【干货】对于回归问题,我们该怎样选择合适的机器学习算法
【导读】机器学习算法往往各自具有优缺点,没有哪一种算法可以适合所有的问题。因此,理解常用机器学习算法的原理和优缺点能帮助我们针对不同的问题“对症下药”,找到特定问题的最好算法。本文分别介绍:线性回归和多项式回归、神经网络、决策树和决策森林,并分别列出了其各自优缺点,相信有助于指导我们在特定工作中选择合适的算法。

Selecting the best Machine Learning algorithm for your regression problem
为你的回归问题选择最佳的机器学习算法
当处理机器学习(ML)的问题时,可以选择许多不同的算法。在机器学习中,有一种叫做“没有免费的午餐”的定理,即没有任何一种ML算法在处理所有问题的时候都适合。不同ML算法的性能很大程度上取决于数据的大小和结构。因此,除非我们就事论事地评估算法的错误率,否则很难找到最好的算法。
每种ML算法都有优点和缺点, 了解它们 可以指导我们去选择最合适我们问题的算法。下面我们将看看几个典型的解决回归问题的ML算法,并根据它们的优缺点为它们设置一些使用准则。
线性和多项式回归
从简单情况开始,单变量线性回归是一种使用线性模型来模拟单个输入自变量(特征变量)和输出因变量之间的关系的技术。更一般的情况是多变量线性回归,它刻画多个独立输入变量(特征变量)与输出因变量之间的关系。该模型保持线性,因此输出是输入变量的线性组合。
第三种最常见的模型是多项式回归,它 为特征变量的非线性组合构建模型,即可以存在指数变量,正弦和余弦等。然而,这需要知道输入与输出是什么关系。回归模型可以使用随机梯度下降(SGD)进行训练。
优点:
• 建模快速且特别有用,尤其是当建模关系不是非常复杂并且数据量小时。
• 线性回归很容易理解,这对商业决策可能非常有价值。
缺点:
• 对于非线性数据,多项式回归很难设计,因为必须具有关于数据结构和特征变量之间关系的一些信息。
• 由于上述原因,当涉及到高度复杂的数据时,这些模型不如其他模型。
神经网络
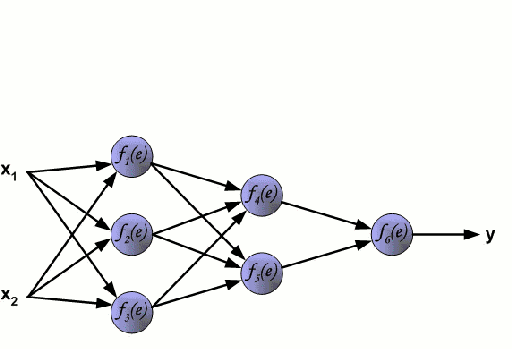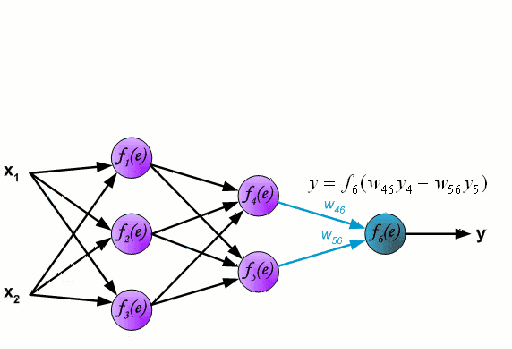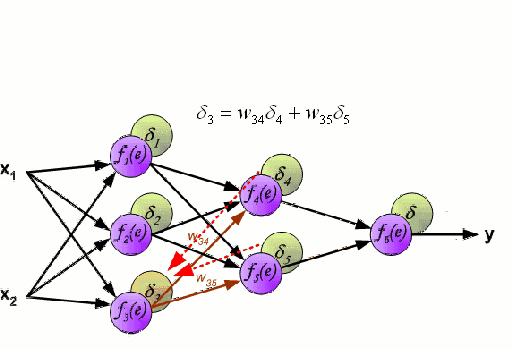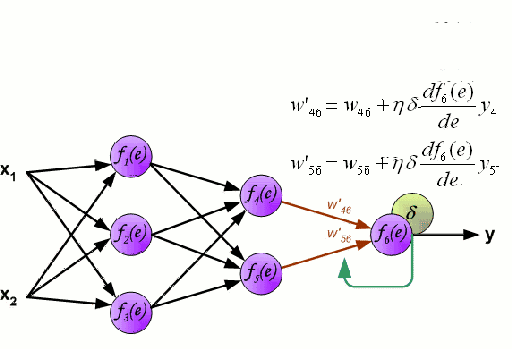
神经网络由一组相互连接的节点组成,这些节点称为神经元。来自数据的输入特征变量作为多变量线性组合被传递给这些神经元,其中乘以每个特征变量的值被称为权重。然后将非线性函数将会作用于这些线性组合,从而为神经网络提供建模复杂非线性关系的能力。神经网络可以有多层,其中一层的输出以相同的方式传递给下一层。在输出端,通常不会施加非线性变换。神经网络使用随机梯度下降(SGD)和反向传播算法进行训练。
优点:
• 由于神经网络可以具有很多非线性关系的层,所以它们在建模非常复杂的非线性关系时非常有效。
• 我们通常不必担心神经网络中的数据结构,它们在学习几乎任何类型的特征变量关系时都非常灵活。
• 研究表明,只要为网络提供大量的训练数据,无论是全新的还是简单增加原始数据集,都会提高网络性能。
缺点:
• 模型的复杂性导致它们不容易解释和理解。
• 训练起来非常具有挑战性, 计算强度大,需要仔细调整超参数并设置学习速率时间表。
• 他们需要大量数据才能实现高性能,并且在“小数据”情况下通常不如其他的ML算法。
回归树和随机森林
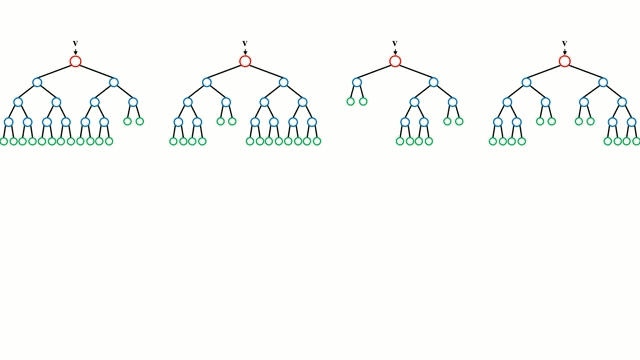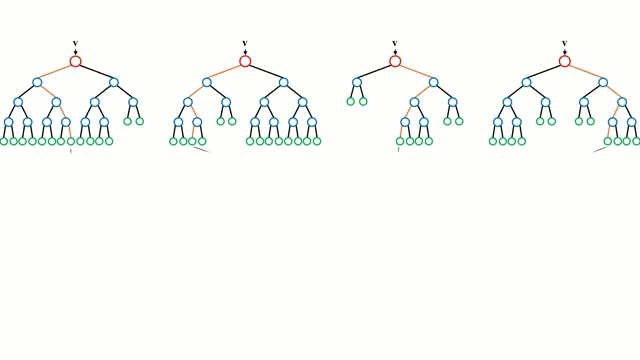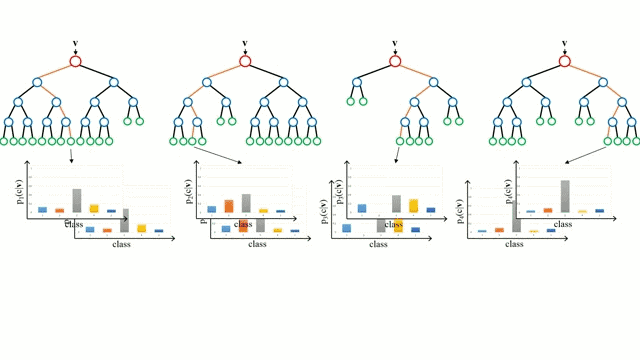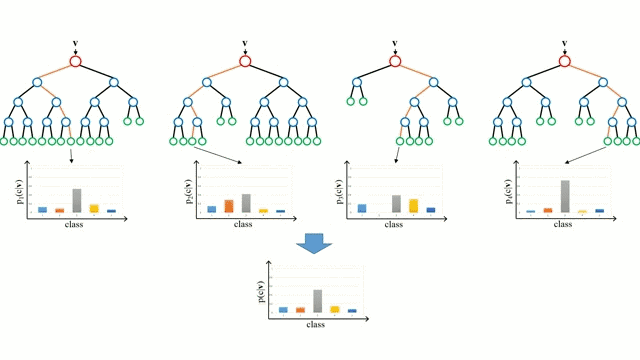
决策树是一种直观的模型,你可以遍历树的节点, 从上往下走, 当遇到分叉的时候,决策选择去哪个分支。测试时决策树, 你可以将一组训练实例作为输入,确定哪些属性最适合分割,然后按照这些属性去分割数据集,并在分割数据集上循环上述操作,直到对所有训练实例进行分类为止。在训练决策树时,我们的目标是分割那些能够使数据的两个分支都高度纯净度的属性,并尽量减少为了对数据集中的所有实例进行分类而需要进行的分割次数。纯净度是通过信息增益来衡量的。在实践中,一般是通过计算熵, 或者基尼系数。
随机森林只是决策树的集合。输入向量通过多个决策树运行。对于回归,需要求所有树的输出平均值;对于分类,直接使用投票来确定最终的类别。
优点:
• 擅长学习复杂的高度非线性关系。它们通常可以实现相当高的性能,性能优于多项式回归,通常与神经网络相当。
• 非常容易解释和理解。虽然最终的训练模型可以学习复杂的关系,但是在训练过程中建立的决策边界很容易理解。
缺点:
• 由于决策树的性质,它很容易出现过拟合。完整的决策树模型太过复杂甚至包含不必要的结构。即使通过剪枝和使用随机森林。
• 使用较大的随机森林来在获得更高性能的同时, 需要占用更多内存, 而且更加耗时
参考文献
https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知


