State Representation Learning for Control: An Overview
论文缺少的是最新的actionable 3d conv:但内容很多
TCN v2 + 3Dconv 运动信息

As an example, infants expect inertial objects to follow principles of persistence, continuity, cohesion and solidity before appearance-based elements such as color, texture and perceptual goodness. At the same time, these principles help guide later learnings such as object’ rigidity, softness and liquids properties.
Later, adults will reconstruct perceptual scenes using internal representations of the objects and their physically relevant properties (mass, elas- ticity, friction, gravity, collision, etc.) [Lake et al., 2016].
2.2
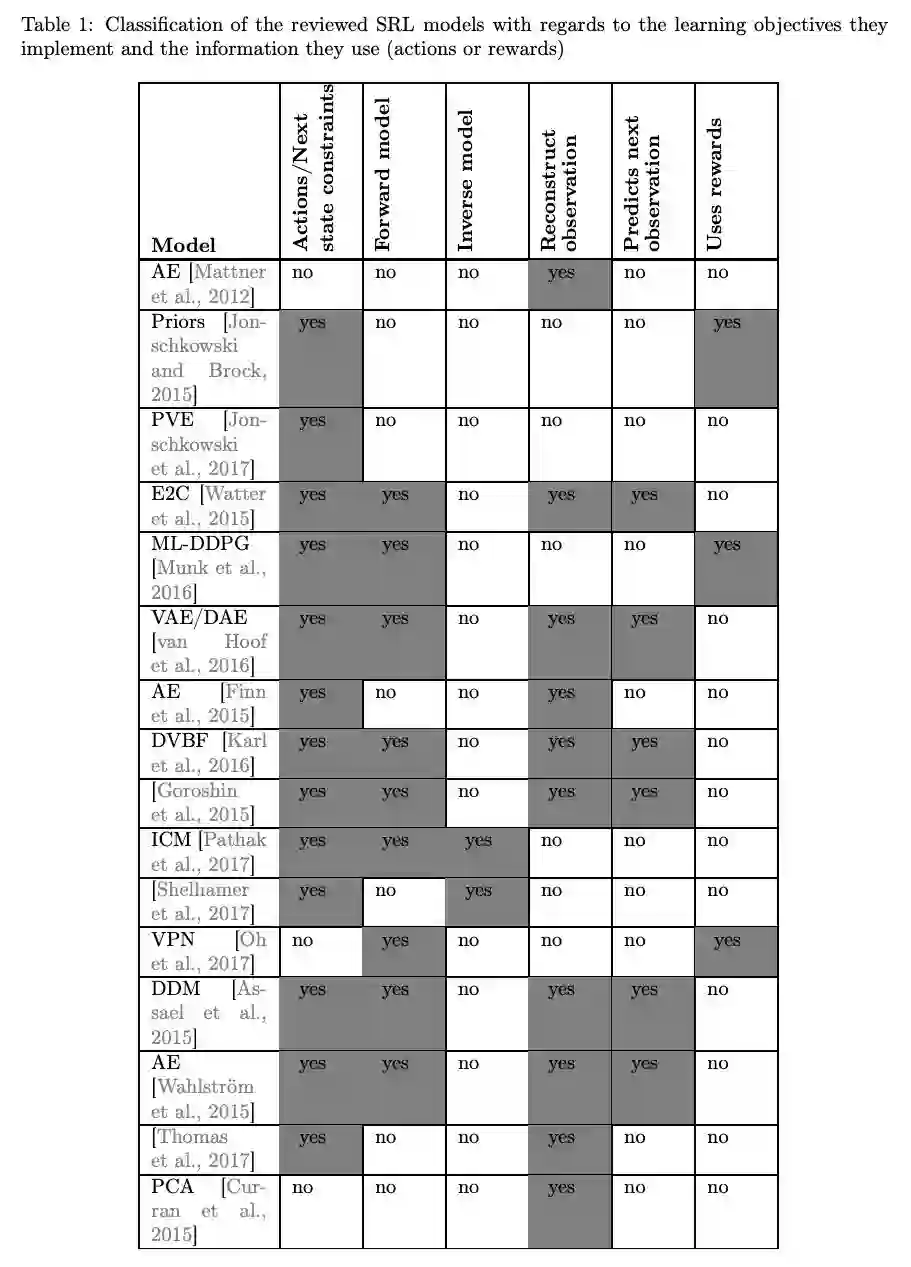
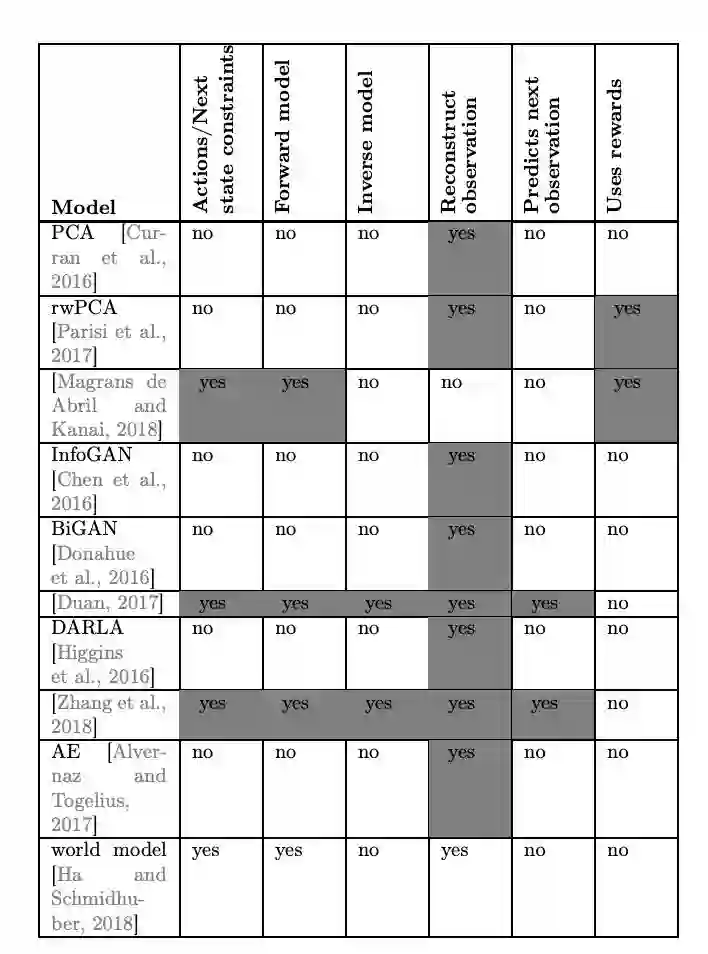
Using prior knowledge to constrain the state space: A last approach is to handle SRL by using specific constraints or prior knowledge about the functioning, dynamics or physics of the world (besides the constraints of forward and inverse models) such as the temporal continuity or the causality principles that generally reflect the interaction of the agent with objects or in the environment [Jonschkowski and Brock, 2015]. Priors are defined as objective or loss functions L, applied on a set of states s1:n (Fig. 5), to be minimized (or maximized) under specific condition c. An example of condition can be enforcing locality or time proximity within the set of states.
Loss = Lprior(s1:n;θφ|c) (5) All these approaches are detailed in Section 3.
2.3 State representation characteristics
Besides the general idea that the state representation has the role of encoding essential information (for a given task) while discarding irrelevant aspects of the original data, let us detail what the characteristics of a good state representation are.
In a reinforcement learning framework, the authors of [Böhmer et al., 2015] defines a good state representation as a representation that is:
• Markovian, i.e. it summarizes all the necessary information to be able to choose an action within the policy, by looking only at the current state.
• Able to represent the true value of the current state well enough for policy improvement.
• Able to generalize the learned value-function to unseen states with similar futures.
• Low dimensional for efficient estimation.
3 Learning objectives
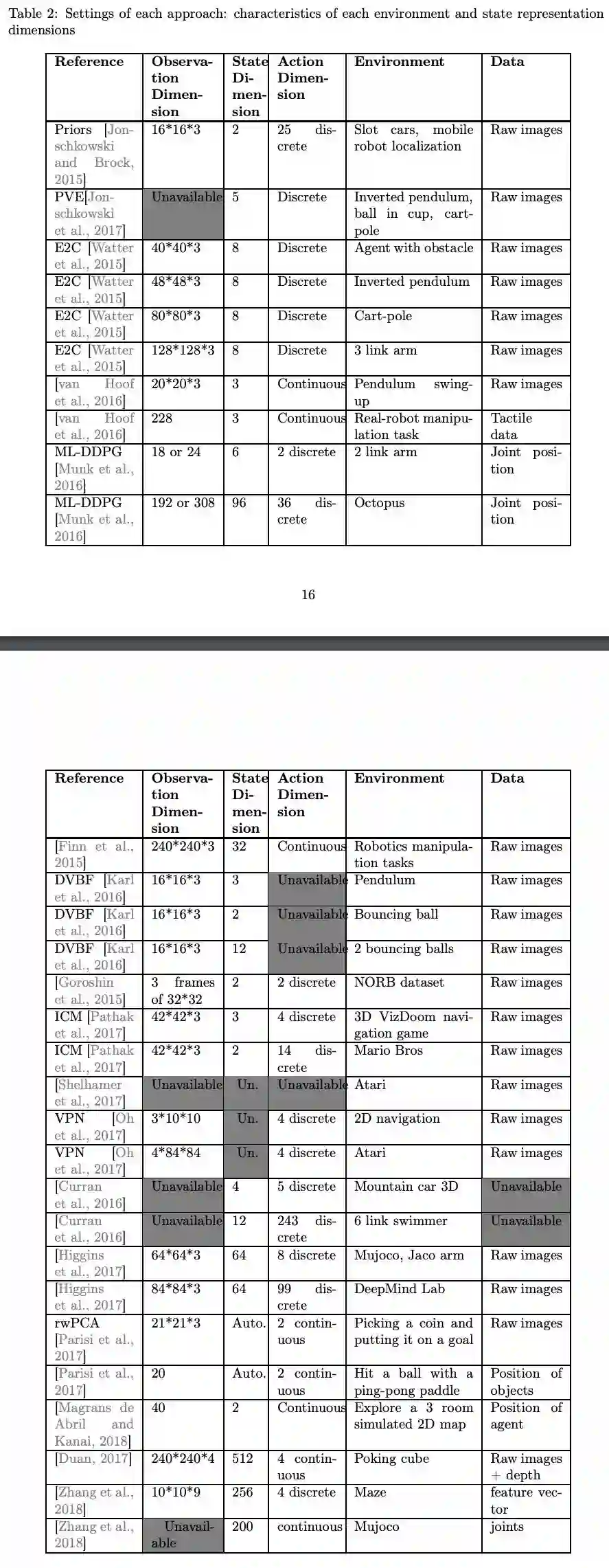
In this section, we review what objectives can be used to learn a relevant state representation. A schema detailing the core elements involved in each model’s loss function was introduced in Fig. 2 – 5, which highlights the main approaches to be described here. This section touches upon machine learning tools used in SRL such as auto-encoders or siamese networks. A more detailed description of these is later addressed in Section 4.
3.1 Reconstructing the observation
3.2 Learning a forward model
3.3 Learning an inverse model
3.4 Using feature adversarial learning
3.5 Exploiting rewards
3.5 Exploiting rewards
3.6 Other objective functions
Slowness Principle
Variability
Proportionality
Repeatability
Dynamic verification
Selectivity
3.7 Using hybrid objectives
4 Building blocks of State Representation Learning
In this section, we cover various implementation aspects relevant to state representation learning and its evaluation. We refer to specific surrogate models, loss function specification tools or strategies that help constraining the information bottleneck and generalizing when learning low- dimensional state representations,
4.1 Learning tools
We first detail a set of models that through an auxiliary objective function, help learning a state representation. One or several of these learning tools can be integrated in broader SRL approaches as was previously described.
4.1.1 Auto-encoders (AE)4.1.2 Denoising auto-encoders (DAE)
4.1.3 Variational auto-encoders (VAE)
4.1.4 Siamese networks
相关内容

Source: Apple - iOS 8


