竞赛方案|VideoNet视频内容识别挑战赛
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:阿水 https://zhuanlan.zhihu.com/p/79563696 来源:知乎,已获作者授权转载,禁止二次转载。
上个月主要抽时间认真做了下由极链科技组织的VideoNet视频内容识别挑战赛,由于自身工作和视频数据有点关联,于是报名参加了本次比赛。但是由于时间和机器等原因的限制,最后的成绩才22名,本文将会介绍本次比赛和相应的解决方案。

1 比赛介绍
视频中存在着大量的物体、场景等多维度内容信息,这些维度内容之间又存在着广泛的语义联系。近年来,随着深度学习技术的发展,涌现出大量针对物体、场景、人脸、动作等维度的识别技术,在各自的目标维度上取得了明显的进步。但是目前各视频识别算法基本都是针对单一维度来设计的,无法利用各维度之间存在的丰富的语义关联建立模型,提高识别准确度。当前也缺乏一个包含多维度标注的大规模视频数据集来为多维度视频识别算法研究提供训练测试数据支持。
为了推动物体、场景等多维度视频内容识别在人工智能与视频产业中的应用,极链科技联合复旦大学共同推出了大规模多维度标注视频数据集VideoNet,并以此为基础举办首届“VideoNet视频内容识别挑战赛”。VideoNet包含近9万段视频,总时长达4000余小时。VideoNet数据集对视频进行了事件分类标注,并针对每个镜头的关键帧进行了场景和物体两个维度的共同标注,充分体现了多维度内容之间的语义联系。鼓励参赛者利用视频的时间维度特征和场景、物体、视频类别等多维度之间的联系开展算法设计。通过本次比赛,我们希望相关领域研究者积极参与到基于VideoNet的多维度视频内容识别研究与挑战中来,促进多维度智能识别技术在视频产业中的发展和落地。

1.1 比赛数据
比赛数据集VideoNet包含约300类视频,约200类场景和200类物体,总视频数超过7万。其中60%作为训练集,20%作为验证集,20%作为测试集。总共视频数据大小约1.5T,数据量非常大。
比赛数据具体包括由三个部分组成:视频对应的类别、场景和物体标注。数据集中每个视频属于一个视频类别,每一个关键帧属于一个场景类别,每一个关键帧有对应的物体标注信息。此外每段视频用镜头分割方法做镜头切分预处理,将视频分成由单一镜头组成的多个片段。视频的关键帧是每个镜头内的所有帧进行图像质量评估,取质量最好的一帧作为该镜头的采样帧,记录其帧号,并对其进行物体、场景维度的标注。
{"videoid" : "video001", //视频名称"videoclass" : "3Dprint", //视频事件类别"shots": //镜头[{"keyframe" : 30, //关键帧号"startframe" : 20, //镜头起始帧"shotlength" : 100, //镜头长度"targets":[{"category" : 0, //样本分类 0表示物体,1表示场景"tag" : 157, //样本对应标签id"bbox" :{ //标注的boundingbox"height" : 154,"width" : 258,"x" : 385,"y" : 111}},
1.2 比赛评分
由于比赛数据由三部分标注组成,比赛评分也包括三个部分:视频内容的三个维度(视频类别、物体、场景)同时进行识别,评测指标为三个维度识别准确率的加权。
视频类别:对给定的测试视频样本,推断其所属视频类别,使用分类准确率评分;
场景识别:对给定的测试视频样本及镜头分割和镜头关键帧结果,推断每个镜头的关键帧对应的场景类别,使用分类准确率评分。
物体识别:对给定的测试视频样本及镜头分割和镜头关键帧结果,推断每个镜头的关键帧对应的物体类别和位置,使用识别IoU-0.5阈值的准确率。
最终的准确率组成:0.2*视频类别精度+0.4*场景类别精度+0.4*物体识别精度
赛题数据有一个关键点视频的关键帧不一定属于场景和物体,也就是说关键帧可以有场景类别、有物体信息,也可以没有任何信息。那么如何判断视频关键帧不属于任何类别,也不包含任何物体呢?这个就是参赛选手需要解决的了。
2 官方Baseline
由于包括三个任务,举办方为了让选手快速入门比赛还公开了一份baseline方案。baseline方案中将三个任务分开进行解决,视频类别预测使用视频分类模型,场景识别使用场景分类模型,物体识别使用物体分类模型。
视频类别任务:使用Temporal Segment Network模型进行分类,线上精度为78.17%;
场景识别任务:使用PlaceCNN模型进行分类,线上精度为55.29%;
物体识别任务:使用YOLO3模型进行识别,线上精度为23.42%;
由于有一些关键帧是不属于任何场景和物体标签的,所以在场景识别和物体识别任务中,baseline的代码是通过阈值的方法进行选取的。
3 解决方案
从baseline的解决方案可以看出三个任务可以分开进行求解的,因此我也将三个任务分开进行求解。同时由于三个任务在评分上不同的权重,且baseline给出的视频类别任务的精度已经很高了,所以我主要将精力放在场景识别任务和物体识别任务上。
3.1 场景识别
图片的场景识别是也是一个图像分类问题,有对应的Place365等场景识别数据集。场景识别问题本质是一个图像分类问题,但难度比传统的图像分类问题难。设计一下图片的场景一般体现在环境和背景,并没有很突出的形状和纹理;而传统的图像分类(如ImageNet的物体分类问题)的图片在语义上往往更加突出一些,比如狗和猫,在纹理和形状上差异都比较大。
在VideoNet比赛中场景识别共有205类,类别分布情况如下:
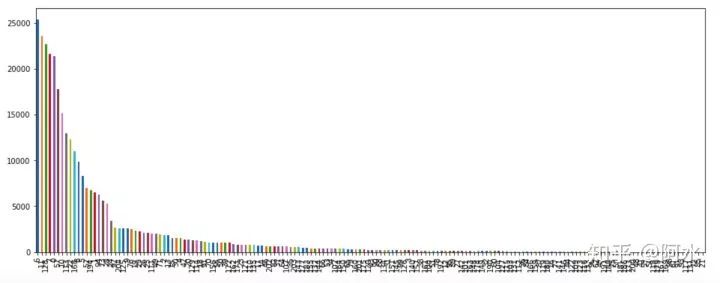
显然这是个不均衡的分类问题,此外还有一些图片不属于任何类别的情况。在场景识别任务主要需要解决以下两个问题:
如何判断一张图是否属于205类其中一种,还是不属于其中任何一类?
如何改善模型对不均衡类别的分类精度?
第一个问题是非常实际的一个分类问题,如果图片不属于训练集中的任何一类,模型还能分类正确吗?在baseline中是通过卡阈值的方法进行解决,模型输出的概率虽然有一定的置信度,但也有一定的随机性。其实可以将不属于数据集类别的图像视为单独的一类,将场景识别从205类扩充为206类。通过此种方法可以充分利用所有样本的信息,增加模型的泛化能力,在测试集上直接这样改进会带了5%的精度提升。场景分类精度从55.29%提高至60%左右。
接下来解决第二个问题,样本不均衡的情况。样本不均衡是非常常见的情况,主要有以下一种解决方法:1-收集样本改善分布情况;2-使用Focal loss;3-对样本数据进行采样。在分析了VideoNet数据集和Place365数据集的类别标签后,我发现这两个数据集样本类别存在交叉情况,因此利用Place365数据集来扩充训练样本。Focal loss会更加稳定,但在分类精度上没有很大改善,同时对某些类别进行了上采样操作。
在原始baseline中,数据预处理如下:
# load the image transformercentre_crop = trn.Compose([trn.Resize((256,256)),trn.CenterCrop(224),trn.ToTensor(),trn.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
我为了增加数据样本的信息,将图像的尺寸扩大到原始尺寸:
transforms.Compose([transforms.Resize((360, 640)),transforms.RandomCrop((350, 600)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
由于比赛数据集量实在是太大,我将ResNet18来替换了ResNet50。在单机4卡的情况下10折训练还是要花费1天时间。通过上述改进,场景分类精度从60%提高至66%左右。
3.2 物体识别
物体识别也是典型的图像任务,在baseline中使用YOLO3来进行完成。自然场景下的物体识别比赛有COCO和Open Image,都是数据量比较大的。由于我之前没有认真参加过物体检测比赛(一方面是物体检测比较烧机器,另一方面物体检测领域发展太快了),这次我还是想认真参加的。
物体检测每年发展的比较快,state-of-art的模型在COCO的精度是每个季度都会被刷新,物体检测是视觉领域中重要的任务。物体检测非常考验工程能力,对机器也有较高的要求。如果你想参加物体检测相关的比赛,建议你阅读这篇博客。
链接:
https://baijiahao.baidu.com/s?id=1611471635767947365
整体而言物体检测比赛对基线模型的精度要求很高,需要选对合适的模型。在VideoNet这次比赛中,我最开始选择了GluonCV中的Faster-RCNN模型进行训练,经过一天训练后,我发现验证集上只有前几十个类别的mAP正常。经过多方查找,发现GluonCV框架中检测模型最大支持的自定义类别数不能超过COCO的类别,坑爹😂
后来我就改用mmdetection框架来训练,训练速度非常快。我初步对比了下mmdetection训练速度比GluonCV快20倍,比原生Caffe快200倍左右。具体的config文件修改如下:
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)data = dict(# 每张卡图片数量imgs_per_gpu=25,workers_per_gpu=1,train=dict(type=dataset_type,ann_file=[data_root + 'VOC2007/ImageSets/Main/train.txt',],img_prefix=[data_root + 'VOC2007/'],# 修改为原始图像下载img_scale=(640, 360),img_norm_cfg=img_norm_cfg,size_divisor=32,flip_ratio=0.5,with_mask=False,with_crowd=True,with_label=True),
在mmdetection框架下我尝试以下两个模型:
faster_rcnn_r50_fpn_1x_voc0712:线上精度为42%;
cascade_rcnn_x101_32x4d_fpn_1x:线上精度为46%;
由于训练周期比较长,在单机多卡的情况下物体检测训练20个epoch需要三天的时间,我也没有继续进行训练和尝试新的模型。
4 比赛总结
首先由于时间、机器硬件的原因,我在本次比赛不能反复迭代和尝试新的想法。所以导致我的成绩与前排选手差距较大。当然这也与我个人精力有关,确实工作比较忙,没有很多时间去尝试新想法。
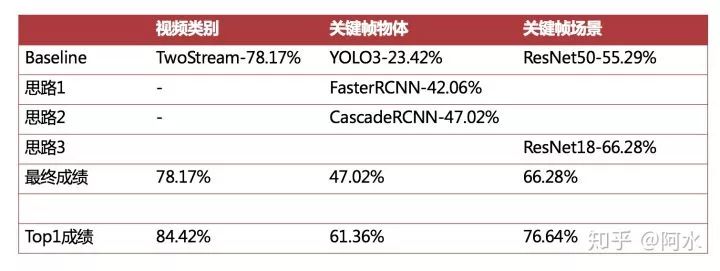
最后来复盘物体检测和场景识别两个任务,我认为我与前排选手的差距主要在以下几个方面。
关键帧物体检测任务:
与第一名相差14个点,主要差距在于模型精度和测试集TTA上。
我使用的是Cascade R-101-FPN模型,COCO精度41,而现有最优模型精度为48+;
我没有写测试集的TTA流程,没有加上多尺度预测和测试数据扩增;
关键帧场景识别任务:
与第一名相差10个点,差距在数据处理上,没有考虑相同镜头下关键帧的关系;
同一个镜头下的关键帧应该属于同一场景;
视频类别与关键帧场景存在关系;
如果你还想学习下检测的一些trick,可以阅读下mmdetecion的论文[1]。以上就是我对VideoNet比赛的总结,Have Fun!
[1] MMDetection: Open MMLab Detection Toolbox and Benchmark
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~


