学界 | Wasserstein is all you need:构建无监督表示的统一框架
选自arXiv
作者:Sidak Pal Singh等
机器之心编译
参与:白悦、路
瑞士洛桑联邦理工学院的研究者提出,通过将每个对象与分布估计和点估计(向量嵌入)相关联来构建单个对象或实体(及其组合)的无监督表示的统一框架。该方法可用于具有共现结构的任何无监督或监督问题(文本或其他模态)。该框架的关键工具是 Wasserstein 距离和 Wasserstein 重心。
近期自然语言处理和机器学习突然备受关注和成功的主要驱动因素之一是开发了更好的数据模态表示方法,比如,语言的连续向量表示 (Mikolov et al., 2013; Pennington et al., 2014)、基于卷积神经网络(CNN)的文本表示 (Kim, 2014; Kalchbrenner et al., 2014; Severyn and Moschitti, 2015; Deriu et al., 2017),或通过其它神经架构(如 RNN、LSTM)的文本表示,它们都共享一个核心思路——在保留输入语义的同时,将输入实体映射到位于低维潜在空间的密集向量嵌入。
现有方法是将每个感兴趣的实体(如一个单词)表示为空间中的单个点(如其嵌入向量),而该论文提出了一种完全不同的方法。研究者基于上下文的直方图来表示每个实体(与之共现),其中上下文是合适度量空间中的点。这允许研究者将与实体相关的直方图之间的距离转换为最佳传输问题的实例 (Monge, 1781; Kantorovich, 1942; Villani, 2008)。例如,在单词作为实体的情况下,得到的框架可以直观地寻求从给定单词的上下文移动到另一个单词的上下文的成本最小化。这里的上下文可以是与我们要表示的对象共现的单词、短语、句子或一般实体,这些对象还可以是从序列数据中提取的任何类型的事件,包括电影或网络广告之类的产品 (Grbovic et al., 2015)、图中的节点 (Grover and Leskovec, 2016),或其他实体 (Wu et al., 2017)。任何共现结构都允许构建直方图信息,这是本研究提出方法的关键构建块。
本研究提出方法的强烈动机来自于自然语言领域,其中实体(单词、短语或句子)通常具有多种语义,实体被呈现为语义。因此,考虑能够有效捕获这种固有的不确定性和多义性的表示是很重要的,研究者将论证嵌入的直方图(或概率分布)能够比单独的逐点嵌入捕获更多的信息。研究者将直方图称为感兴趣对象的分布估计,将单个上下文的各个嵌入称为点估计。
接下来,为了清晰起见,研究者将通过文本表示的具体用例讨论该框架,当上下文只是单词时,通过使用常见的正点互信息(PPMI)矩阵来计算每个单词的直方图信息。
借助最佳传输的强大力量,本研究展示了该框架如何有效用于 NLP 中的各种重要任务,包括单词和句子表示以及上下位关系(蕴涵)检测,该框架还可以在上下文的现有预训练嵌入的基础上轻松使用。
该框架与单词和上下文层次的最佳传输之间的联系为 NLP 应用中更好地利用其庞大的工具包(如 Wasserstein 距离、重心等)打下了基础,这在过去主要限于文档距离 (Kusner et al., 2015; Huang et al., 2016)。
本研究证明了构建所需的直方图几乎不需要额外的成本,因为共现计数是通过语料库的单次传输获得的。由于 Cuturi(2013)引入的熵正则化,我们可以在 GPU 上并行化、批量化地高效计算最佳传输距离。最后,获得的传输图(图 1)也提供了该框架的可解释性。
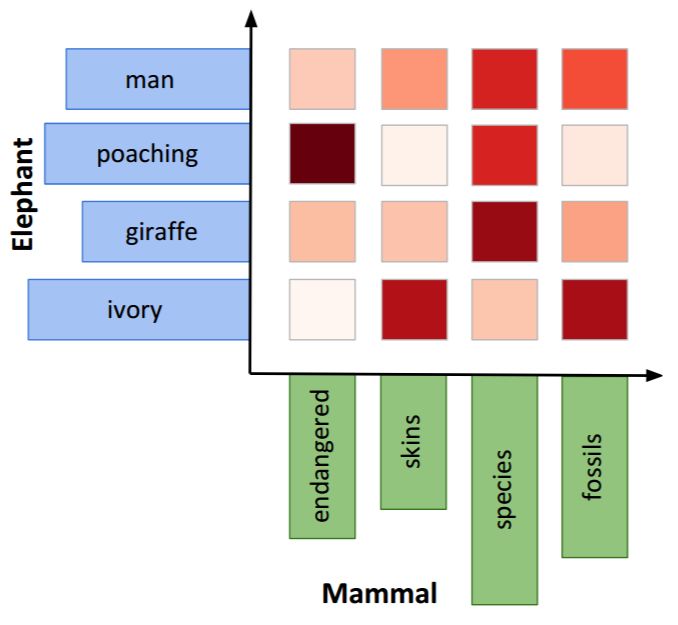
图 1:大象和哺乳动物直方图之间最佳传输的图示。这里,研究者从两个直方图的前 20 个上下文的列表(就 PPMI 而言)中随机选择四个上下文。然后使用正则化的 Wasserstein 距离(如公式(4)所示),绘制所获得的传输矩阵(或通常称为传输图)T,如上所述。
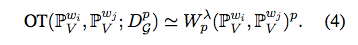
论文:Wasserstein is all you need

论文链接:https://arxiv.org/pdf/1808.09663v1.pdf
摘要:我们提出了通过将每个对象与分布估计和点估计(向量嵌入)相关联,来构建单个对象或实体(及其组合)的无监督表示的统一框架。这可以通过使用最佳传输来实现,这使我们能够在利用背景空间(ground space)的基础几何结构的同时建立这些相关估计。我们的方法为构建丰富而强大的特征表示提供了新的视角,这些表示可以同时(通过分布估计)捕获不确定性和(使用最佳传输图)捕获可解释性。作为一个指导性的例子,我们为文本制定了无监督表示,特别是对于句子表示和蕴涵检测。实验结果显示我们提出的框架获得了很大的优势。该方法可用于具有共现结构的任何无监督或监督问题(文本或其他模态),例如任何序列数据。该框架的关键工具是 Wasserstein 距离和 Wasserstein 重心(因此才有了现在的论文标题!)。
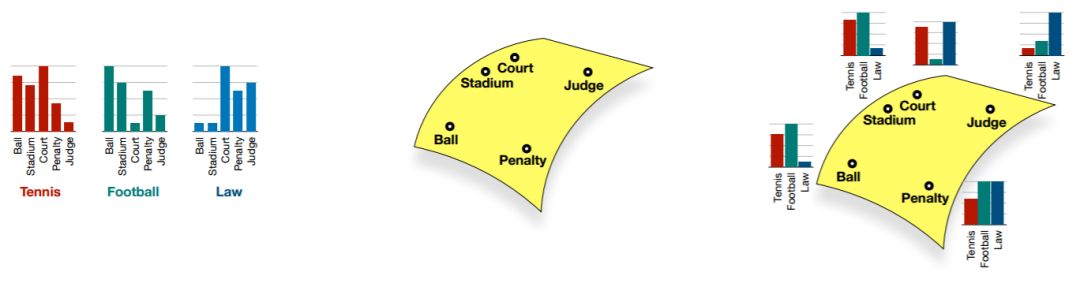
图 2:三个单词的图示,每个单词都有其分布估计(左)、相关上下文的点估计(中),以及联合表示(右)。
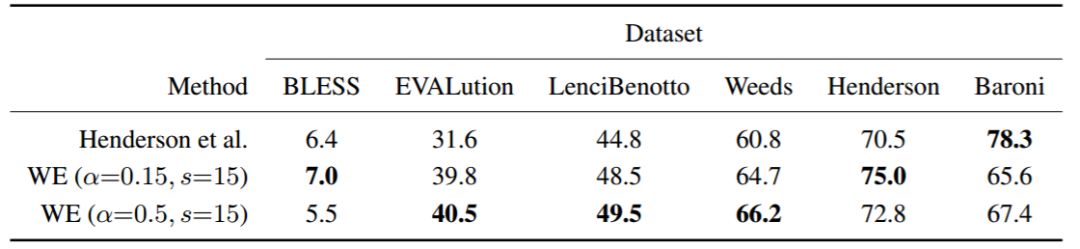
表 2:蕴涵向量(entailment vector)和最佳运输/基于 Wasserstein 的蕴涵测量(WE)之间的比较。得分为 AP @ all(%)。超参数 α 指的是平滑指数,s 指 PPMI 计算中的位移。附录 A 中的表 4 列出了更多数据集。
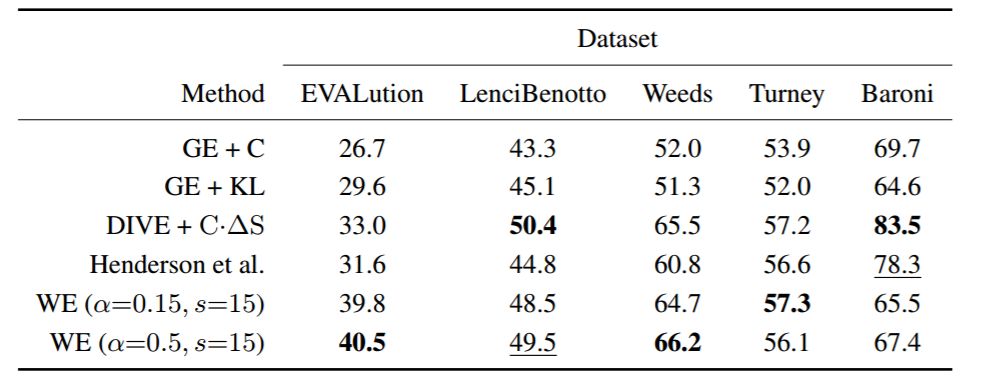
表 3:蕴涵向量,最佳运输/基于 Wasserstein 的蕴涵测量(WE)和其他当前最优方法之间的比较。GE + C 和 GE + KL 分别是具有余弦相似度和负 KL 散度的高斯嵌入。当我们使用相同的评估设置时,GE + C、GE + KL 和 DIVE + C·ΔS 的得分取自 (Chang et al., 2017),分数是 AP @ all(%)。
结论
总而言之,我们得出将分布估计和点估计相关联作为每个实体的表示。我们展示了该方法允许在共现结构问题中使用与这些实体相关联的上下文集合的最优传输。此外,该框架能够与现有的指针估计和嵌入有效地结合,并且在多个 NLP 任务上展示了它的性能。最后,我们的方法为构建丰富的特征表示提供了独特的视角,这些表示能够同时捕获不确定性和可解释性。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


