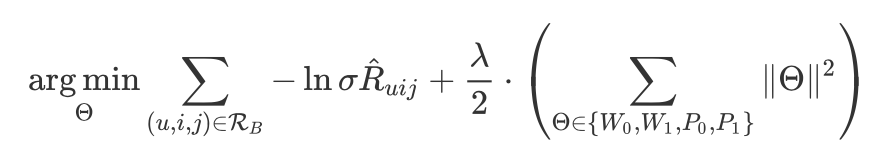这是 Kipf 作为二作的一篇解决推荐系统中 matrix completion 问题的文章,发表在 18 年的 KDD。这篇文章提出,matrix completion 任务可以视作为 graph 上的链接预测问题,即 users 和 items 构成了一张二部图,图上的边代表相应的 user 与 item 进行了交互,于是 matrix completion 问题就变成了预测这张二部图上的边的问题。为了解决 users-items 二部图上的链接预测问题,这篇文章提出了基于在二部图上进行 message passing 的图自编码器框架 GCMC,且引入了 side information,还分析了 side information 对于推荐系统中冷启动的影响。
2.2 模型详解
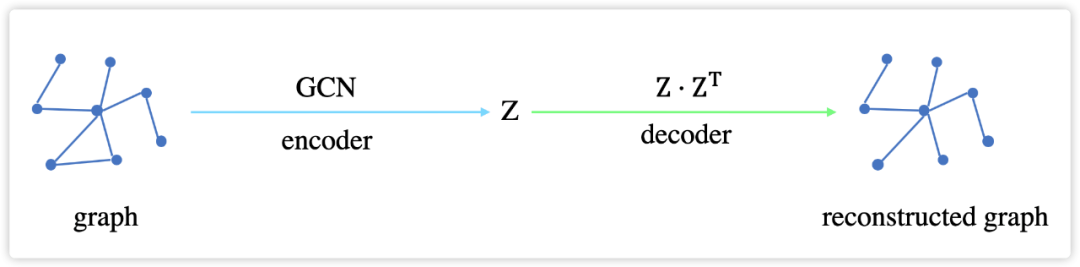
先简要分析一下 GCMC 的整体框架。首先,GCMC 把 users 和 items 的初始 features
和
(one-hot 向量)输入到一个 GCN 层中,得到 users 和 items 的 hidden representations:
,
,再将 users 和 items 的 side information
和
输入到一个 Dense 层中,得到 side information 的 hidden representations:
,
。然后将初始 features 和 side information 的 hidden representations 一起输入到一个 Dense 层中,得到 users 和 items 最终的 embeddings:
,
(以上为 encoder 阶段),最后通过计算内积(decoder 阶段),预测 user 对 item 的喜好程度。下面给出每一步的详细计算方法。首先,GCN 层的计算方式如下:
其中,
是 item j 传递给 user i 的信息,下标 r 指定了 user i 给 item j 的评分是 r(由于用户的评分类别不止一种,因此使用不同的 r 来区分,即
)。
是参数矩阵,
是归一化因子,可以是
或者
,其中
表示 user i 的邻居数。accum 也有两种选择:stack 或者 sum。
表示激活函数,可以是 sigmoid、ReLU 等。得到了 user i 的初始 feature 的 hidden representation
后,再将 side information 的 hidden representation 与
一起输入进一个 Dense 层即可得到 user i 的最终 embedding:
其中,右式表示得到 side information 的 hidden representation 的 Dense 层,左式表示得到最终 embedding 的 Dense 层。在得到 users 和 items 的 embeddings 后,通过下式来预测 user i 对 item j 的评分属于 r 的概率:
最终,GCMC 对 user i 对 item j 的评分的预测为:
2.3 效果分析 作者使用了 6 个数据集,可以分为 3 类:
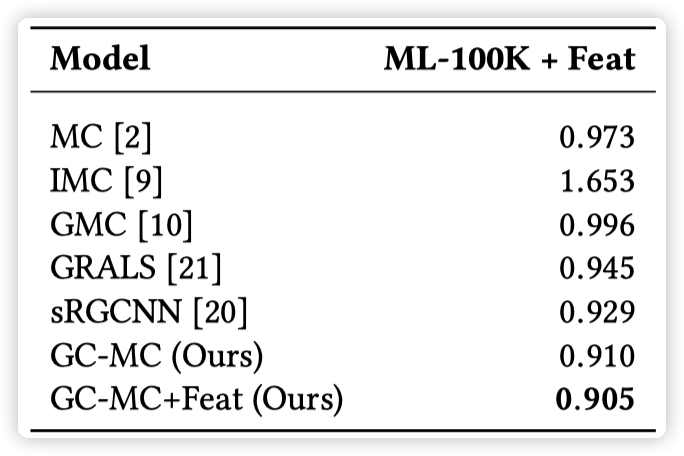
对比的方法只利用 users 或 items 一方的 features:ml-100k
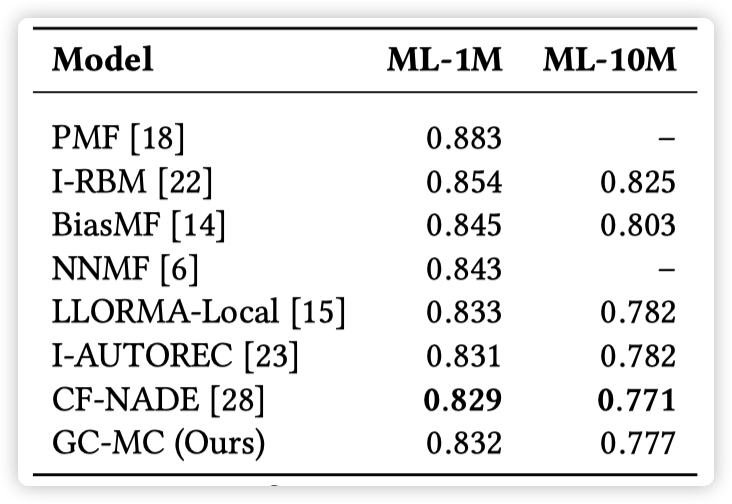
GCMC 和 对比的方法都不使用 side information:ml-1m,ml-10m
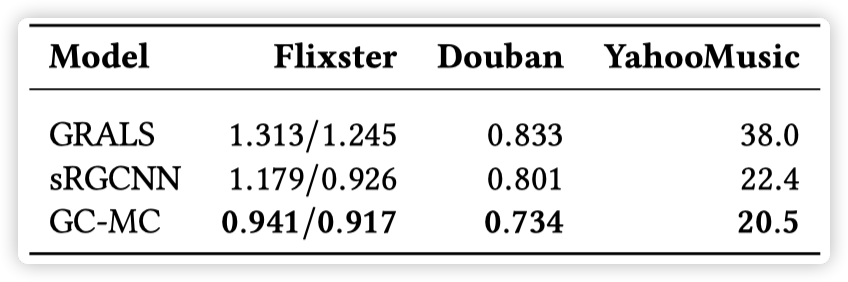
Users 和 items 的 side information 以 graph 的形式呈现:Flixster,Douban,YahooMusic
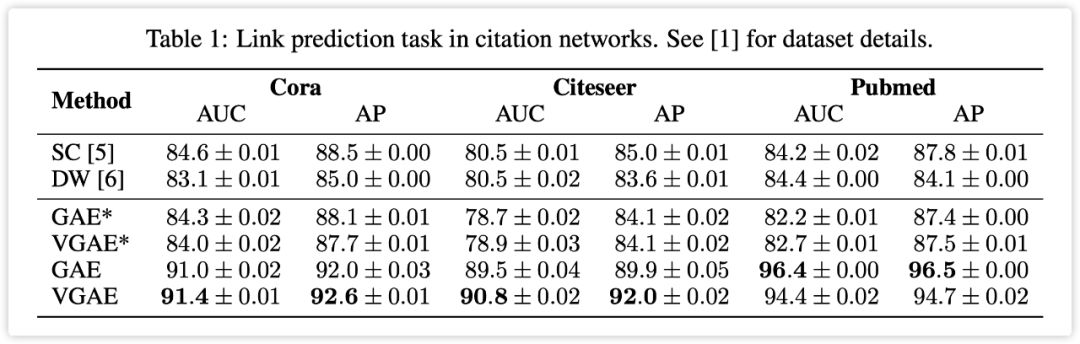
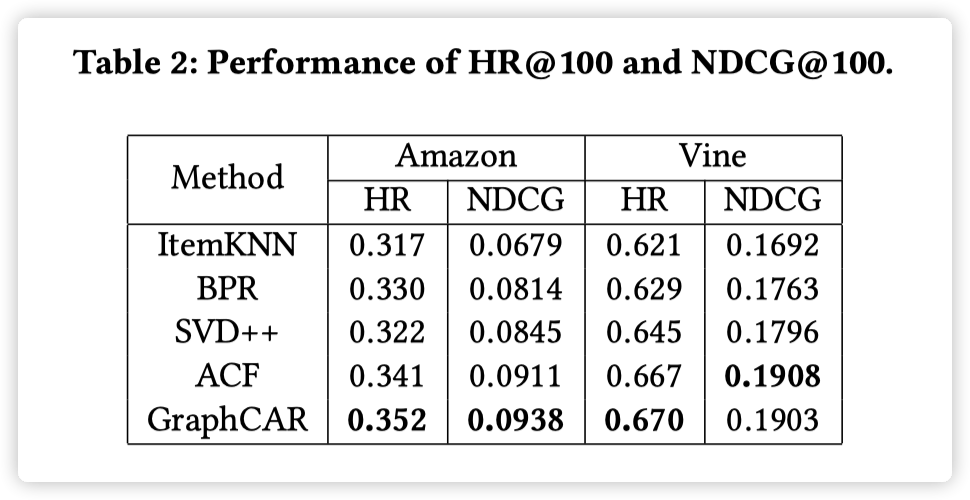
实验结果:
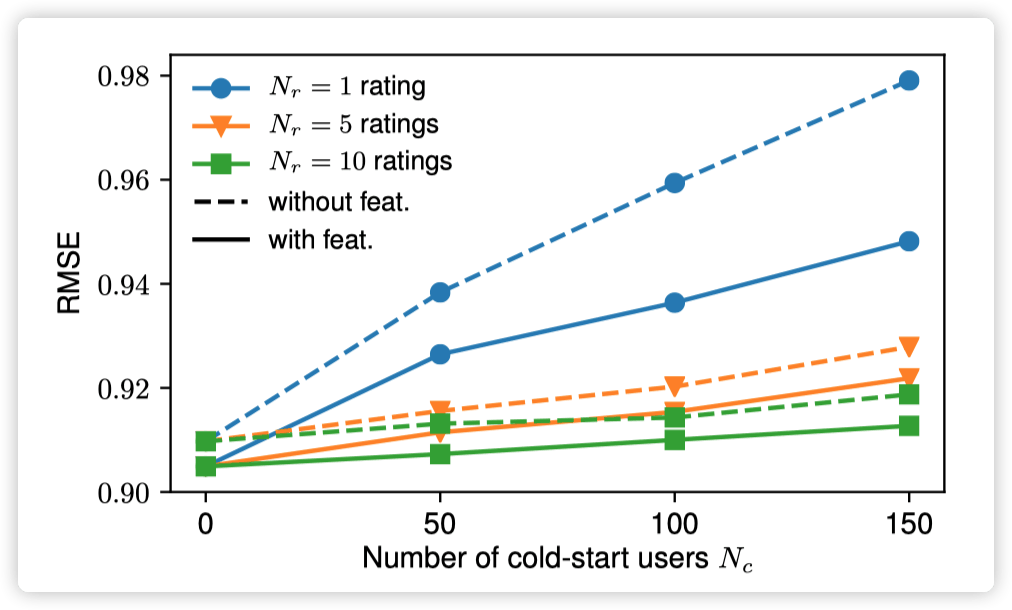
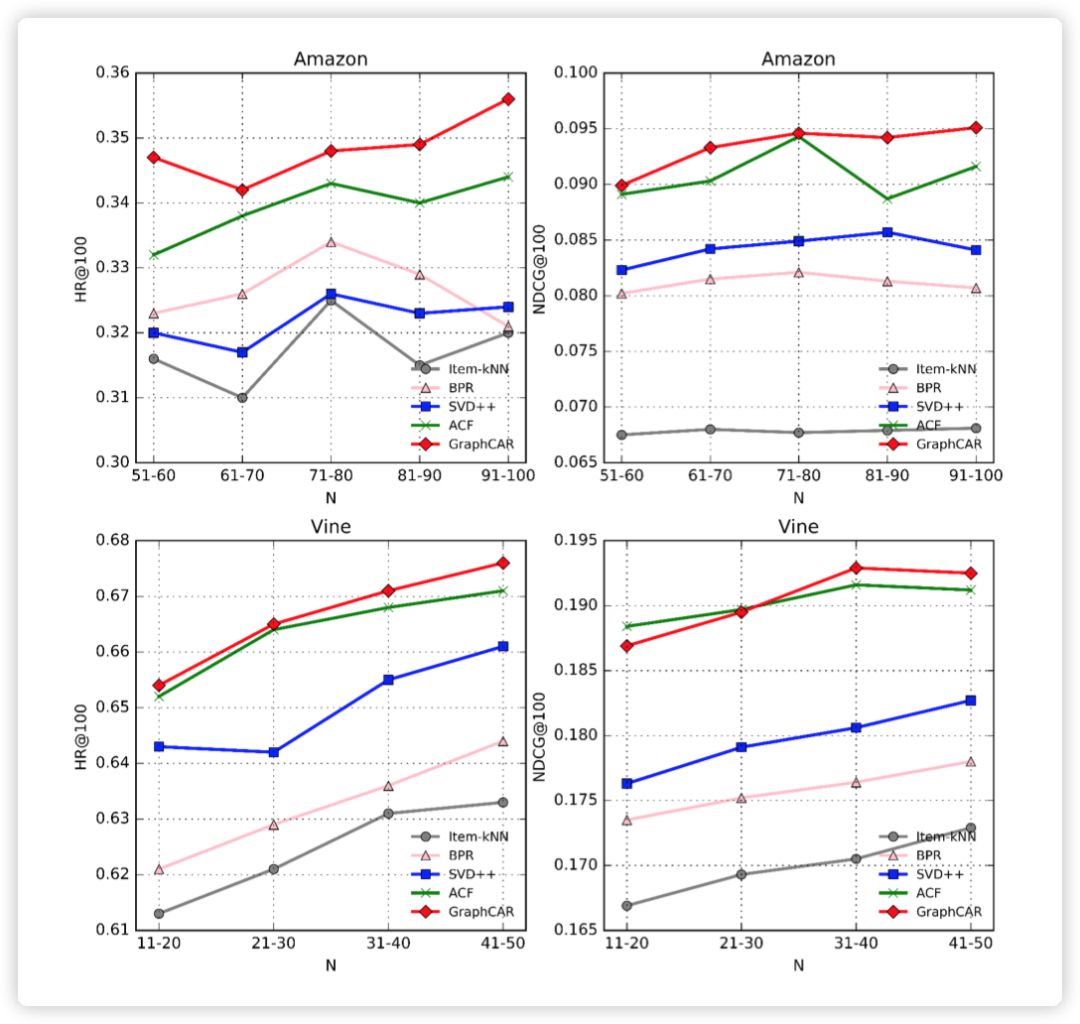
实验结果表明,在有 side information 时,GCMC 的效果好于其他方法,尤其是当 side information 以 graph 的形式存在时,GCMC 的效果优势更加明显。而当没有 side information 时,GCMC 也表现出了 competitive results。作者还分析了 side information 对冷启动的影响,文中以 ml-100k 为例,将一些用户的评分数量人为减少,然后对比了 GCMC 分别在使用和不使用 side information 时的效果。
从上图可以看出,使用 side information 的 GCMC 效果更好,而且随着冷启动用户的人数增多,引入 side information 带来的效果提升更加明显。2.4 小结该篇论文将推荐系统中的 matrix completion 任务视作 graph 上的链接预测任务来处理,并使用图自编码器,引入 side information,在一些 benchmark 数据集上超过了一些 SOTA 方法,而且还分析了 side information 给冷启动带来的帮助。GraphCAR
论文标题:GraphCAR: Content-aware Multimedia Recommendation with Graph Autoencoder