DeepMind最新研究:拓展自监督Resnet的极限,Imagenet的监督学习可超越吗?

尽管在残差网络表示学习中,自监督方法(self-supervised)取得了一些进展,但在 ImageNet 分类基准测试中,它们仍然表现不佳,这一点限制了它们在关键性任务中的适用性。
近日,基于之前的理论研究,来自 DeepMind 的研究人员们提出了 RELICv2,该方法结合了对比学习损失和一个显式的不变性损失,论文标题为 Pushing thelimits of self-supervised ResNets: Can we outperform supervised learningwithout labels on ImageNet?
在 ImageNet 分类任务中,RELICv2 使用 ResNet50 实现了 77.1% 的 top-1 正确率(linear evaluation),并且在更大的 ResNet 上实现了 80.6% 的 top-1 正确率,该结果远超于之前最好的自监督方法。更特别的是,RELICv2 是第一个使用一系列标准 ResNet 架构,在类似比较中始终优于有监督基线的表征学习方法。
研究证明,尽管使用的是 ResNet 模型做视觉编码,RELICv2 仍然能与最先进的自监督视觉 transformer 相媲美。
背景与动机
大规模基础模型,特别是预训练语言模型和预训练多模态模型是表征学习领域的重要发展方向。这些模型使用不需要数据标签的无监督学习方法训练(或self-supervised),并且能轻松地应用到 few-shot 和 zero-shot 场景下,能够在那些标注数据昂贵且不易获取的下游任务中取得良好的性能。
多视角对比学习已成为表征学习中一种成功的策略。然而,到目前为止,这些表示的下游用途从未超过监督学习的性能,限制了它们的用途。在这项工作中,团队展示了在 ImageNet 上的类似比较中,使用相同的网络架构,可以在不使用标签的情况下训练的表征,其性能优于已建立的有监督基线。
为了实现这一目标,团队构建了基于不变因果机制(RELIC)框架的表示学习,该框架基于不变预测原理学习表示。与其他方法不同,RELIC 通过损失函数中的附加项显式地强制保持数据集中相似点和不相似点之间关系的不变性。RELIC 学习更紧密地遵循底层数据几何形状的表示。这个属性确保学习到的表征能够很好地传递到下游任务。
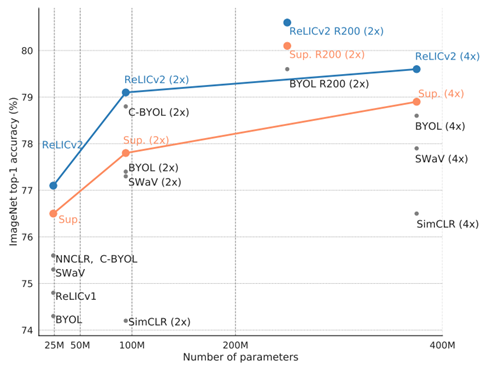
图1. ImageNet 上的 top-1 准确率(ResNet50, linear evaluation)
在本文中,团队提出了 RELICv2,它利用了对 RELIC 的理论理解,通过更好的策略来选择相似点和不同点,并将这些策略纳入对比和不变性目标函数中。因此,RELICv2 在广泛的 ResNet 架构上实现了自我监督学习的最新性能。此外,RELICv2 是第一种自监督表示学习方法,在1、2 和 4 个变量的线性 ImageNet 评估中,它优于有监督的 ResNet50 基线方法(图1);请注意,其他工作优于此基线,但通过使用与基线不同的网络架构来实现,因此不是类似的网络架构比较。团队演示了如何通过改变自我监督训练方案而不需要改变网络架构来超越监督基线。在 ImageNet RELICv2 上,top-1 的分类准确率达到 77.1%(ResNet50),而 ResNet200 则达到 80.6%。
在 ResNet101、ResNet152 和 ResNet200 等更大的 ResNet 架构上,RELICv2 的性能也优于监督基线。团队还证明了 RELICv2 在迁移学习、半监督学习、鲁棒性和非分布概化等其他任务中表现出竞争性能。最后,虽然使用了 ResNet 架构,但 RELICv2 的性能与最新的基于视觉 transformer 的方法。
方法
团队参考了大量的多视图表征学习方法。对比方法是利用实例分类问题来学习表示的方法的子集。给定一批数据 B,这些方法通过与正样本和负样本的对比来学习从 B 采样的锚点xi的表征,目的是将正样本点作为锚点的实例与负样本点进行分类。 在最简单的情景中,锚点和正样本点是同一图像的两个不同增强版本,负样本是batch 中其他图像(使用相同的数据增强策略)。标准的对比学习可以使用下面的对数似然函数中简明地描述:
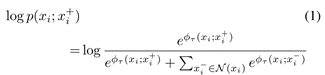
团队使用目标网络设置(Grillet al.,2020),其中 f 和 g 具有相同的架构,但 g 的网络参数是 f 的网络参数的指数移动平均。
RELIC 引入了一种不变性损失函数,定义为锚点和它的一个正样本之间的 Kullback-Leibler 散度,两者的计算如方程 1:
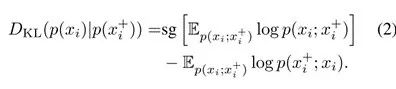
团队采用停止梯度算子 sg[·],它不影响 KL 散度的计算,但避免了优化过程中的退化解。
与 RELIC 类似,RELICv2 的基本目标是最小化对比负对数似然和不变性损失的组合:
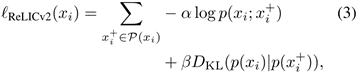
其中 α 和 β 是标量超参数,它们权重对比和不变性损失对总体目标的相对重要性。RELICv2 与 RELIC 的不同之处在于选择适当的正负点集,以及如何将数据的结果视图组合到目标函数中。
多裁剪数据增强是由(Caron et al.,2020)引入的,包括比较同一图像中几个较大(224*224)和较小(96*96)的随机裁剪。与(Caron 等人,2020年)显著不同的是,团队使用了四种较大的裁剪和两种较小的裁剪。
团队有可能对较大的裁剪应用基于显著性的背景去除。为此,团队使用了 DeepUSPS 的完全无监督版本(Nguyen 等人,2019 年),团队使用 ImageNet 训练集中的少量图像对其进行训练。然后以概率为 pm 对图像随机应用显著性掩模,将图像前景与背景分离;这使团队能够学习可以定位图像中的对象的表示。对于大多数实验,团队设置 pm=0.1。然后,团队应用标准的 SimCLR 增强:随机水平翻转和颜色失真,包括随机序列的亮度、饱和度、对比度和色调变化,以及可选的灰度转换。
清单 1 提供了类似 pytorch 的伪代码,详细描述了如何为 P(xi) 和 N(xi) 的选择计算公式 3,特别是如何在目标网络设置中组合不同的数据视图。与之前的工作类似,团队使用 LARS 优化器在不重启的情况下,使用余弦衰减学习速率计划最小化目标。除非另有说明,团队将模型训练为 1000 个 epoch,warmup 为 10 个 epoch,批大小为|B| =4096。

清单1. RELICv2 的伪代码
与其他几项工作类似,从理论上讲,RELIC 可以学习良好的表征,因为它们可以根据数据的潜在类结构进行聚类,因此对于解决下游分类任务很有用。RELIC 和 RELICv2 与其他作品不同的是,它们使用了显式不变性损失(eq. 2)和对比损失。
不变性损失鼓励正样本的表征与锚点的表征类似,导致表征具有更紧密的类内集中,如引理 1 所述。然而,由于相似度的度量是 KL 散度之间的对比可能性,这强制了批次中一个正样本相对于其他负样本的预测分布应该与锚点相似。实际上,不变性的损失允许团队在批处理中的所有点之间强制约束,而不仅仅是正数之间的成对约束,从而导致更好地保留数据底层结构的表征。
实验结果
团队在 ImageNetILSVRC-2012 数据集的训练集上不使用标签来预训练表示,然后在各种各样的下游设置、数据集和任务中评估学习到的表示。
首先,在 ImageNet 验证集上检查标准线性评估和半监督下的性能。
接下来,团队研究了 RELICv2 表征在其他图像分类数据集和语义分割上的迁移能力。团队还在一系列具有挑战性的数据集上测试了 RELICv2 的鲁棒性和泛化能力。
最后,为了研究团队的方法的可扩展性和通用性,团队还在更大、更复杂的 Joint Foto Tree(JFT-300M)数据集上进行了预训练,并在 ImageNet 验证集上报告线性评估协议的结果。补充材料中提供了一套完整的结果和所有实验设置的细节。团队考虑的有监督基线是 ResNet50,该架构使用交叉熵损失训练。
ImageNet上的线性分类器测试
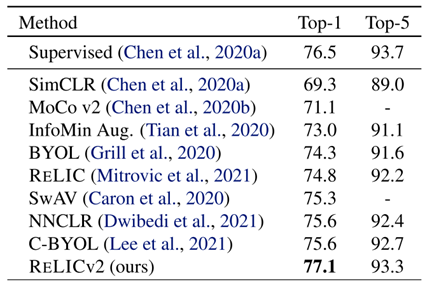
表1. ImageNet 上的 Top-1 和 Top-5 准确率(linear evaluation)
图1 比较了 RELICv2 与监督基线和其他竞争方法在 ResNet50、ResNet200 配置下的性能。RELICv2 不仅性能优于竞争对手的方法,而且也是第一种自监督表征学习方法,在所有编码器配置中始终优于有监督基线。此外,对于 101 层、152 层和 200 层 ResNet 架构,RELICv2 的性能也优于监督基线,并且在类似的参数计数上与最新的视觉转换器架构相比具有竞争力。
ImageNet上的半监督训练
接下来,团队评估 RELICv2 在半监督环境下的性能。团队对图像表示进行了预训练,并在 ImageNet 训练集中使用一小部分可用标签来细化学习后的图像表示。表2 报告了 ImageNet 验证集的 Top-1 和 top-5 精度。当使用 10% 的数据进行微调时,RELICv2 的性能优于监督基线和所有以前的最先进的自我监督方法。当使用 1% 的数据时,只有 C-BYOL 的性能优于 RELICv2。进一步的半监督结果使用更大的 ResNet 模型和不同的数据集分割。
迁移学习
团队通过测试学习的特征是否能跨图像域来评估 RELICv2 表示的通用性。
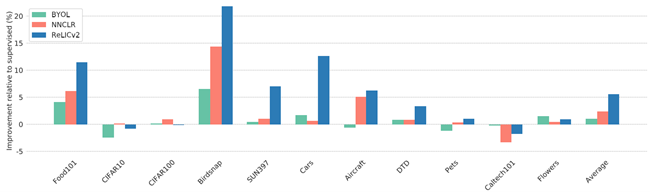
分类 团队对同一组分类任务进行线性评估和微调(Chen 等人,2020a;Grill 等人,2020 年;Dwibedi 等人,2021),并遵循补充材料中详细的评估方案。团队报告每个数据集的标准指标,并报告一个封闭测试集的性能。图2 比较了经过 BYOL(Grill et al., 2020)、NNCLR(Dwibedi et al.,2021)和 RELICv2 训练后表征的迁移性能。总的来说,RELICv2 改进了监督基线和竞争方法,在 11 个任务中有 7 个任务表现最好。RELICv2 在所有任务中显示出相对于有监督基线的平均提高超过 5%,是 NNCLR 的两倍。
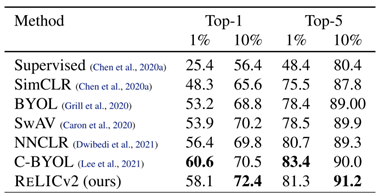
表2. Imagenet 上半监督学习 resnet50 的 top-1 和 top-5 正确率
为了进一步评估学习到的表示的通用性,团队通过微调来评估 RELICv2 在其他具有挑战性的视觉任务中的性能,更具体地说,是 PASCAL (和城市景观语义分割(Cordts 等人,2016)。根据(Heet al., 2019),团队使用 RELICv2ImageNet 表示来初始化一个全卷积网络,团队在 PASCAL train aug2012 集上对其进行了 45 个 epoch 的调整。在 PASCAL 和 cityscape上,RELICv2 的表现都明显优于 BYOL,在 PASCAL 上,RELICv2 的表现也明显优于专门为检测而训练的 DetCon。

鲁棒性和泛化性
团队评估了 RELICv2 表示在各种数据集上的鲁棒性和泛化性。为了评估 RELICv2 的鲁棒性,团队使用了 ImageNetV2(Recht 等人,2019)和 ImageNet-C 数据集。为了评估面向对象的泛化,团队使用了 ImageNet-R、ImageNet-Sketch 和 objectnet。在所有数据集上,团队使用带标签的 ImageNet 训练集在冻结的表示上训练一个线性分类器;测试评估采用零拍法,即不对上述数据集进行训练。RELICv2 学习了更鲁棒的表示,并在 ImageNetV2 和 ImageNet-C 上优于监督基线和竞争的自我监督方法。此外,RELICv2 学习的表示优于竞争的自监督方法,同时在泛化方面与监督方法的性能相当。
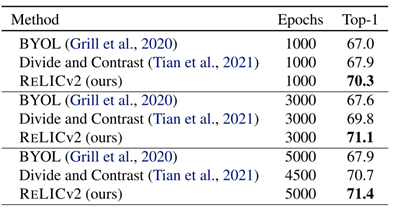
表3.JFT-300M 预训练的 Imagenet top-1 正确率
JFT-300M上的大规模迁移学习
接下来,团队使用 JFT-300M 数据集进行预处理,测试 RELICv2 对更大的数据集的适应性。JFT-300M 数据集包含 3 亿张图像——来自超过 18 k 个类。然后,按照 3.1 节中描述的线性评估协议,在 ImageNet 验证集上评估学习到的表示。团队将 RELICv2 与 BYOL 和 Divideand contrast(DnC)进行了比较,后者是一种专门设计用于处理大型和未组织的数据集的方法,代表了自我监督 JFT-300M 预训练的当前技术水平。表 3 报告了在 JFT-300M 上使用标准 ResNet50 架构作为骨干,对不同数量的 ImageNet 等效时代的各种方法进行训练时的 top-1 精度;实施细节可以在补充材料中找到。RELICv2 在 JFT 上训练 1000 个 epoch 时,比 DnC 提高了 2% 以上,在需要更少的训练 epoch 的情况下,获得了比竞争方法更好的整体性能。
分析讨论
隐空间分析
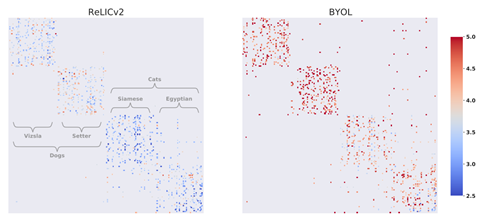
为了理解损失函数中显式不变性项对 RELICv2 学习的表示的影响,团队研究了密切相关类学习的表示之间的距离。图3 展示了 RELICv2 和 BYOL在ImageNet 上使用第 3 节描述的协议学习的最近邻表示之间的欧几里德距离。在这里,团队挑选了两种狗和两种猫。这四个类中的每一个都有 50 个从 ImageNet 验证集中关联的点,顺序是连续的。每一行代表一幅图像,每一行中的每个彩色点代表该图像表示的五个最近邻居中的一个,其中颜色表示图像与最近邻居之间的距离。与底层类结构完美匹配的表示形式将呈现出完美的块对角结构;也就是说,它们最近的邻居都属于同一个底层簇。团队看到 RELICv2 学习的表征,其最近的邻居更接近,并且比 BYOL 在类和超类之间表现出更少的混淆。
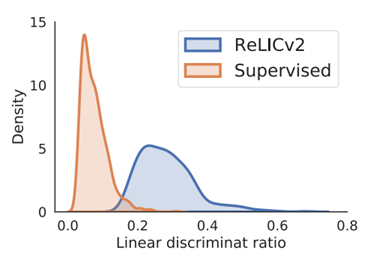
图4. 线性判别比的分布
为了量化学习潜空间的整体结构,团队检查了所有类的类内和类间距离。图4 比较了 RELICv2 学习到的 ImageNet 验证集中的点表示的类间和类内 2-距离的比率分布,以及通过监督基线学习到的点表示的类间和类内 2-距离的比率分布比例越大,意味着表征越集中在相应的类中,类之间越容易分离,因此更容易线性分离【c.f. Fisher 的线性判别器(Friedman et al., 2009)】。团队发现,与监督基线相比,RELICv2 的分布向右移动(即有更高的比率),这表明使用线性分类器可以更好地分离表示。
尺度分析
图5 显示了使用 RELICv2 学习的表示形式获得的 ImageNet 线性评估精度,它是使用 ImageNet 训练集进行前训练时看到的图像数量的函数。可以看出,为了达到 70% 的精度,ResNet50 模型需要大约两倍于 ResNet295 模型的迭代次数。ResNet295 的参数量约为 ResNet50 的 3.6 倍(分别为 87 M 和 24 M)。这一发现与其他研究结果一致,即大型模型具有更高的样本效率。
消融分析
之前工作的两个主要区别(Mitrovic 等人,2021 年;2020 年)和 RELICv2 是利用多茬作物和显著性掩蔽。在这里,团队在 ResNet50 上使用 top1 ImageNet 验证集在线性评估协议下的性能来消除这些技术的使用。总之,从 RELIC(74.3%)开始,通过添加多作物,团队获得了+2.5%,通过添加显著性掩蔽,团队获得了+0.3%,最终的 RELICv2 性能为 77.1%。
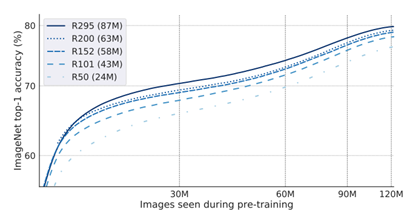
图5. Imagenet 正确率与预训练样本量之间的关系
裁剪 RELIC(Mitrovic 等人,2021)使用 2 种大小为 224*224 的裁剪视图。(Caron et al.,2020)建议使用 2 种大小为 224*224 和 6 种大小为 96*96 的裁剪。在这里,团队只使用标准的 SimCLR 增强来减少不同数量的大型和小型裁剪的使用。
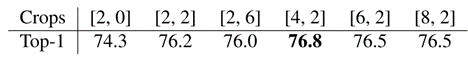
团队发现,使用多裁剪显著改善了 RELIC 基线的结果。然而,团队观察到,使用更少的大型裁剪比(Caron 等人,2020 年)提出的方法效果更好。
显著性遮挡 在训练过程中,团队在多裁剪上应用显著性蒙版,使团队能够学习专注于图像语义相关部分的表示,即前景对象,并对背景变化更鲁棒。团队报告了在 ImageNet 上对训练过程中去除背景的不同概率 pm 进行线性评估的 top-1 准确度。
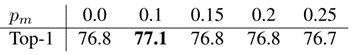
有 10% 的概率使用显著性掩码可以获得最佳性能,并比不使用掩码(pm = 0)有显著改善。此外,团队还探索了使用不同的数据集来训练 DeepUSPS(Nguyen 等人,2019),以无监督的方式获得显著性掩码。
总而言之,RELICv2 第一次证明了在不使用标签的情况下学习的表征可以在 ImageNet 上持续地超越强大的、有监督的基线模型。在使用 ResNet50 作为编码器进行类似比较时,RELICv2 代表了相对于当前技术水平的重大改进。
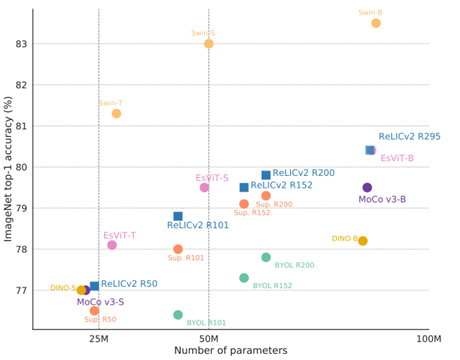
图6.RELICv2+ResNet 与 ViT 等模型的对比
最后,视觉 transformer(ViTs)已经成为视觉表征学习中最有前途的架构方案。图6 比较了最近基于 ViT 的方法和使用各种大规模 ResNet 架构的 RELICv2。值得注意的是,RELICv2 优于 DINO 和 MoCov3 ,并且在参数数量大致相同的情况下表现出与 EsViT 相似的性能,尽管这些方法使用了更强大的架构和更复杂的训练过程。将 RELICv2 与最近的架构创新相结合,可能会进一步改进视觉表征学习的性能】。

关于【数据实战派】

热门视频推荐
更多精彩视频,欢迎关注学术头条视频号

AI“双子星”同日联动:DeepMind加速编程自动化,OpenAI新方法解开2道国际奥数题
winter
【学术头条】持续招募中,期待有志之士的加






