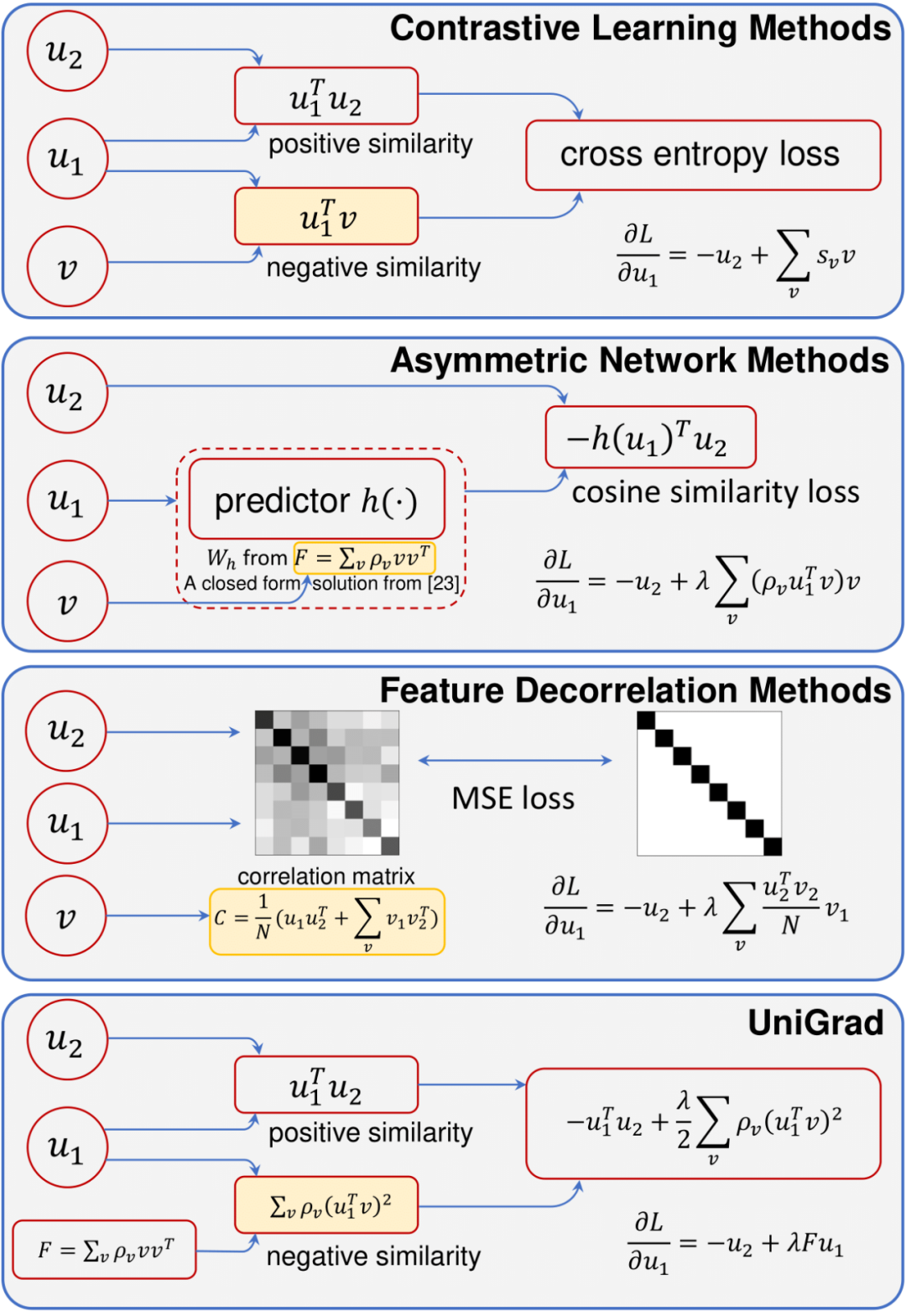
一个框架统一Siamese自监督学习,清华、商汤提出简洁、有效梯度形式,实现SOTA
来自清华大学、商汤科技等机构的研究者们提出一种简洁而有效的梯度形式——UniGrad,不需要复杂的 memory bank 或者 predictor 网络设计,也能给出 SOTA 的性能表现。

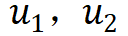 表示不同的 augmented view,添加上标 ,
表示不同的 augmented view,添加上标 ,
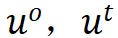 表示孪生网络中 online 或者 target 分支产生的特征。
表示孪生网络中 online 或者 target 分支产生的特征。
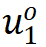 拉近与正样本
拉近与正样本
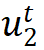 的距离,提升与负样本
的距离,提升与负样本
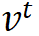 的距离,一般会使用以下的 InfoNCE Loss:
的距离,一般会使用以下的 InfoNCE Loss:
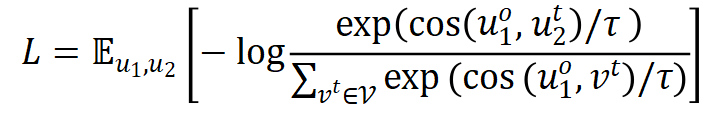
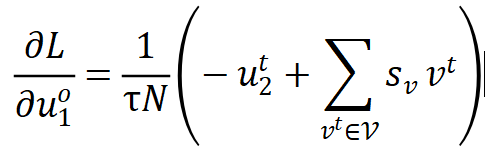
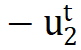 的作用是将正样本拉近,
的作用是将正样本拉近,
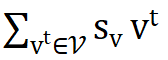 的作用是将负样本推离,因此作者将这两项分别称为正梯度和负梯度。
的作用是将负样本推离,因此作者将这两项分别称为正梯度和负梯度。
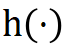 ,同时关闭 target branch 的梯度反传,最终使用下面的损失函数
,同时关闭 target branch 的梯度反传,最终使用下面的损失函数
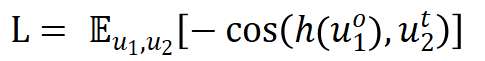
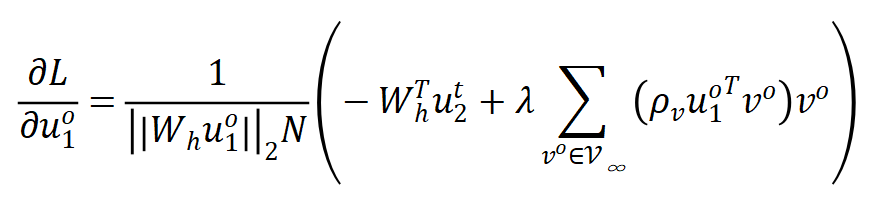
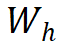 是 predictor 网络的解析解。
可以看到,上式同样主要有两个部分:
是 predictor 网络的解析解。
可以看到,上式同样主要有两个部分:
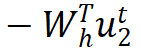 是正梯度,
是正梯度,
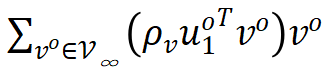 是负梯度。
是负梯度。
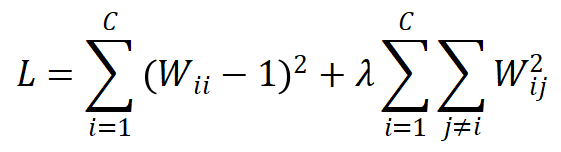
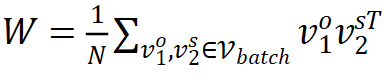 是两个 augmented view 之间的相关性矩阵。
该损失函数希望相关性矩阵上的对角线元素接近 1,而非对角线元素接近 0。
是两个 augmented view 之间的相关性矩阵。
该损失函数希望相关性矩阵上的对角线元素接近 1,而非对角线元素接近 0。
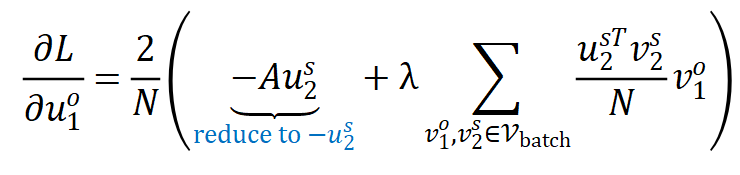
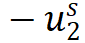 ,同时,原始的 Ba
rlow Twins 对特征采取了 batch normalization,作者将其替换为
,同时,原始的 Ba
rlow Twins 对特征采取了 batch normalization,作者将其替换为
 normalization,这些变换都不会影响到最终性能。
normalization,这些变换都不会影响到最终性能。

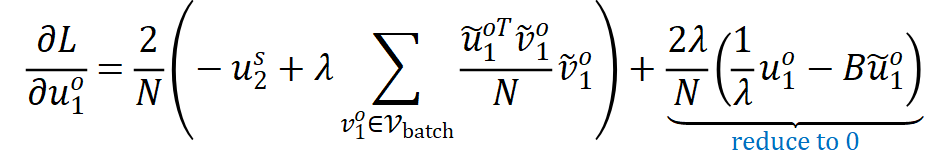
 n
ormalization,作者可以
去掉最后一项而不影响其性能。
这样,特征解耦方法的梯度形式就能统一为:
n
ormalization,作者可以
去掉最后一项而不影响其性能。
这样,特征解耦方法的梯度形式就能统一为:
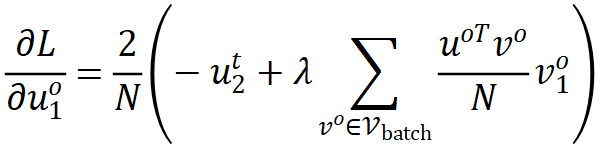
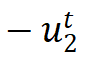 是正梯度,
是正梯度,
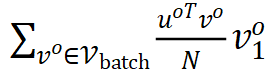 组成负梯度,它们分别来自相关性矩阵中的对角线和非对角线元素。
因此,特征解耦方法本质上和其它两类方法非常相似,它们只是在损失函数中将正负样本用不同的形式组合起来了。
组成负梯度,它们分别来自相关性矩阵中的对角线和非对角线元素。
因此,特征解耦方法本质上和其它两类方法非常相似,它们只是在损失函数中将正负样本用不同的形式组合起来了。
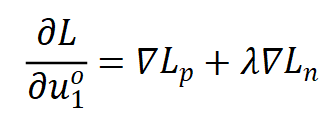
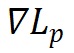 对应正样本的特征,
对应正样本的特征,
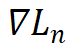 是负样本特征的加权平均,
是负样本特征的加权平均,
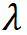 是平衡两者的系数,这种相似的结构说明三类方法的工作机理非常接近。
是平衡两者的系数,这种相似的结构说明三类方法的工作机理非常接近。
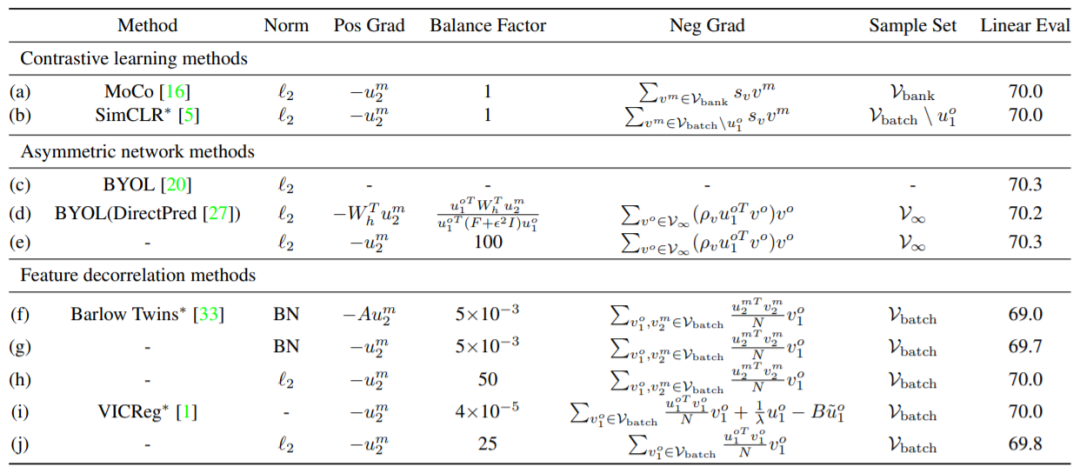
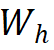 替换为单位阵而没有影响性能,因此,非对称网络方法的梯度形式可以统一成表 1(e) 中的形式。
替换为单位阵而没有影响性能,因此,非对称网络方法的梯度形式可以统一成表 1(e) 中的形式。
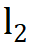 normalization,这些替换都不会导致性能下降;
对 VICReg 来说,表 1(j) 去掉梯度中最后一项,同时加上
normalization,这些替换都不会导致性能下降;
对 VICReg 来说,表 1(j) 去掉梯度中最后一项,同时加上
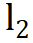 normalization,这对性能几乎没有影响。
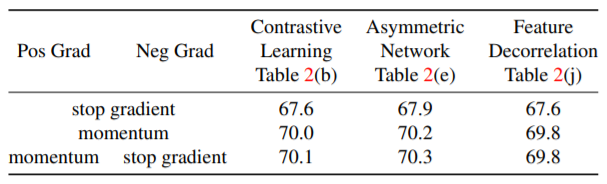
最后,比较表 1(hj),它们唯一的差异在于负样本系数的计算方式,但是性能上却差异很小,所以特征解耦方法的梯度形式可以统一成表 1(j) 中的形式。
normalization,这对性能几乎没有影响。
最后,比较表 1(hj),它们唯一的差异在于负样本系数的计算方式,但是性能上却差异很小,所以特征解耦方法的梯度形式可以统一成表 1(j) 中的形式。
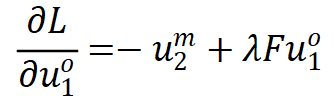
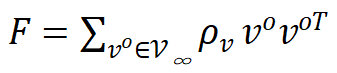 是相关性矩阵的滑动平均。
UniGrad
本质上就是表 1(e) 的梯度形式,这种梯度不需要额外的 memory bank,也不需要设计额外的 projector,实验表明无论是 linear evaluation 还是 transfer learning,它都能够取得 SOTA 的实验性能。
是相关性矩阵的滑动平均。
UniGrad
本质上就是表 1(e) 的梯度形式,这种梯度不需要额外的 memory bank,也不需要设计额外的 projector,实验表明无论是 linear evaluation 还是 transfer learning,它都能够取得 SOTA 的实验性能。
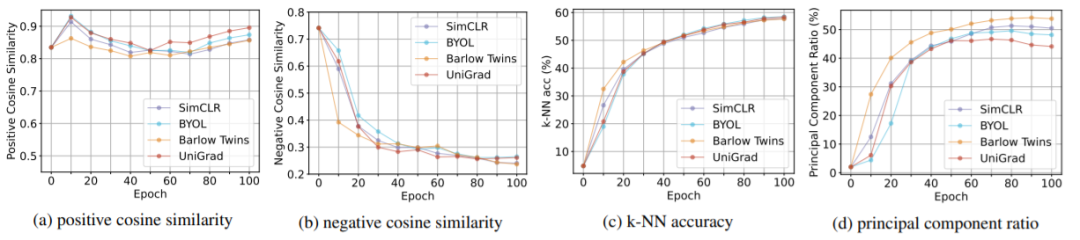
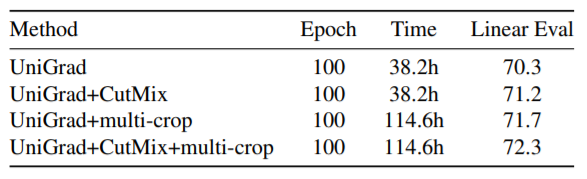
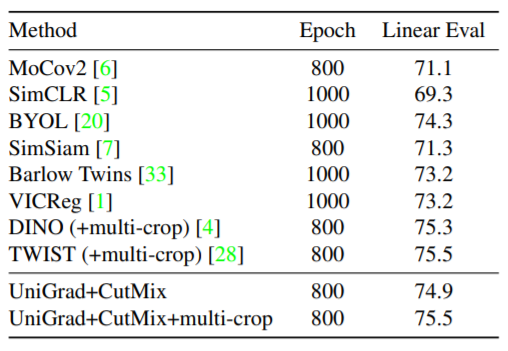

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月16日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月16日