刷新SOTA!Salesforce提出跨模态对比学习新方法,仅需4M图像数据!

文 | 子龙
多模态已经不是一个新鲜的话题,如何在一个模型中融合CV和NLP的信息同时吸引了两个领域的目光(CV、NLP的会都能投),但是很容易就能想到,来自图片的视觉特征和来自语料的文本特征来自不同的模型,所隐含的信息很难放到同一个隐状态空间中,于是特征融合Fuse成为众多模型所关注的重点。与此同时,多模态的初衷是通过描述相似对象的语料和图片互相促进,进而提升效果,那么怎么才能获得“描述相似对象”的标注呢?这又是多模态面临的另外一个问题特征对齐Align。
今天的文章 Align before Fuse: Vision and Language Representation Learning with Momentum Distillation 探索了如何解决多模态中极为重要的两个问题,作者通过图片-文本对比学习、图片-文本匹配、掩码语言模型,三个预训练任务,并提出动量蒸馏Momentum Distillation对抗数据噪音、改进训练过程,在多个任务上刷新了SOTA。
论文题目:
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
论文链接:
https://arxiv.org/abs/2107.07651
![]() 介绍
介绍![]()
 介绍
介绍这片文章开宗明义,题目中就涵盖了文章的重点:对齐Align+融合Fuse,正是多模态所关注的重点,作者将模型称作ALBEF(ALign BEfore Fuse),即现将相关的部分“对齐”,再进行融合。
具体模型如下图:
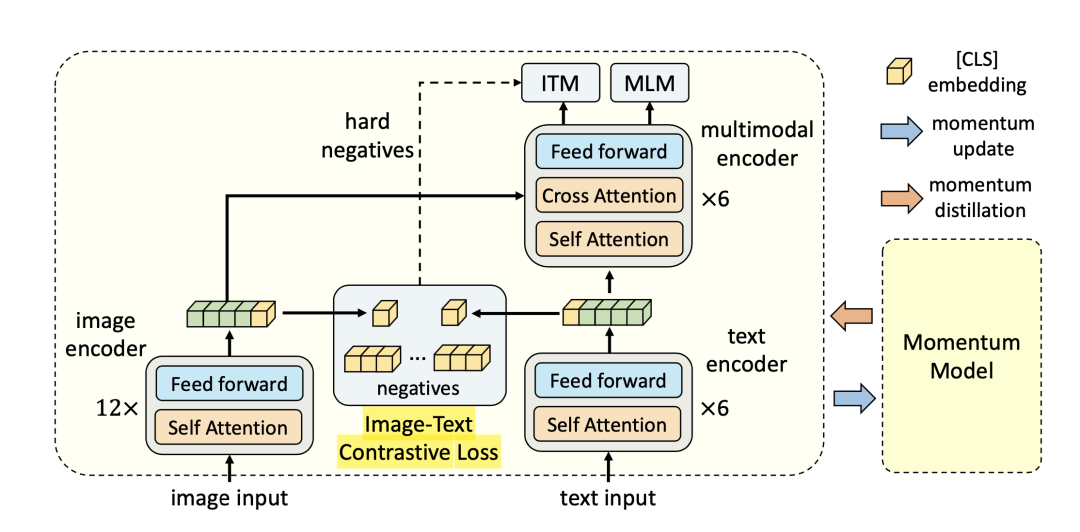
从图中可以清晰地看到模型的结构,图片和文本分为“双流”分别处理。这里为了减小图片特征和文本特征的差异,作者采用基于Transformer的ViT提取图片特征,而不是传统的基于CNN的模型,这也得益于最近CV届对Transformer解决视觉问题对探索。作者在文本方面依旧采用了颇为传统的BERT,有趣的是原本12层的BERT在这里做了分割,前6层作为单模态处理阶段(text encoder),后6层放到了多模态处理阶段(multimodal encoder)。在多模态处理阶段,文本每层先通过self-attention,再通过cross-attention和视觉特征相融合。
模型结构并不复杂,都是我们十分熟悉的结构,但是作者基于这样简单的结构配合多种预训练任务,使得模型中多模态任务上有着出色的表现。
动量模型Momentum Model
首先是“动量模型”,乍一看这个名称十分新奇,是标题中所谓“动量蒸馏”的一部分。在知识蒸馏中,有两个角色:“教师”和“学生”,核心目的就是让学生模型模仿教师模型,得到相似的结果,而学生模型往往相比教师模型有着不少优越性,比如更少的参数、更快的速度等等。教师模型有多种,较为直观的是教师模型选择庞大的预训练模型,而学生模型选择小而快的模型,而本文中采用了另外一种“在线自蒸馏(online self-distillation)”的蒸馏方法,将训练过程中的学生模型作滑动平均作为教师,这样能够有效对抗数据集中的噪音,因为此时的教师模型作为多个模型的集成,能够更好地对抗噪声。
图片-文本对比学习(ITC)
这里的“对比学习”是为了让图片和文本更好地对应,实现方法是通过给定文本特征或者视觉特征,再给定若干另外一种特征,在其中选择与之对应的那一个,“正样例”相对简单,即为数据集中的图片-文本对,那么如果得到“负样例”呢?这里作者维护了一个大小为M的“队列Queue”,储存动量模型最新得到的M个特征(因为动量模型是随着训练步数,逐步迭代更新的)。两个特征之间的相似度或者评分 通过向量点乘计算。
标记本身模型得到的视觉特征为 、文本特征为 ,动量模型得到的第m个视觉特征为 、文本特征为 。
其中 与 分别为one-hot label,即唯一的正样例为1,其余负样例为0, 是交叉熵。
掩码语言模型(MLM) 与 图片-文本匹配(ITM)
这两个预训练任务比较简单。掩码语言模型由BERT提出,将部分单词mask,并通过上下文预测其原本单词。
其中 为mask后的文本特征, 是one-hot label,长度等于单词表,mask对应的单词位置为1,其余为0。
图片文本匹配与图片文本对比学习目的类似,不同点在于,这里是通过多模态阶段(multimodal encoder)的[CLS]输出,预测当前输入的图片和文本是否匹配,即一个二分类问题。
动量蒸馏Momentum Distillation
本文所采用的预训练数据集来自网络,图片-文本对本身充满噪音,结果导致所谓的“正样例”中文本与图片相关度不高,而所谓的“负样例”有一定概率文本和图片有一定相似度。于是,为了对抗数据集中的噪声,作者提出动量蒸馏,动量蒸馏的核心是上文已经介绍过的动量模型,动量模型的结果也在图片-文本对比学习中用到,但是作者进一步地将动量模型的结果运用于损失函数中。
可以看出,在图片-文本对比学习中,交叉熵函数实际上在将图片-文本相似度的分布 与ground truth 相拟合,在掩码语言模型中,交叉熵函数实际上在将掩码后的多模态特征 与groud truth 相拟合。但是,正如文章分析的,训练数据存在噪声,这里所谓的ground truth并不完美,于是作者利用从动量模型中得到的分布完善原本的图片-文本相似度分布和掩码多模态特征分布。
首先需要得到动量模型中的分布,作者采用了十分简单的方法,用动态模型各个特征归一化,代替原本模型的特征计算概率分布。在图片-文本对比学习中,动量模型特征的分布如下计算:
其中只将 改为 ,这里新的 中,归一化后的动量模型输出特征取代了原本模型得到的特征。新的损失函数为:
和图片-文本对比学习类似, 是动量模型预测掩码单词的概率分布,新的损失函数为:
其中KL为KL散度。
![]() 实验
实验![]()
介绍完模型,接下来看看模型的表现,ALBEF共完成了Image-text Retrieval、Visual Entailment、Visual Question Ansering、Natural Language for Visual Resoning、Visual Grounding五大任务,每个任务上,ALBEF都取得了SOTA的好成绩,由于篇幅有限,这里着重介绍Visual Grounding。
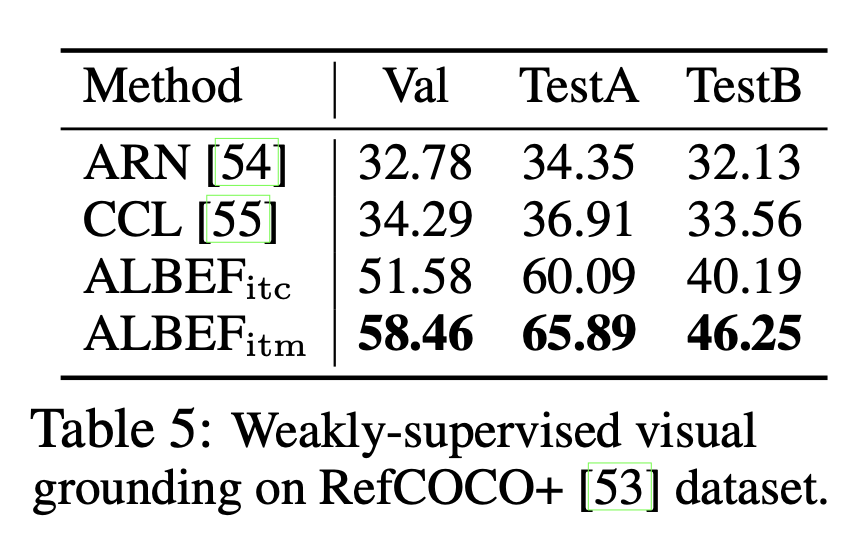
Visual Grounding需要模型根据一段文字描述定位图片中的某个区域,先通过图片直观感受一下ALREF的强大!

从图片中可以看出,文字和需要对应的部分匹配的十分准确,从预测正确的准确率我们也可以看出ALBEF遥遥领先,各个不同的场景下超出baseline 20%~30%多准确率。
![]() 小结
小结![]()
可见,先对齐再融合的思路符合多模态任务的需求,让模型能够更好的利用多模态的信息,这解释了ALBEF在诸多多模态理解任务中的出色表现,同时从Visual Grounding任务中可以看出,ALBEF提出的预训练任务确实使得模型学会了图片信息和文本信息的对应关系,这也为后续研究提供了启发。
萌屋作者:子龙(Ryan)
本科毕业于北大计算机系,曾混迹于商汤和MSRA,现在是宅在UCSD(Social Dead)的在读PhD,主要关注多模态中的NLP和data mining,也在探索更多有意思的Topic,原本只是贵公众号的吃瓜群众,被各种有意思的推送吸引就上了贼船,希望借此沾沾小屋的灵气,paper++,早日成为有猫的程序员!
作品推荐:
 萌屋作者:子龙(Ryan)
萌屋作者:子龙(Ryan)
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【



