利用自然语言检索百万视频,人物、场景、事件都不能放过,这就是既困难又吸引了众多研究者的视频检索任务。
紧随图像建模技术的提升,机器学习已经不再满足图像识别与检索了,它的「进阶版」视频理解通常不仅需要理解图像内容,同时还需要理解图像之间的联系。而视频目前是最形象与生动的信息载体,如果机器学习能理解视频,那么很多应用都会变得智能化。
例如这篇文章介绍的视频检索,我们只需要输入「Find shots of a person lying on a bed」这样的查询语句,模型就能在海量视频库中检索到对应的视频片段。这种任务的难度可比基于预输入标签的视频搜索难多了,因为视频片段的检索只能依靠视频内容。
近日,阿里安全图灵实验室视频理解团队获得了 TRECVID 2019 视频检索任务冠军。TRECVID 源自 NIST 等机构在 2003 年组织的视频检索项目,这么多年已经是非常成熟的挑战项目。每年 TRECVID 都吸引了 CMU 和微软等顶级研究机构,它代表着跨模态视频检索领域最前沿的研究方向。
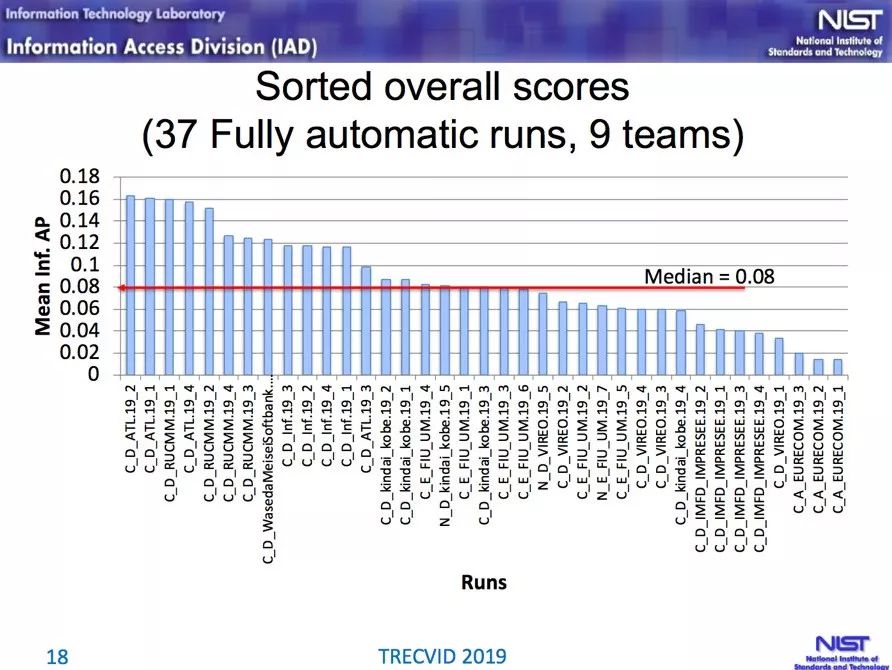
![]()
阿里安全图灵实验室视频理解团队 ATL 获得的评分最高,人民大学、软银等团队也有很好的成绩。选自:https://www-nlpir.nist.gov/projects/tvpubs/tv19.slides/tv19.avs.slides.pdf
本文将讨论这种困难的视频检索任务该怎么处理,并介绍阿里的冠军解决方案。这种跨模态模型不仅在视频检索领域,同时在更广泛的视频理解领域起着支柱作用。
阿里安全算法专家表示,这些经验累积能有效处理更多的视频业务,例如视频排查,即搜索并排查某类不合规的视频;视频分类,识别视频风险类型或者某些特性;视频标签与属性,理解视频以输出视频片段的各种标签,用于后续处理。
对于一项挑战任务,我们该做的第一件事就是理解数据集,了解它的输入与输出,理解它的种类与覆盖情况。后面才是根据数据调制解决模型,并验证效果。TRECVID Ad-hoc Video Search(AVS)任务给人的第一印象是,
它的测试数据很难、很多
;TRECVID AVS 模型给人的第一印象是,它的整体思路很容易想到,但要做到却很难。
TRECVID AVS 任务的数据真的很难,它的测试数据集有 1.3TB 大小、108 万+的视频片段。这样看起来它的测试集应该很公平,但问题在于
挑战赛并没有提供对应量级的训练集
。因此我们需要找额外的开放视频数据集,并尽可能提高模型的泛化性。
因为缺少训练集,这已经近似于 Zero-shot video search 任务了,它的难度非常高。阿里安全算法专家说:「从比较基本的角度来说,训练数据集在整个业界都比较匮乏,这是视频检索任务的难点。」
![]()
我们只能已知测试集的领域或来源大概可以分为四种,找开源数据也需要以这四类视频为目标。图像来源:https://www-nlpir.nist.gov/projects/tv2019/avs.html
虽然 TRECVID AVS 的数据很难,但它的输入与输出还是相对好理解的。该任务使用一句英文来搜索相关视频,例如「Find shots of exactly two men at a conference or meeting table talking in a room」,该语句可能包含物体、时间、动作、位置、人物等的组合。这样的任务要求算法不仅理解开放词汇的英文语句,还要准确搜索出其描述的视频。
研究者表示:「视频检索其实是业界的老问题,
给定一个查询意图 Query,我们需要在相当规模的视频数据库中查找满足意图的视频
。这样的 Query 可以是一个视频片段、一张图像,也可以是一个单词或完整的句子。因为查询意图可以是不同的模态,因此整个过程可以视为跨模态的视频检索问题。」
对于本次的视频检索挑战,与传统的基于内容检索的问题不同,后者需要预定义语义标签,而前者旨在建模用户的查询意图,查询的输入是任意意图自然语言,因此阿里算法专家说:「AVS 可以理解为
相似度匹配问题
,但模型不仅需要解决视觉方面的建模问题,还需要解决自然语言理解问题,并建立视觉与自然语言之间的映射关系,这就是它的另一个难点。」
视频检索任务是一个相似度匹配问题,业界已经有了广泛的研究。视频检索本身的难点在于大规模特征抽取、语义的泛化性,以及索引和查询的性能。这些都与模型架构的选取相关,我们希望以最少的成本搜索到最准确的结果。
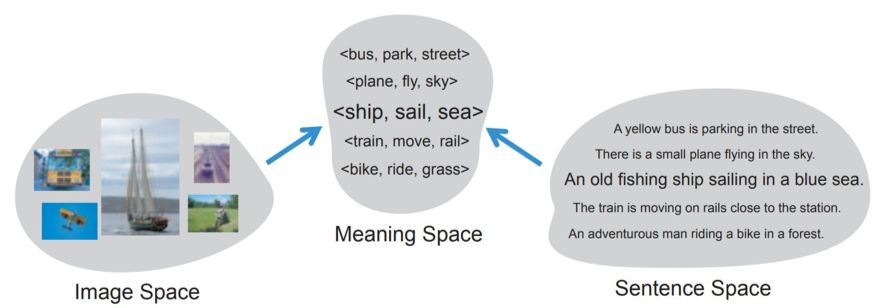
目前跨模态视频检索比较主流的架构是
找到一个新的共同空间
,我们只有将各种输入数据都映射到同一空间,这样才能进行匹配与对比。
![]()
最为主流的思路,使用不同的网络将视觉和语言信息同时映射到「语义空间」,然后在「语义空间」进行对比与检索。
当然除了这种架构,也有其它一些解决思路,阿里安全算法专家说:「我们也可以将视频这种
视觉信息转化为文本
,而不是转化为隐藏空间的特征向量。这就意味着我们先给视频打上不同的标签,然后将视频检索问题转化为文本检索任务,这也是比较有效的方法。」
第一种思路将视觉信息与自然语言信息映射到相同空间,是一种联合建模方法。而第二种思路相当于分别建模,即先建模视觉到自然语言这样的任务,再建模一个自然语言任务,它们从出发点就有一些不同。而且第二种方法是需要预定义标签,而第一种减少了这样的约束。
因为 TRECVID AVS 更倾向于探索跨模态前沿模型,所以阿里安全图灵实验室并没有在收集训练数据集上花很多时间,他们采用已有的公开数据集,期待测试方法的有效性。总体来说,训练集主要包含微软的 MSR-VTT 和雅虎的 Tumblr GIF 数据集,它们一共有 11 万视频片段、32 万条对应的自然语句。
这样的数据量其实并不大,研究者说:「测试集视频是百万级的,我们训练完的模型需要在这种大规模数据中完成检索,因此整个任务是非常困难的,尽管我们排名第一,但效果上还有很大的提升空间。」
阿里安全图灵实验室采用的思路是
将视频与文本映射到相同的高维空间,从而学习它们之间的关系
。研究者说:「因为视频和文本都是序列数据,所以我们特别优化了序列建模。这种序列建模不仅包括循环神经网络这种依时间步传递的方法,同时还包含图这种建模更远距离的方法。」
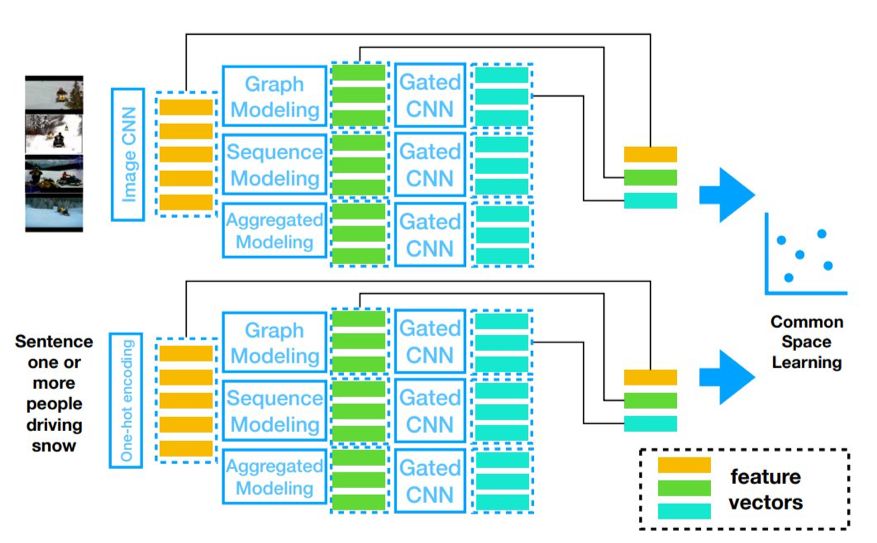
总体而言,研究者的混合序列模型可以分为视觉模块与文本模块两部分,它们能应用到图像帧与自然语句,并抽取嵌入向量。因为两类嵌入向量在公共的空间中,所以通过学习方法可以学习到它们之间的关系。
![]()
如上在研究者的工作中,他们主要关注优化视觉和文本序列建模方法。即采用了三种子模块来加强效果,
图卷积模型、序列模型和聚合模型
三者会通过一个控制门来确定它们各自对最终嵌入向量的贡献,控制门是一种自动调整策略。
两个模块都可以分为三级编码,首先第一级都是预训练模型,视频模块使用在 ImageNet-11k 上预训练的模型抽取视频图像特征,文本模块使用预训练的 Word2vec 对文本进行编码。
第二阶段的编码分别由图卷积、循环神经网络、聚合模型得出,它们相当于从不同的角度获取视频帧之间或词之间的相互依赖关系。最后第三阶段的编码则通过门控卷积网络挑战三类特征的重要性,并输出最终的嵌入向量。
「我们的创新点在于,优化了序列信息的抽取,例如我们使用基于图的这种序列表征方法,它不只关注视频帧或单词之间的关系,同时还能挖掘距离较远的依赖性关系。特别是视频数据,
它的情节或镜头是相互交替的,镜头会来回切换,只有这样的图模型才能很好地捕捉序列信息
。」研究者说。
前面介绍过视频除了用 LSTM 等循环网络建模,也可以用图神经网络建模,甚至它的建模效果还要更好。读者可能会想到,视频不就是图像帧按时间组成的序列么,为什么能建模成图?
假设现在输入数据是由预训练模型编码的一系列特征图(Feature Map),视频图建模的目的是将它们视为图(Graph),并用图卷积进行处理。具体而言,
每一帧的特征图都是一个节点,我们可以根据「时间」构建边,同时也可以根据视频帧之间的相似性构建边
。
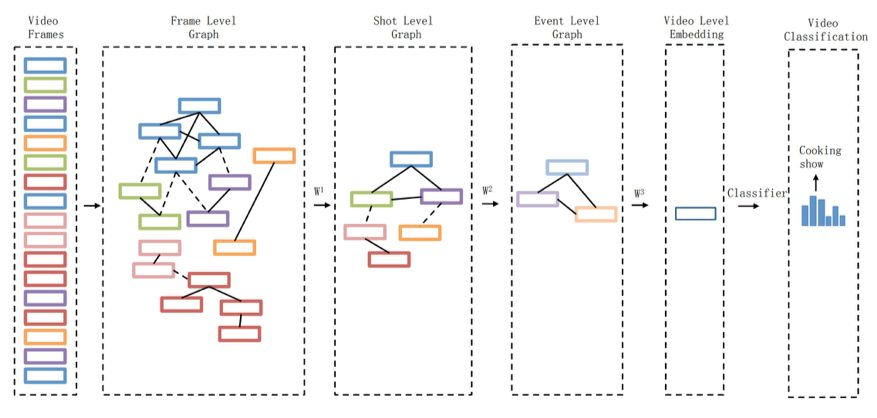
![]()
图注:视频帧序列依次构建视频帧级别、镜头级别和事件级别的图。选自 arxiv: 1906.00377。
视频帧序列是多级结构,因此图应该逐渐被抽象到更高层的拓扑。阿里用节点卷积和 3 种池化方法不断聚合视频帧图。每次节点卷积后,拓扑结构获得一次抽象,并且在新的拓扑上,模型可以传播新的节点特征,从而获得下一层级的图表达。最终的结果,阿里的方法比传统 RNN 效果要好,而且速度非常快,该技术可以用于其它序列建模问题上。
通过三大序列模型,抽取的特征并不能直接用于最后的计算,因为有一些视频并不需要利用全部三种特征。为此,研究者设计了一种门控卷积网络,它会
自动调整不同视频对不同特征类型的需求
。
阿里安全算法专家表示:「前面架构会把视频与自然语言映射到同一空间,并通过对比损失拉近相似视频与自然语言的距离,推远不相似视频与自然语言间的距离。」简单来说,最后抽取的两个特征向量可以通过余弦相似性计算距离,并迫使正确的视频-语言对彼此靠近。
虽然听起来很简单,但别忘了
视频片段的量级达到了百万
,即使简单算一个矩阵乘法,根据余弦相似性找到好的视频片段,这种大规模矩阵运算的计算量也不会小。所以说,对于最后的匹配或检索,计算效率也是非常重要的一件事。
对于视频检索任务,我们最初的印象可能是它的计算量很大。阿里安全算法专家表示,在实际使用场景中,
检索问题是非常细粒度的任务
,例如我们不会说「找到一辆车」,反而会精确到「找到一辆宝马」。这种细粒度问题对于特征提取的计算要求非常高,与此同时,分辨率、码率等因素都影响着计算量。
尽管视频检索这个问题很难、算力要求很大,但阿里安全部门一直在积累经验,并尝试挖掘一种强有力的算法。
对于视频检索领域的未来发展,算法专家说:「不论是特征提取架构上的创新,还是视频与语言预训练模型的提升,它们肯定会共同发展。首先在架构方面,我们要解决的是跨模态的语义鸿沟,它的本质在于视觉特征空间与自然语言特征空间的联合建模问题,我认为当前架构会逐渐到达瓶颈,亟待出现一些新的架构创新。其次对于预训练,其目的在于提高下游任务的性能,这是非常重要的一个方向。」
不论是这两年新提出来的 Transformer 序列建模架构,还是 BERT 这种自监督预训练机制,视频检索需要沉淀更多的技术与思想,这样才能让大规模检索变得既经济又准确。
这样的挑战赛对阿里视频理解团队是非常有意义的,整个团队都可以通过挑战赛得到锻炼。阿里安全算法专家说:「整个团队首先会接触一些更前沿的技术,比如图卷积或自监督等技术,这些都会提升团队的技术前沿性。毕竟业务比较偏向成熟的方法,而比赛可以探索更新的技术。」
相信很多读者都参加过一些挑战赛,我们查阅基线模型代码、阅读更多前沿论文、尝试更多可能的思路,如果一个团队共同完成这些工作,那么提升还会大一些。「我们估计花了两个月的时间来完成这个挑战赛,几乎一周到两周一次研讨会。因为每个人都会负责不同的模块,因此也会有不懂的论文,这些都会在研讨会上讨论。」算法专家说。
除了这些常规操作,阿里安全图灵实验室视频理解团队还会邀请相关领域的研究者,特别是高校老师来做一些分享。这样不仅能了解最前沿的一些研究成果,本身也能学到非常多的视频领域知识。
![]()
通过比赛与业务,整个实验室在过去的四五年中已经累积了很多成果。这些技术很多都应用在内容安全方面,例如视频不良场景识别、视频违禁品识别、视频公众人物识别等等。除此之外,在视频特征方面,相似度匹配、场景理解、目标检测等技术都有实际落地场景。因为整个团队以安全业务为主,因此也就有视频审核、视频版权保护等具体业务。
整个挑战赛能带来很多沉淀,「我们不只是刷新一个成绩,我们更想做一些创新,摸索出一套实用的新方法」,阿里安全算法专家最后总结道。虽然挑战赛已经落幕,但对于跨模态视频检索这种复杂任务,新框架与新思路的创新也许就诞生于下一次累积。
视频理解的应用越来越广泛,阿里安全图灵实验室也希望更多能有视频理解领域人才的加入,发挥前沿技术力量产生更大的价值。如果您有 2 年以上相关的研究经历,有该领域的顶会文章或 top 竞赛成绩,阿里安全也招聘研究型实习生和正式研究者,有兴趣的读者可以联系 maofeng.mf@alibaba-inc.com,或加微信 rickymf4。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com