AlphaZero的黑箱打开了!DeepMind论文登上PNAS
![]()
新智元报道

新智元报道
【新智元导读】AlphaZero 表明神经网络可以学到人类可理解的表征。

AlphaZero 在训练中获得人类象棋概念
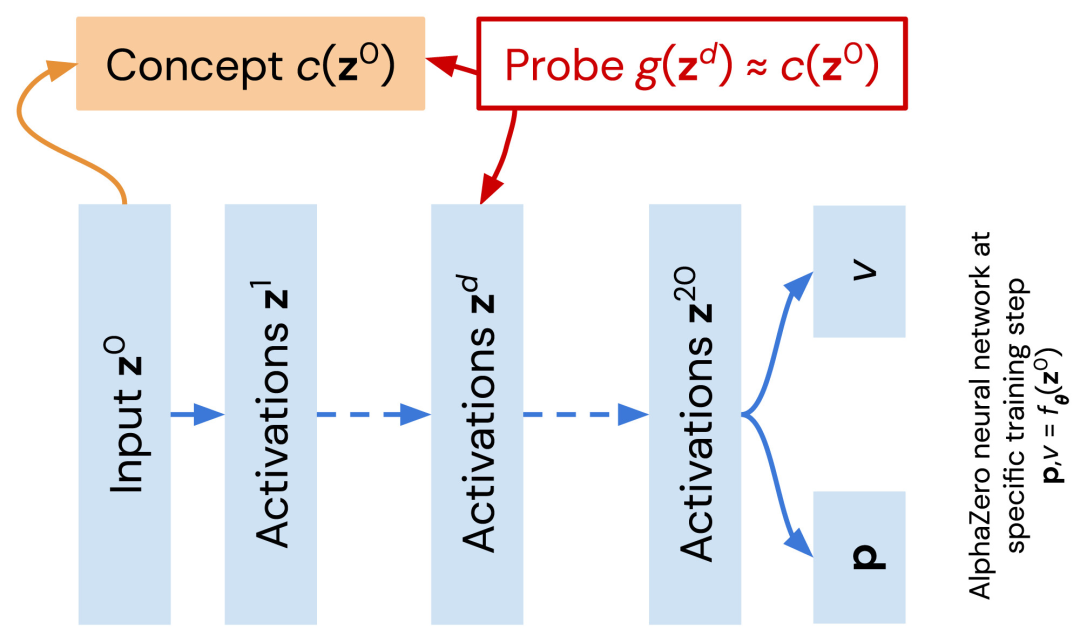
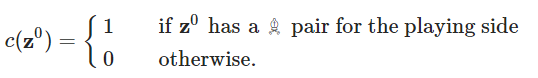
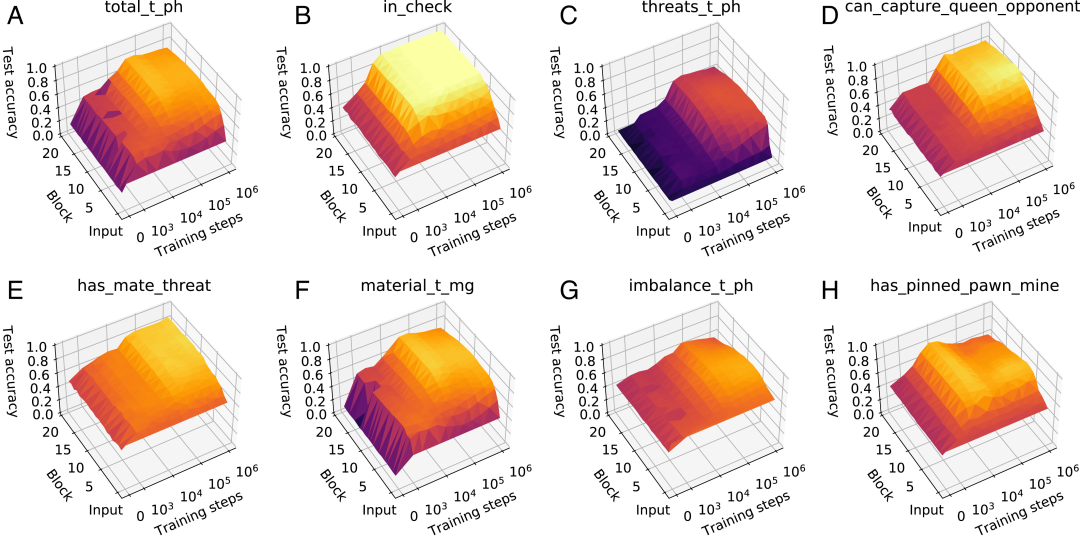
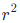 急剧上升的点一致。
急剧上升的点一致。
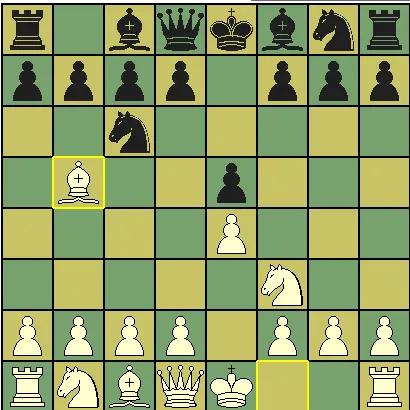
AlphaZero 的开局策略与人类不同

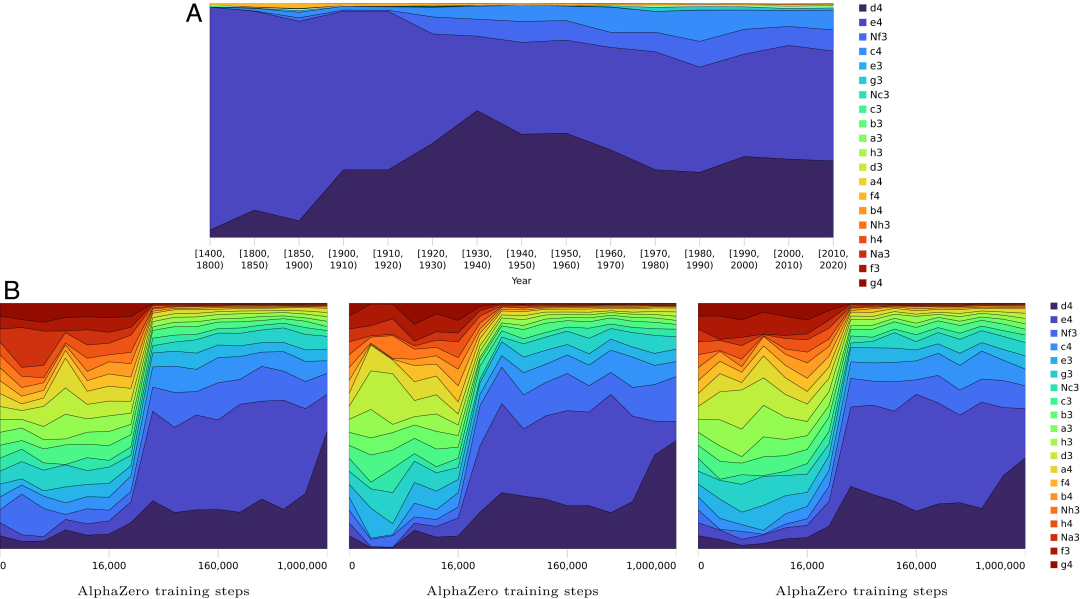
AlphaZero 掌握知识的过程


登录查看更多
相关内容
Arxiv
0+阅读 · 2023年1月26日
Arxiv
0+阅读 · 2023年1月25日
Arxiv
10+阅读 · 2022年2月10日



相关VIP内容
相关资讯