7 Papers & Radios | Stable Diffusion采样速度翻倍;MIT解决神经网络百年难题
机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周重要论文包括清华大学朱军教授 TSAIL 团队提出的 DPM-Solver 和 DPM-Solver++ 将扩散模型的快速采样算法提升到极致;MIT 提出的快速高效新型人工智能算法 CfC 实现类似于人脑的神经模拟,速度快且成本低。
目录:
Closed-form Continuous-time Neural Networks
Learning to Explore Distillability and Sparsability: A Joint Framework for Model Compression
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Galactica: A Large Language Model for Science
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
AI and ML Accelerator Survey and Trends
Large-batch Optimization for Dense Visual Predictions
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Closed-form Continuous-time Neural Networks
作者:Ramin Hasani等
论文地址:https://www.nature.com/articles/s42256-022-00556-7
摘要:随着神经元数量的增加,人工智能模型的训练和计算成本都变得非常高昂。有没有一种模型能够既实现类似于人脑的神经模拟,又速度快成本低呢?MIT 的「liquid」神经网络团队发现了缓解这一瓶颈的方法,即求解两个神经元通过突触相互作用背后的微分方程。
基于此,他们提出了一种快速高效的新型人工智能算法 CfC(closed-form continuous-depth networks),其具有与 liquid 神经网络相同的特征——灵活性、因果性、鲁棒性和可解释性——但速度更快,且可扩展。

推荐:解决神经网络的百年难题,MIT 新模型 Liquid CfC 让模拟大脑动力学成为可能
论文 2:Learning to Explore Distillability and Sparsability: A Joint Framework for Model Compression
作者:Yufan Liu 等
论文地址:https://ieeexplore.ieee.org/abstract/document/9804342
摘要:面对越来越深的深度学习模型和海量的视频大数据,人工智能算法对计算资源的依赖越来越高。为了有效提升深度模型的性能和效率,通过探索模型的可蒸馏性和可稀疏性,本文提出了一种基于 “教导主任 - 教师 - 学生” 模式的统一的模型压缩技术。
该成果由人民中科和中科院自动化所联合研究团队合作完成,相关论文发表在人工智能顶级国际期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 上。该成果是首次将 “教导主任” 角色引入模型蒸馏技术,对深度模型的蒸馏与裁剪进行了统一。
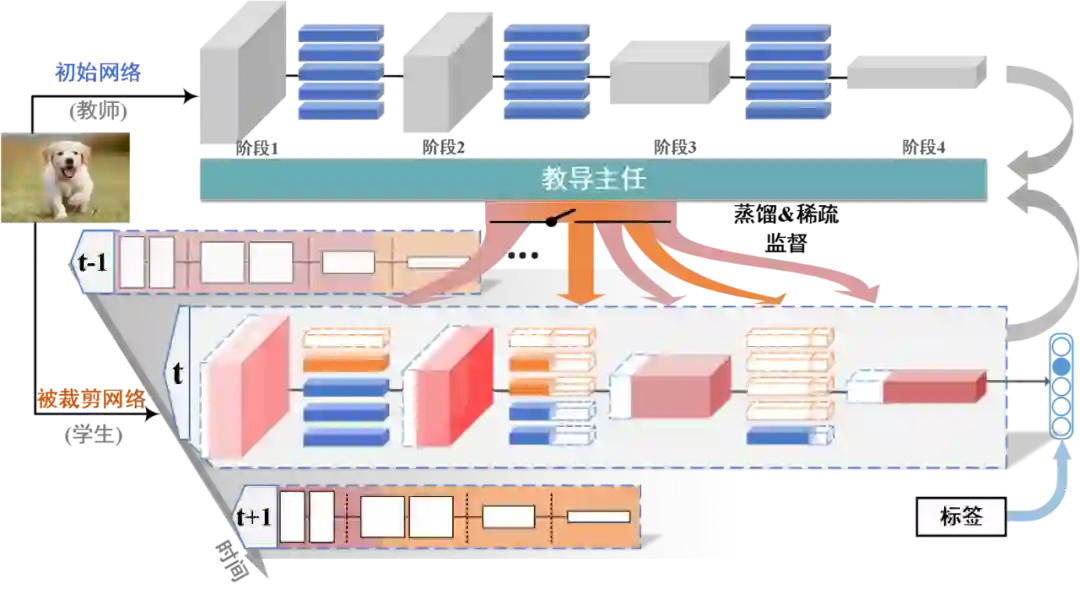
基于可蒸馏性与可稀疏性联合学习的模型压缩算法示意图。
推荐:首次将「教导主任」引入模型蒸馏,大规模压缩优于 24 种 SOTA 方法。
论文 3:InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
作者:Wenhai Wang 等
论文地址:https://arxiv.org/pdf/2211.05778.pdf
摘要:浦江实验室、清华等的研究人员提出了一种新的基于卷积的基础模型 InternImage,与基于 Transformer 的网络不同,InternImage 以可变形卷积作为核心算子,使模型不仅具有检测和分割等下游任务所需的动态有效感受野,而且能够进行以输入信息和任务为条件的自适应空间聚合。InternImage-H 在 COCO 物体检测上达到 65.4 mAP,ADE20K 达到 62.9,刷新检测分割新纪录。
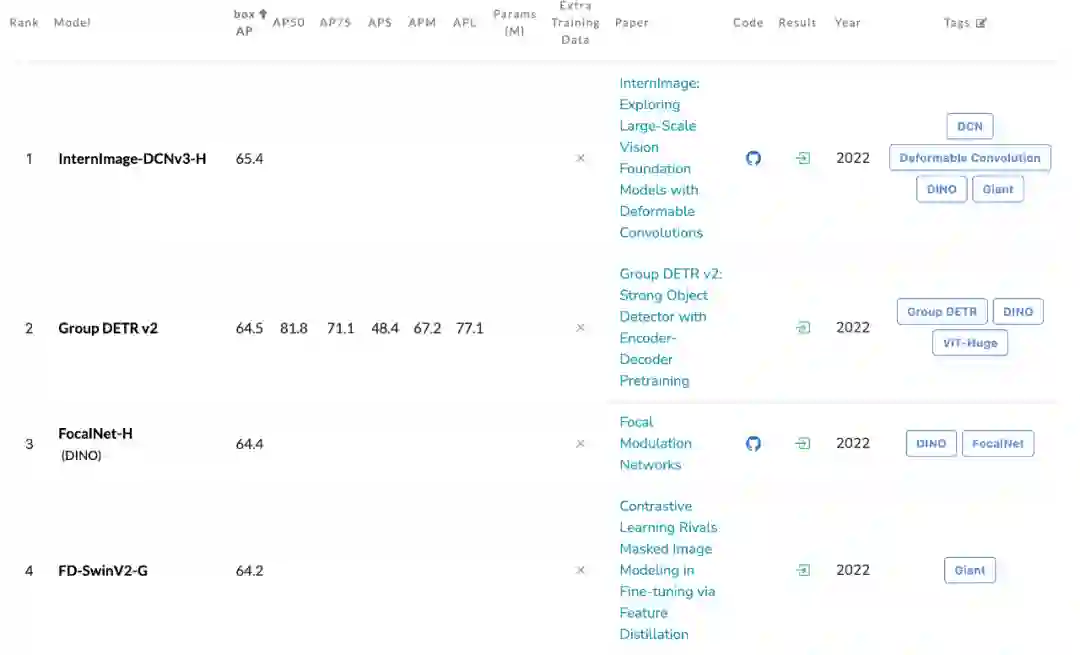
推荐:用 CNN 做基础模型,可变形卷积 InternImage 实现检测分割新纪录。
论文 4:Galactica: A Large Language Model for Science
作者:Ross Taylor 等
论文地址:https://galactica.org/static/paper.pdf
摘要:近年来,随着各学科领域研究的进步,科学文献和数据呈爆炸式增长,使学术研究者从大量信息中发现有用的见解变得越来越困难。通常,人们借助搜索引擎来获取科学知识,但搜索引擎不能自主组织科学知识。现在,Meta AI 团队提出了一种新的大型语言模型 Galactica,可以存储、组合和推理科学知识。
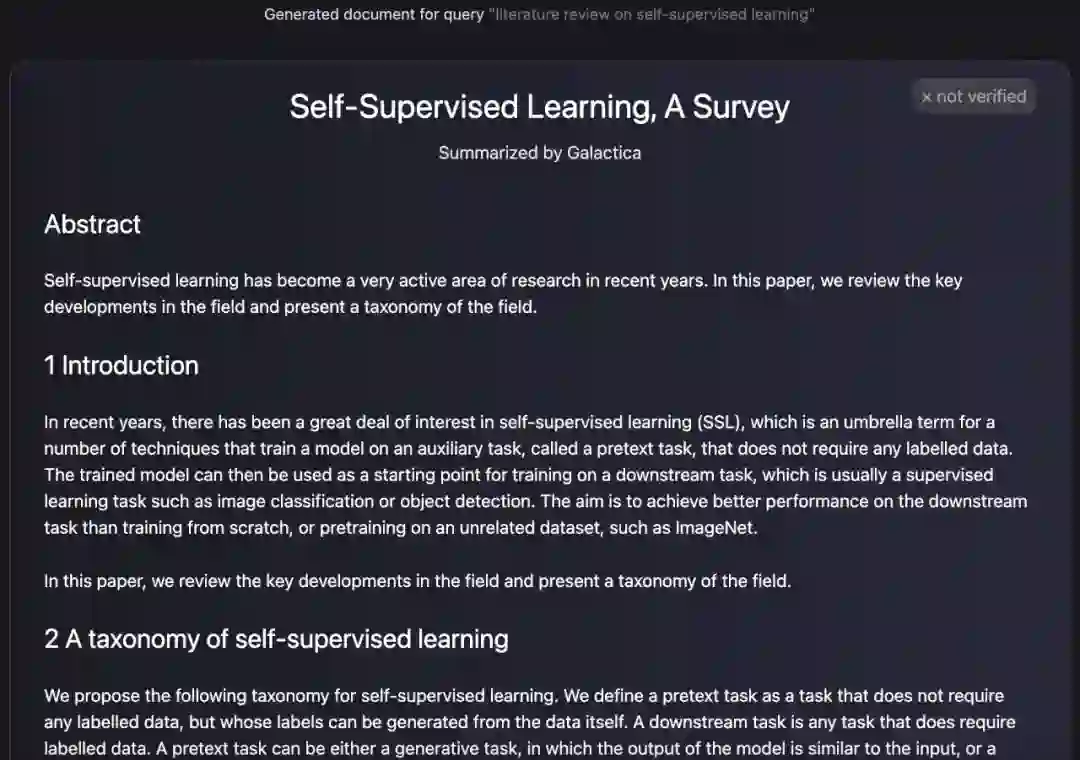
推荐:大模型能自己「写」论文了,还带公式和参考文献。
论文 5:DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
作者:Cheng Lu 等
论文地址:https://arxiv.org/pdf/2211.01095.pdf
摘要:清华大学计算机系朱军教授带领的 TSAIL 团队提出 DPM-Solver(NeurIPS 2022 Oral,约前 1.7%)和 DPM-Solver++,将扩散模型的快速采样算法提升到了极致:无需额外训练,仅需 10 到 25 步就可以获得极高质量的采样。
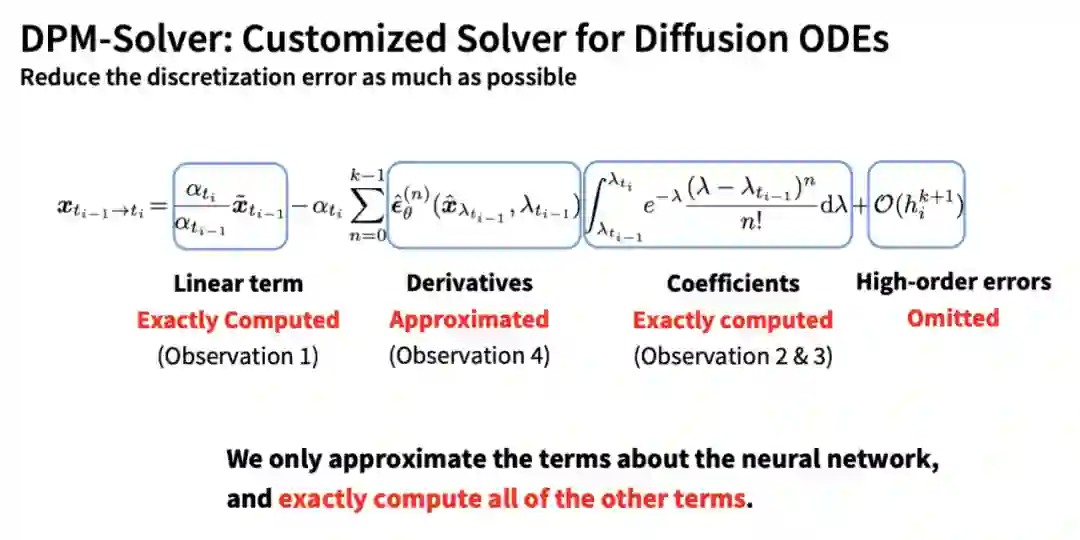
推荐:Stable Diffusion 采样速度翻倍!仅需 10 到 25 步的扩散模型采样算法。
论文 6:AI and ML Accelerator Survey and Trends
作者:Albert Reuther 等
论文地址:https://arxiv.org/pdf/2210.04055.pdf
摘要:本文关注深度神经网络和卷积神经网络的加速器和处理器,它们的计算量极大。本文主要针对加速器和处理器在推理方面的发展,因为很多 AI/ML 边缘应用极度依赖推理。本文针对加速器支持的所有数字精度类型,但对于大多数加速器,它们的最佳推理性能是 int8 或 fp16/bf16。
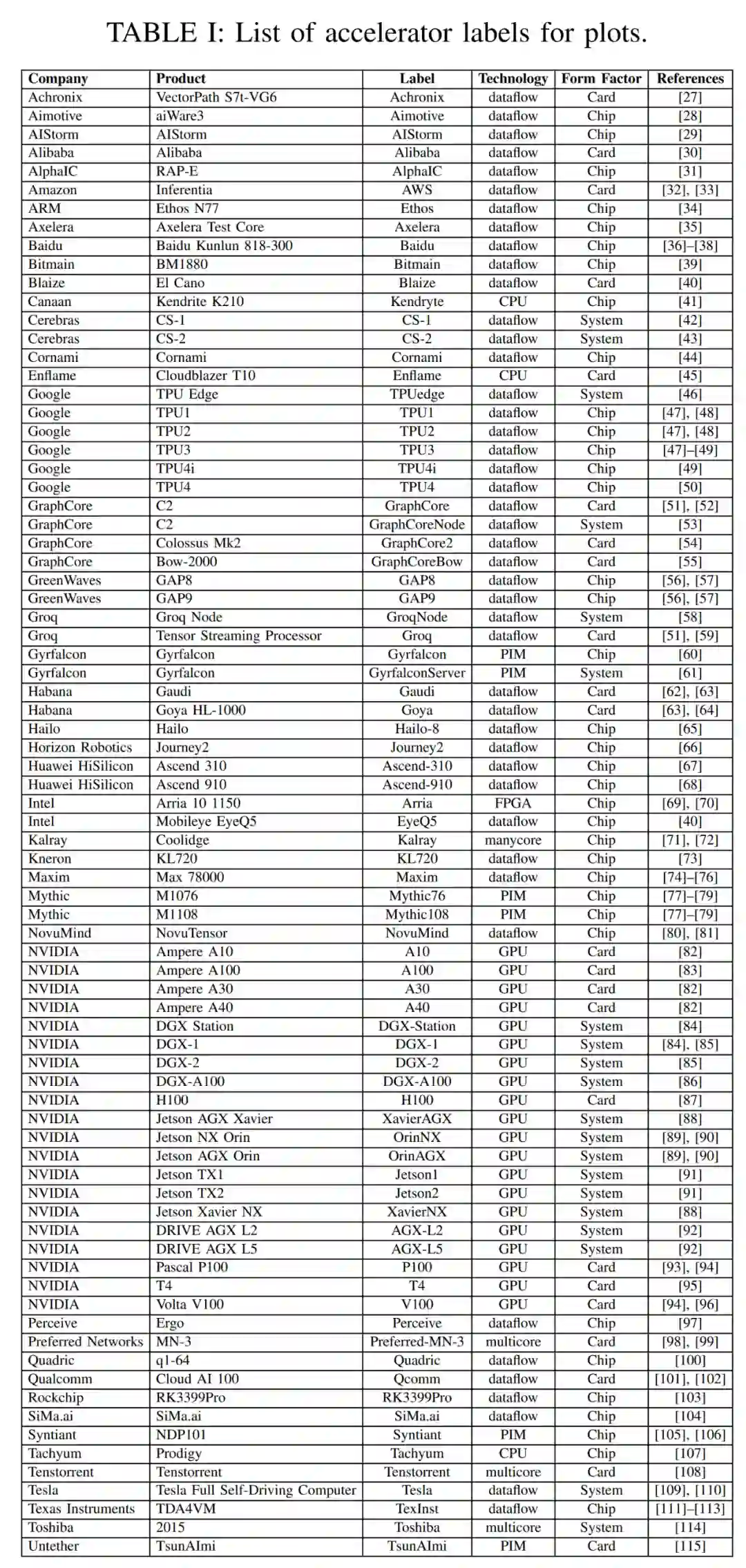
表 1 中总结了加速器、卡和整体系统的一些重要元数据。
推荐:总结过去三年,MIT 发布 AI 加速器综述论文。
论文 7:Large-batch Optimization for Dense Visual Predictions
作者:Zeyue Xue 等
论文地址:https://arxiv.org/pdf/2210.11078.pdf
摘要:本文提出了一种大批量训练算法 AGVM (Adaptive Gradient Variance Modulator),不仅可以适配于目标检测任务,同时可以适配各类分割任务。AGVM 可以把目标检测的训练批量大小扩大到 1536,帮助研究人员四分钟训练 Faster R-CNN,3.5 小时把 COCO 刷到 62.2 mAP,均打破了目标检测训练速度的世界纪录。论文被 NeurIPS 2022 接收。
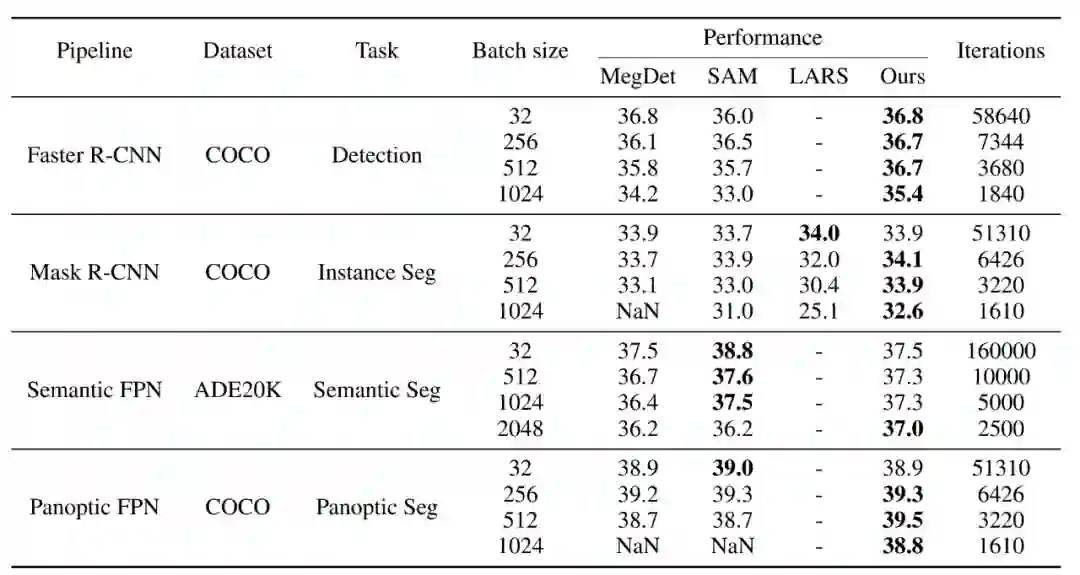
详细对比 AGVM 和传统方法,体现出了本研究方法的优势。
推荐:四分钟内就能训练目标检测器,商汤基模型团队是怎么做到的?
本周 10 篇 NLP 精选论文是:
本周 10 篇 CV 精选论文是:
本周 10 篇 ML 精选论文是:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com




