【综述】介绍这些常用机器学习算法的优缺点
Datawhale干货
来源:数据派THU、七月在线
-
正则化算法(Regularization Algorithms) -
集成算法(Ensemble Algorithms) -
决策树算法(Decision Tree Algorithm) -
回归(Regression) -
人工神经网络(Artificial Neural Network) -
深度学习(Deep Learning) -
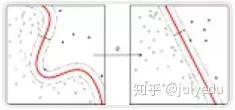
支持向量机(Support Vector Machine) -
降维算法(Dimensionality Reduction Algorithms) -
聚类算法(Clustering Algorithms) -
基于实例的算法(Instance-based Algorithms) -
贝叶斯算法(Bayesian Algorithms) -
关联规则学习算法(Association Rule Learning Algorithms) -
图模型(Graphical Models)
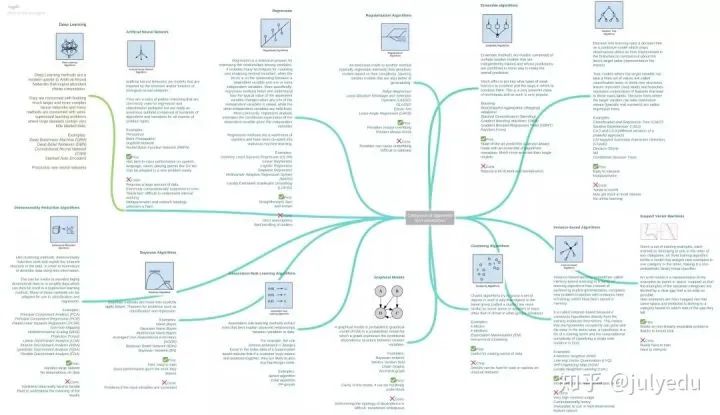
正则化算法(Regularization Algorithms)
-
岭回归(Ridge Regression) -
最小绝对收缩与选择算子(LASSO) -
GLASSO -
弹性网络(Elastic Net) -
最小角回归(Least-Angle Regression)
-
其惩罚会减少过拟合 -
总会有解决方法
-
惩罚会造成欠拟合 -
很难校准
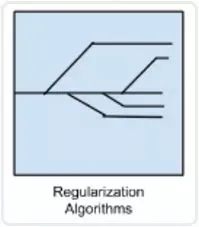
Boosting
Bootstrapped Aggregation(Bagging)
AdaBoost
层叠泛化(Stacked Generalization)(blending)
梯度推进机(Gradient Boosting Machines,GBM)
梯度提升回归树(Gradient Boosted Regression Trees,GBRT)
随机森林(Random Forest)
-
当先最先进的预测几乎都使用了算法集成。它比使用单个模型预测出来的结果要精确的多
-
需要大量的维护工作
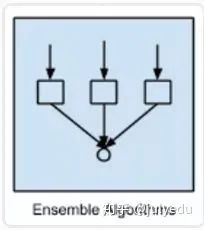
树模型中的目标是可变的,可以采一组有限值,被称为分类树;在这些树结构中,叶子表示类标签,分支表示表征这些类标签的连接的特征。
-
分类和回归树(Classification and Regression Tree,CART) -
Iterative Dichotomiser 3(ID3) -
C4.5 和 C5.0(一种强大方法的两个不同版本)
-
容易解释 -
非参数型
-
趋向过拟合 -
可能或陷于局部最小值中 -
没有在线学习
-
普通最小二乘回归(Ordinary Least Squares Regression,OLSR) -
线性回归(Linear Regression) -
逻辑回归(Logistic Regression) -
逐步回归(Stepwise Regression) -
多元自适应回归样条(Multivariate Adaptive Regression Splines,MARS) -
本地散点平滑估计(Locally Estimated Scatterplot Smoothing,LOESS)
-
直接、快速 -
知名度高
-
要求严格的假设 -
需要处理异常值
-
感知器 -
反向传播 -
Hopfield 网络 -
径向基函数网络(Radial Basis Function Network,RBFN)
-
在语音、语义、视觉、各类游戏(如围棋)的任务中表现极好。 -
算法可以快速调整,适应新的问题。
-
需要大量数据进行训练 -
训练要求很高的硬件配置 -
模型处于黑箱状态,难以理解内部机制 -
元参数(Metaparameter)与网络拓扑选择困难。
-
深玻耳兹曼机(Deep Boltzmann Machine,DBM) -
Deep Belief Networks(DBN) -
卷积神经网络(CNN) -
Stacked Auto-Encoders
-
在非线性可分问题上表现优秀
-
非常难以训练 -
很难解释
-
主成分分析(Principal Component Analysis (PCA)) -
主成分回归(Principal Component Regression (PCR)) -
偏最小二乘回归(Partial Least Squares Regression (PLSR)) -
Sammon 映射(Sammon Mapping) -
多维尺度变换(Multidimensional Scaling (MDS)) -
投影寻踪(Projection Pursuit) -
线性判别分析(Linear Discriminant Analysis (LDA)) -
混合判别分析(Mixture Discriminant Analysis (MDA)) -
二次判别分析(Quadratic Discriminant Analysis (QDA)) -
灵活判别分析(Flexible Discriminant Analysis (FDA))
-
可处理大规模数据集 -
无需在数据上进行假设
-
难以搞定非线性数据 -
难以理解结果的意义
聚类算法是指对一组目标进行分类,属于同一组(亦即一个类,cluster)的目标被划分在一组中,与其他组目标相比,同一组目标更加彼此相似(在某种意义上)。
-
K-均值(k-Means) -
k-Medians 算法 -
Expectation Maximi 封层 ation (EM) -
最大期望算法(EM) -
分层集群(Hierarchical Clstering)
-
让数据变得有意义
-
结果难以解读,针对不寻常的数据组,结果可能无用。
-
K 最近邻(k-Nearest Neighbor (kNN)) -
学习向量量化(Learning Vector Quantization (LVQ)) -
自组织映射(Self-Organizing Map (SOM)) -
局部加权学习(Locally Weighted Learning (LWL))
-
算法简单、结果易于解读
-
内存使用非常高 -
计算成本高 -
不可能用于高维特征空间
-
朴素贝叶斯(Naive Bayes) -
高斯朴素贝叶斯(Gaussian Naive Bayes) -
多项式朴素贝叶斯(Multinomial Naive Bayes) -
平均一致依赖估计器(Averaged One-Dependence Estimators (AODE)) -
贝叶斯信念网络(Bayesian Belief Network (BBN)) -
贝叶斯网络(Bayesian Network (BN))
-
快速、易于训练、给出了它们所需的资源能带来良好的表现
-
如果输入变量是相关的,则会出现问题
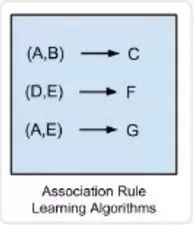
-
Apriori 算法(Apriori algorithm) -
Eclat 算法(Eclat algorithm) -
FP-growth
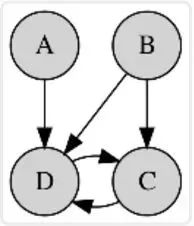
-
贝叶斯网络(Bayesian network) -
马尔可夫随机域(Markov random field) -
链图(Chain Graphs) -
祖先图(Ancestral graph)
-
模型清晰,能被直观地理解
确定其依赖的拓扑很困难,有时候也很模糊


登录查看更多
相关内容

决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
Arxiv
44+阅读 · 2020年2月5日
Arxiv
4+阅读 · 2018年9月17日




相关VIP内容
相关资讯
相关论文
Arxiv
44+阅读 · 2020年2月5日
Arxiv
4+阅读 · 2018年9月17日