本文首发极市平台公众号,转载请获得授权并标明出处。
极市平台一直在对CVPR 2022的论文进行分方向的整理,目前已累计更新了386篇,本文为本周更新的CVPR 2022 论文,包含目标检测、图像处理、三维视觉、医学影像、视频检索等方向,附打包下载链接。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
CVPR 2022 已经放榜,本次一共有2067篇论文被接收,接收论文数量相比去年增长了24%。在CVPR2022正式会议召开前,为了让大家更快地获取和学习到计算机视觉前沿技术,极市对CVPR022 最新论文进行追踪,包括分研究方向的论文、代码汇总以及论文技术直播分享。
CVPR 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了
386篇,项目地址:
https://bbs.cvmart.net/articles/6124
以下是本周更新的 CVPR 2022 论文,包含包含目标检测、图像处理、三维视觉、医学影像、动作识别、
人脸、文本检测、目标跟踪、神经网络架构设计等方向。
- 检测
- 2D目标检测
- 3D目标检测
- 车道线检测
- 异常检测
- 分割
- 语义分割
- 实例分割
- 全景分割
- 密集预测
- 估计
- 位姿估计
- 光流估计
- 深度估计
- 人体姿态估计
- 图像、视频检索与理解
- 动作识别
- 行人重识别
- 图像字幕
- 医学影像
- 文本检测与识别
- 目标跟踪
- 人脸
- 人脸编辑
- 人脸伪造
- 表情识别
- 图像处理
- 图像复原/图像重建
- 超分辨率
- 图像去噪/去雨
- 风格迁移
- 图像翻译
- 三维视觉
- 点云
- 三维重建
- 场景重建/视图合成
- 视频处理
- 视频编辑
- 场景图生成
- 迁移学习/domain
- 对抗式
- 数据集
- 数据处理
- 图像压缩
- 归一化
- 视觉表征学习
- 神经网络结构设计
- CNN
- Transformer
- 神经网络架构搜索
- 模型训练/泛化
- 噪声标签
- 小样本学习
- 度量学习
- 持续学习
- 联邦学习
- 元学习
- 强化学习
检测
2D目标检测
[1] Semantic-aligned Fusion Transformer for One-shot Object Detection(用于一次性目标检测的语义对齐融合transformer)
paper:https://arxiv.org/abs/2203.09093
[2] A Dual Weighting Label Assignment Scheme for Object Detection(一种用于目标检测的双重加权标签分配方案)
paper:https://arxiv.org/abs/2203.09730
code:https://github.com/strongwolf/DW
[3] Confidence Propagation Cluster: Unleash Full Potential of Object Detectors(信心传播集群:释放目标检测器的全部潜力)
paper:https://arxiv.org/abs/2112.00342
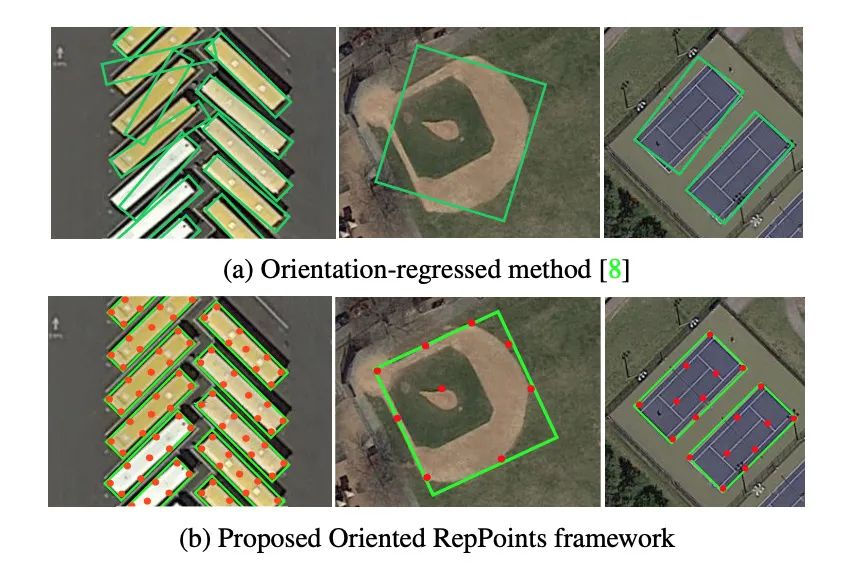
[4] Oriented RepPoints for Aerial Object Detection(面向空中目标检测的 RepPoints)(
小目标检测)
paper:https://arxiv.org/abs/2105.11111
code:https://github.com/LiWentomng/OrientedRepPoints
[5] Real-time Object Detection for Streaming Perception(用于流感知的实时对象检测)
paper:https://arxiv.org/abs/2203.12338
code:https://github.com/yancie-yjr/StreamYOLO
[6] Progressive End-to-End Object Detection in Crowded Scenes(拥挤场景中的渐进式端到端对象检测)
paper:https://arxiv.org/abs/2203.07669
code:https://github.com/megvii-model/Iter-E2EDET
[7] QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection(用于加速高分辨率小目标检测的级联稀疏查询)(
小目标检测)
paper:https://arxiv.org/abs/2103.09136
code:https://github.com/ChenhongyiYang/QueryDet-PyTorch
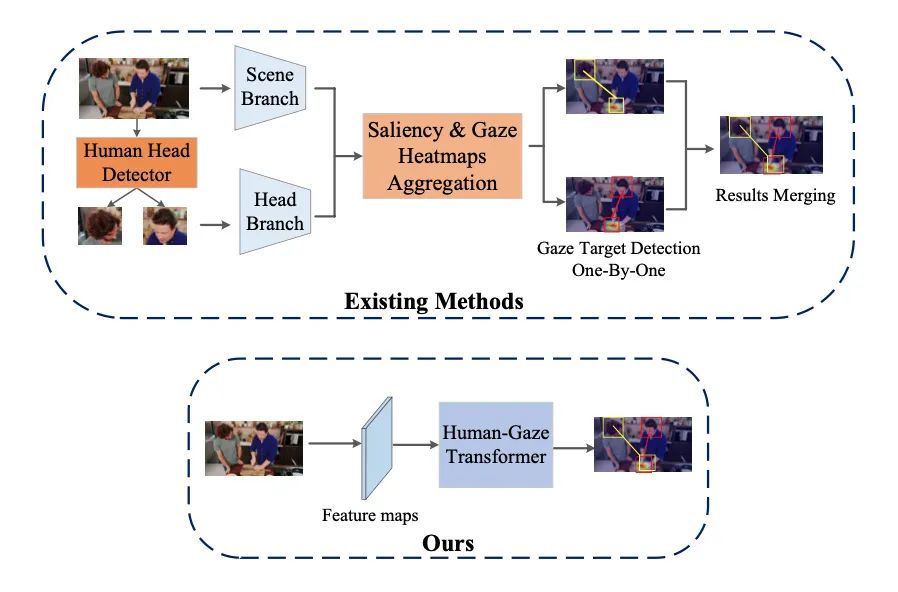
[8] End-to-End Human-Gaze-Target Detection with Transformers(使用 Transformer 进行端到端的人眼目标检测)
paper:https://arxiv.org/abs/2203.10433
3D目标检测
[1] Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds(从点云进行 3D 对象检测的 Set-to-Set 方法)
paper:https://arxiv.org/abs/2203.10314
code:https://github.com/skyhehe123/VoxSeT
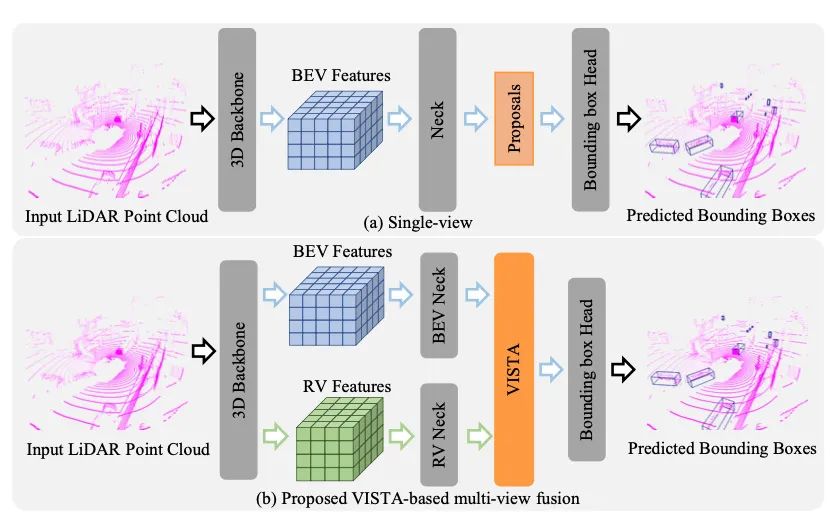
[2] VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention
paper:https://arxiv.org/abs/2203.09704
code:https://github.com/Gorilla-Lab-SCUT/VISTA
[3] MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer(使用深度感知 Transformer 的单目 3D 对象检测)
paper:https://arxiv.org/abs/2203.10981
code:https://github.com/kuanchihhuang/MonoDTR
[4] Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion(迈向具有深度完成的高质量 3D 检测)
paper:https://arxiv.org/abs/2203.09780
[5] Not All Points Are Equal: Learning Highly Efficient Point-based Detectors for 3D LiDAR Point Clouds(学习用于 3D LiDAR 点云的高效基于点的检测器)
paper:https://arxiv.org/abs/2203.11139
code:https://github.com/yifanzhang713/IA-SSD
[6] TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers(用于 3D 对象检测的稳健 LiDAR-Camera Fusion 与 Transformer)
paper:https://arxiv.org/abs/2203.11496
code:https://github.com/XuyangBai/TransFusion
车道线检测
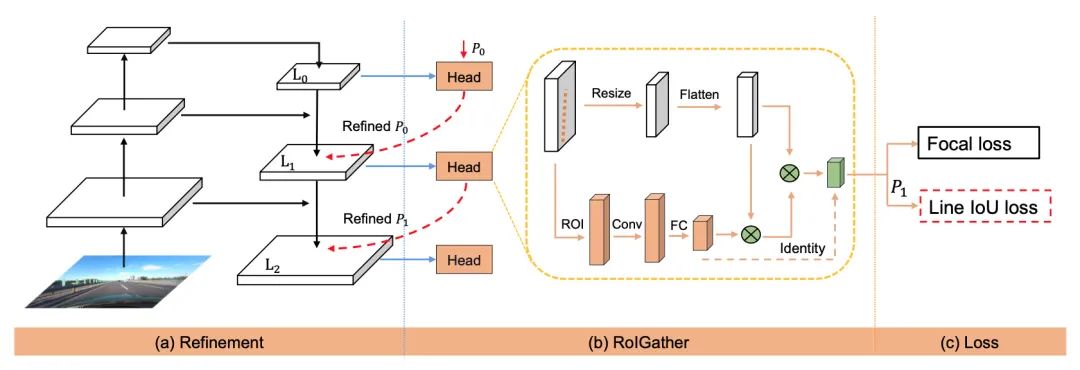
[1] CLRNet: Cross Layer Refinement Network for Lane Detection(用于车道检测的跨层细化网络)
paper:https://arxiv.org/abs/2203.10350
异常检测
[1] ViM: Out-Of-Distribution with Virtual-logit Matching(具有虚拟 logit 匹配的分布外)(
OOD检测)
paper:https://arxiv.org/abs/2203.10807
code:https://github.com/haoqiwang/vim
[2] UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection(监督开放集视频异常检测的新基准)
paper:https://arxiv.org/abs/2111.08644
code:https://github.com/lilygeorgescu/UBnormal
分割
语义分割
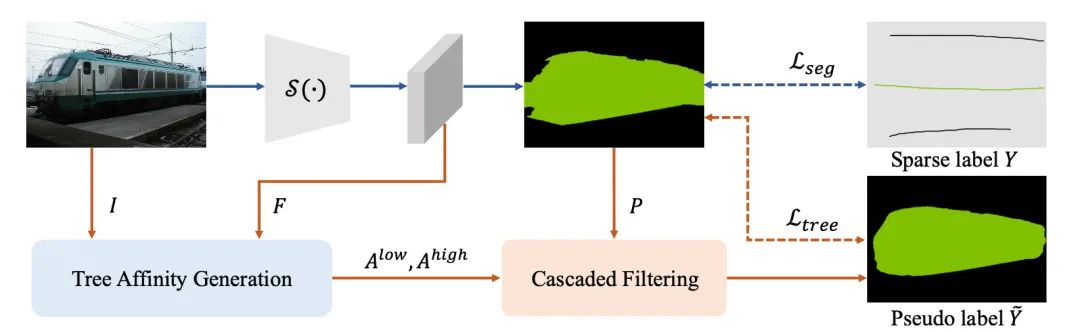
[1] Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation(走向稀疏注释的语义分割)
paper:https://arxiv.org/abs/2203.10739
code:https://github.com/megviiresearch/TEL
[2] Regional Semantic Contrast and Aggregation for Weakly Supervised Semantic Segmentation(弱监督语义分割的区域语义对比和聚合)
paper:https://arxiv.org/abs/2203.09653
code:https://github.com/maeve07/RCA.git
[3] Class-Balanced Pixel-Level Self-Labeling for Domain Adaptive Semantic Segmentation(用于域自适应语义分割的类平衡像素级自标记)
paper:https://arxiv.org/abs/2203.09744
code:https://github.com/lslrh/CPSL
[4] Perturbed and Strict Mean Teachers for Semi-supervised Semantic Segmentation(半监督语义分割的扰动和严格均值)
paper:https://arxiv.org/abs/2111.12903
实例分割
[1] Discovering Objects that Can Move(发现可以移动的物体)
paper:https://arxiv.org/abs/2203.10159
code:https://github.com/zpbao/Discovery_Obj_Move/
[2] ContrastMask: Contrastive Learning to Segment Every Thing(对比学习分割每件事)
paper:https://arxiv.org/abs/2203.09775
[3] Mask Transfiner for High-Quality Instance Segmentation(用于高质量实例分割的 Mask Transfiner)
paper:https://arxiv.org/abs/2111.13673
code:https://github.com/SysCV/transfiner
[4] Sparse Instance Activation for Real-Time Instance Segmentation(实时实例分割的稀疏实例激活)
paper:https://arxiv.org/abs/2203.12827
code:https://github.com/hustvl/SparseInst
全景分割
[1] Panoptic SegFormer: Delving Deeper into Panoptic Segmentation with Transformers(使用 Transformers 深入研究全景分割)
paper:https://arxiv.org/abs/2109.03814
code:https://github.com/zhiqi-li/Panoptic-SegFormer
密集预测
[1] DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting(具有上下文感知提示的语言引导密集预测)
paper:https://arxiv.org/abs/2112.01518
code:https://github.com/raoyongming/DenseCLIP
估计
位姿估计
[1] DiffPoseNet: Direct Differentiable Camera Pose Estimation(直接可微分相机位姿估计)
paper:https://arxiv.org/abs/2203.11174
[1] RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization(具有鲁棒对应场估计和位姿优化的递归 6-DoF 对象位姿细化)
paper:https://arxiv.org/abs/2203.12870
code:https://github.com/DecaYale/RNNPose
[2] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation(用于单目物体位姿估计的广义端到端概率透视-n-点)
paper:https://arxiv.org/abs/2203.13254
光流估计
[1] Global Matching with Overlapping Attention for Optical Flow Estimation(具有重叠注意力的全局匹配光流估计)
paper:https://arxiv.org/abs/2203.11335
code:https://github.com/xiaofeng94/GMFlowNet
深度估计
[1] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation(基于自适应相关的级联循环网络的实用立体匹配)
paper:https://arxiv.org/abs/2203.11483
project:https://github.com/megvii-research/CREStereo
[2] Revisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective(从特征一致性的角度重新审视域广义立体匹配网络)
paper:https://arxiv.org/abs/2203.10887
[3] Deep Depth from Focus with Differential Focus Volume(具有不同焦点体积的焦点深度)
paper:https://arxiv.org/abs/2112.01712
[4] RGB-Depth Fusion GAN for Indoor Depth Completion(用于室内深度完成的 RGB 深度融合 GAN)
paper:https://arxiv.org/abs/2203.10856
[5] Depth Estimation by Combining Binocular Stereo and Monocular Structured-Light(结合双目立体和单目结构光的深度估计)
paper:https://arxiv.org/abs/2203.10493
code:https://github.com/YuhuaXu/MonoStereoFusion
人体姿态估计
[1] Ray3D: ray-based 3D human pose estimation for monocular absolute 3D localization(用于单目绝对 3D 定位的基于射线的 3D 人体姿态估计)
paper:https://arxiv.org/abs/2203.11471
code:https://github.com/YxZhxn/Ray3D
图像、视频检索与理解
动作识别
[1] Self-supervised Video Transformer(自监督视频transformer)
paper:https://arxiv.org/abs/2112.01514
code:https://git.io/J1juJ
[2] DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition(鲁棒动作识别的 Transformer 方法中的定向注意)
paper:https://arxiv.org/abs/2203.10233
[3] Look for the Change: Learning Object States and State-Modifying Actions from Untrimmed Web Videos(寻找变化:从未修剪的网络视频中学习对象状态和状态修改操作)
paper:https://arxiv.org/abs/2203.11637
code:https://github.com/zju-vipa/MEAT-TIL
[4] E2(GO)MOTION: Motion Augmented Event Stream for Egocentric Action Recognition(用于以自我为中心的动作识别的运动增强事件流)
paper:https://arxiv.org/abs/2112.03596
[5] How Do You Do It? Fine-Grained Action Understanding with Pseudo-Adverbs(你怎么做呢?使用伪副词进行细粒度的动作理解)
paper:https://arxiv.org/abs/2203.12344
行人重识别
[1] Cascade Transformers for End-to-End Person Search(用于端到端人员搜索的级联transformer)
paper:https://arxiv.org/abs/2203.09642
code:https://github.com/Kitware/COAT
图像字幕
[1] Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources(通过在线资源对上下文外图像进行开放域、基于内容、多模式的事实检查)
paper:https://arxiv.org/abs/2112.00061
code:https://s-abdelnabi.github.io/OoC-multi-modal-fc/
医学影像
[1] ACPL: Anti-curriculum Pseudo-labelling for Semi-supervised Medical Image Classification(半监督医学图像分类的反课程伪标签)
paper:https://arxiv.org/abs/2111.12918
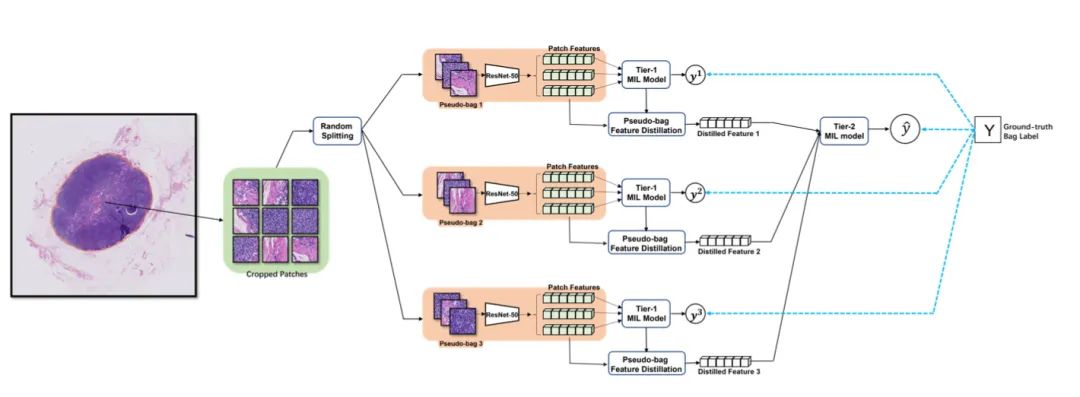
[2] DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification(用于组织病理学全幻灯片图像分类的双层特征蒸馏多实例学习)
paper:https://arxiv.org/abs/2203.12081
code:https://github.com/hrzhang1123/DTFD-MIL
文本检测与识别
[1] Fourier Document Restoration for Robust Document Dewarping and Recognition(用于鲁棒文档去扭曲和识别的傅里叶文档恢复)
paper:https://arxiv.org/abs/2203.09910
code:https://sg-vilab.github.io/event/warpdoc/
[2] SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition(通过文本检测和文本识别之间更好的协同作用进行场景文本定位)
paper:https://arxiv.org/abs/2203.10209
code:https://github.com/mxin262/SwinTextSpotter
目标跟踪
[1] MixFormer: End-to-End Tracking with Iterative Mixed Attention(具有迭代混合注意力的端到端跟踪)
paper:https://arxiv.org/abs/2203.11082
code:https://github.com/MCG-NJU/MixFormer
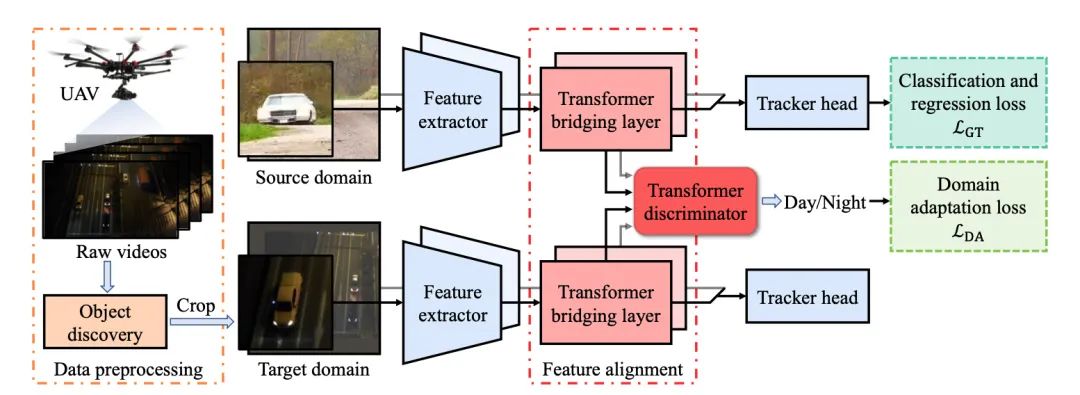
[2] Unsupervised Domain Adaptation for Nighttime Aerial Tracking(夜间空中跟踪的无监督域自适应)
paper:https://arxiv.org/abs/2203.10541
code:https://github.com/vision4robotics/UDAT
[3] Global Tracking Transformers
paper:https://arxiv.org/abs/2203.13250
code:https://github.com/xingyizhou/GTR
[4] Transforming Model Prediction for Tracking(转换模型预测以进行跟踪)
paper:https://arxiv.org/abs/2203.11192
code:https://github.com/visionml/pytracking
人脸
[1] HP-Capsule: Unsupervised Face Part Discovery by Hierarchical Parsing Capsule Network(分层解析胶囊网络的无监督人脸部分发现)
paper:https://arxiv.org/abs/2203.10699
[2] Portrait Eyeglasses and Shadow Removal by Leveraging 3D Synthetic Data(利用 3D 合成数据去除人像眼镜和阴影)
paper:https://arxiv.org/abs/2203.10474
code:https://github.com/StoryMY/take-off-eyeglasses
[3] Cross-Modal Perceptionist: Can Face Geometry be Gleaned from Voices?(跨模态感知者:可以从声音中收集面部几何形状吗?)
paper:https://arxiv.org/abs/2203.09824
project:https://choyingw.github.io/works/Voice2Mesh/index.html
人脸编辑
[1] FENeRF: Face Editing in Neural Radiance Fields(神经辐射场中的人脸编辑)
paper:https://arxiv.org/abs/2111.15490
project:https://mrtornado24.github.io/FENeRF/
人脸伪造
[1] Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection(对抗样本的自监督学习:迈向 Deepfake 检测的良好泛化)
paper:https://arxiv.org/abs/2203.12208
code:https://github.com/liangchen527/SLADD
表情识别
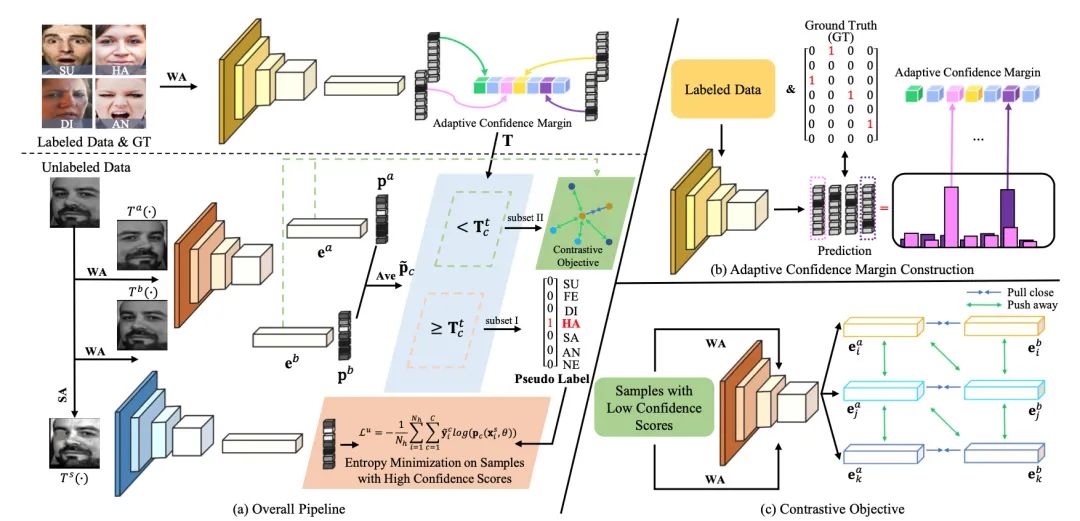
[1] Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin(具有自适应置信度的半监督深度面部表情识别)
paper:https://arxiv.org/abs/2203.12341
code:https://github.com/hangyu94/Ada-CM
图像处理
图像复原/图像重建
[1] Mask-guided Spectral-wise Transformer for Efficient Hyperspectral Image Reconstruction(用于高效高光谱图像重建的掩模引导光谱变换器)
paper:https://arxiv.org/abs/2111.07910
code:https://github.com/caiyuanhao1998/MST/
[2] Come-Closer-Diffuse-Faster: Accelerating Conditional Diffusion Models for Inverse Problems through Stochastic Contraction(通过随机收缩加速逆问题的条件扩散模型)
paper:https://arxiv.org/abs/2112.05146
[3] Exploring and Evaluating Image Restoration Potential in Dynamic Scenes(探索和评估动态场景中的图像复原潜力)
paper:https://arxiv.org/abs/2203.11754
超分辨率
[1] Local Texture Estimator for Implicit Representation Function(隐式表示函数的局部纹理估计器)
paper:https://arxiv.org/abs/2111.08918
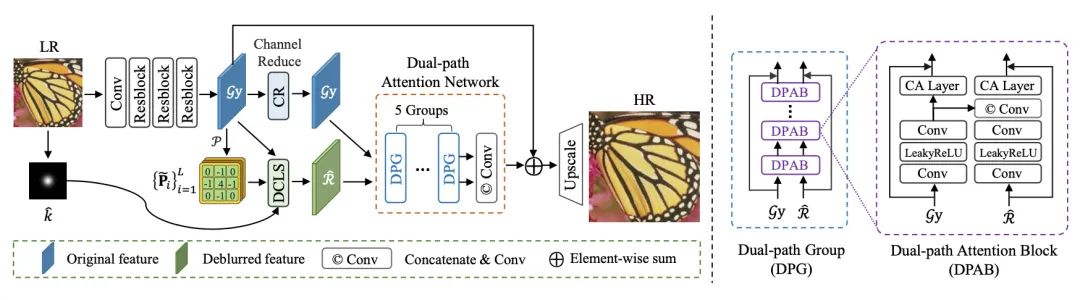
[2] Deep Constrained Least Squares for Blind Image Super-Resolution(用于盲图像超分辨率的深度约束最小二乘)
paper:https://arxiv.org/abs/2202.07508
[3] High-Resolution Image Harmonization via Collaborative Dual Transformations(通过协作双变换实现高分辨率图像协调)
paper:https://arxiv.org/abs/2109.06671
code:https://github.com/bcmi/CDTNet-High-Resolution-Image-Harmonization
图像去噪/去雨
[1] IDR: Self-Supervised Image Denoising via Iterative Data Refinement(通过迭代数据细化的自监督图像去噪)
paper:https://arxiv.org/abs/2111.14358
code:https://github.com/zhangyi-3/IDR
[2] AP-BSN: Self-Supervised Denoising for Real-World Images via Asymmetric PD and Blind-Spot Network(通过非对称 PD 和盲点网络对真实世界图像进行自监督去噪)
paper:https://arxiv.org/abs/2203.11799
code:https://github.com/wooseoklee4/AP-BSN
[3] CVF-SID: Cyclic multi-Variate Function for Self-Supervised Image Denoising by Disentangling Noise from Image(通过从图像中分离噪声的自监督图像去噪的循环多变量函数)
paper:https://arxiv.org/abs/2203.13009
code:https://github.com/Reyhanehne/CVF-SID_PyTorch
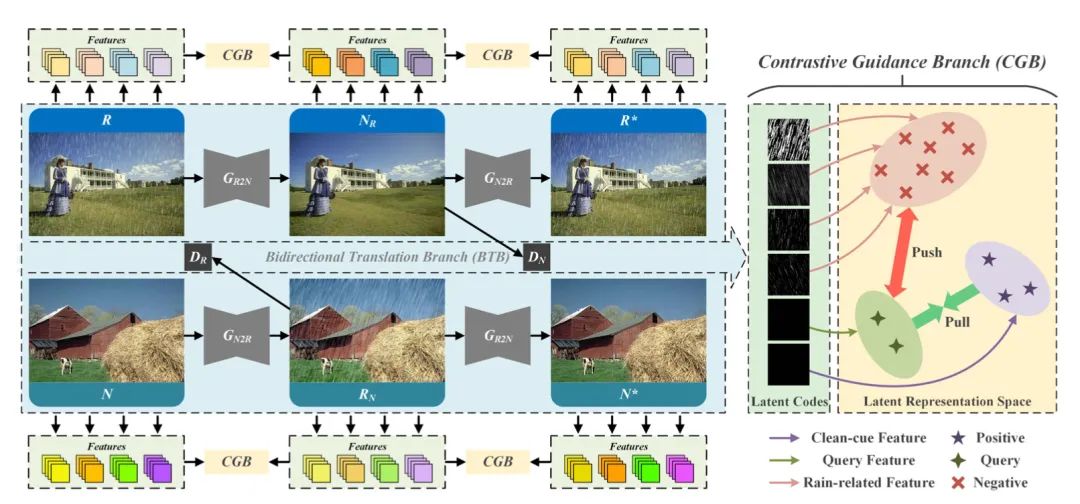
[4] Unpaired Deep Image Deraining Using Dual Contrastive Learning(使用双重对比学习的非配对深度图像去雨)
paper:https://arxiv.org/abs/2109.02973
风格迁移
[1] Industrial Style Transfer with Large-scale Geometric Warping and Content Preservation(具有大规模几何变形和内容保留的工业风格迁移)
paper:https://arxiv.org/abs/2203.12835
project:https://jcyang98.github.io/InST/home.html
code:https://github.com/jcyang98/InST
[2] Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer(基于示例的高分辨率肖像风格迁移)
paper:https://arxiv.org/abs/2203.13248
code:https://github.com/williamyang1991/DualStyleGAN
project:https://www.mmlab-ntu.com/project/dualstylegan/
图像翻译
[1] Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation(未配对图像到图像翻译的最大空间扰动一致性)
paper:https://arxiv.org/abs/2203.12707
code:https://github.com/batmanlab/MSPC
[2] Globetrotter: Connecting Languages by Connecting Images(通过连接图像连接语言)
paper:https://arxiv.org/abs/2012.04631
三维视觉
[1] Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings(在 3D 网格中嵌入消息并从 2D 渲染中提取它们)
paper:https://arxiv.org/abs/2104.13450
[2] The Neurally-Guided Shape Parser: Grammar-based Labeling of 3D Shape Regions with Approximate Inference(神经引导的形状解析器:具有近似推理的 3D 形状区域的基于语法的标记)
paper:https://arxiv.org/abs/2106.12026
code:https://github.com/rkjones4/NGSP
点云
[1] No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces(没有痛苦,收获很大:通过拟合特征级时空表面,用静态模型对动态点云序列进行分类)
paper:https://arxiv.org/abs/2203.11113
code:https://github.com/jx-zhong-for-academic-purpose/Kinet
[2] IDEA-Net: Dynamic 3D Point Cloud Interpolation via Deep Embedding Alignment(通过深度嵌入对齐的动态 3D 点云插值)
paper:https://arxiv.org/abs/2203.11590
code:https://github.com/ZENGYIMING-EAMON/IDEA-Net.git
[3] AziNorm: Exploiting the Radial Symmetry of Point Cloud for Azimuth-Normalized 3D Perception(利用点云的径向对称性进行方位归一化 3D 感知)
paper:https://arxiv.org/abs/2203.13090
code:https://github.com/hustvl/AziNorm
[4] WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation(为对抗性 3D 点云生成扭曲多个均匀先验)
paper:https://arxiv.org/abs/2203.12917
code:https://github.com/yztang4/WarpingGAN.git
三维重建
[1] Input-level Inductive Biases for 3D Reconstruction(用于 3D 重建的输入级归纳偏差)
paper:https://arxiv.org/abs/2112.03243
[2] ϕ-SfT: Shape-from-Template with a Physics-Based Deformation Model(具有基于物理的变形模型的模板形状)
paper:https://arxiv.org/abs/2203.11938
code:https://4dqv.mpi-inf.mpg.de/phi-SfT/
[3] PLAD: Learning to Infer Shape Programs with Pseudo-Labels and Approximate Distributions(学习用伪标签和近似分布推断形状程序)
paper:https://arxiv.org/abs/2011.13045
code:https://github.com/rkjones4/PLAD
[4] Neural Reflectance for Shape Recovery with Shadow Handling(使用阴影处理进行形状恢复的神经反射)
paper:https://arxiv.org/abs/2203.12909
code:https://github.com/junxuan-li/Neural-Reflectance-PS
场景重建/视图合成
[1] GeoNeRF: Generalizing NeRF with Geometry Priors(用几何先验概括 NeRF)
paper:https://arxiv.org/abs/2111.13539
code:https://www.idiap.ch/paper/geonerf
[2] NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction(用于大规模场景重建的融合辐射场)
paper:https://arxiv.org/abs/2203.11283
[3] PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo(从多视图立体重建 3D 平面)
paper:https://arxiv.org/abs/2203.12082
视频处理
[1] Unifying Motion Deblurring and Frame Interpolation with Events(将运动去模糊和帧插值与事件统一起来)
paper:https://arxiv.org/abs/2203.12178
视频编辑
[1] M3L: Language-based Video Editing via Multi-Modal Multi-Level Transformers(M3L:通过多模式多级transformer进行基于语言的视频编辑)
paper:https://arxiv.org/abs/2104.01122
场景图生成
[1] Stacked Hybrid-Attention and Group Collaborative Learning for Unbiased Scene Graph Generation(用于无偏场景图生成的堆叠混合注意力和组协作学习)
paper:https://arxiv.org/abs/2203.09811
code:https://github.com/dongxingning/SHA-GCL-for-SGG
迁移学习/domain
[1] Learning Affordance Grounding from Exocentric Images(从离中心图像中学习可供性基础)
paper:https://arxiv.org/abs/2203.09905
code:http://github.com/lhc1224/Cross-View-AG
[2] Compound Domain Generalization via Meta-Knowledge Encoding(基于元知识编码的复合域泛化)
paper:https://arxiv.org/abs/2203.13006
对抗式
[1] DTA: Physical Camouflage Attacks using Differentiable Transformation Network(使用可微变换网络的物理伪装攻击)
paper:https://arxiv.org/abs/2203.09831
code:https://islab-ai.github.io/dta-cvpr2022/
[2] Subspace Adversarial Training(子空间对抗训练)
paper:https://arxiv.org/abs/2111.12229
code:https://github.com/nblt/Sub-AT
数据集
[1] M5Product: Self-harmonized Contrastive Learning for E-commercial Multi-modal Pretraining(电子商务多模态预训练的自协调对比学习)(多模态预训练数据集)
paper:https://arxiv.org/abs/2109.04275
[2] Egocentric Prediction of Action Target in 3D(以自我为中心的 3D 行动目标预测)(
机器人)
paper:https://arxiv.org/abs/2203.13116
project:https://ai4ce.github.io/EgoPAT3D/
[3] DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation(用于语义变化分割的每日多光谱卫星数据集)
paper:https://arxiv.org/abs/2203.12560
data:https://mediatum.ub.tum.de/1650201
website:https://codalab.lisn.upsaclay.fr/competitions/2882
数据处理
[1] Dataset Distillation by Matching Training Trajectories(通过匹配训练轨迹进行数据集蒸馏)(
数据集蒸馏)
paper:https://arxiv.org/abs/2203.11932
code:https://github.com/GeorgeCazenavette/mtt-distillation
project:https://georgecazenavette.github.io/mtt-distillation/
图像压缩
[1] Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression(用于高效神经图像压缩的统一多元高斯混合)
paper:https://arxiv.org/abs/2203.10897
code:https://github.com/xiaosu-zhu/McQuic
[2] ELIC: Efficient Learned Image Compression with Unevenly Grouped Space-Channel Contextual Adaptive Coding(具有不均匀分组的空间通道上下文自适应编码的高效学习图像压缩)
paper:https://arxiv.org/abs/2203.10886
归一化
[1] Delving into the Estimation Shift of Batch Normalization in a Network(深入研究网络中批量标准化的估计偏移)
paper:https://arxiv.org/abs/2203.10778
code:https://github.com/huangleiBuaa/XBNBlock
视觉表征学习
[1] SimAN: Exploring Self-Supervised Representation Learning of Scene Text via Similarity-Aware Normalization(通过相似性感知归一化探索场景文本的自监督表示学习)
paper:https://arxiv.org/abs/2203.10492
[1] Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization(通过节点到邻域互信息最大化的图中节点表示学习)
paper:https://arxiv.org/abs/2203.12265
code:https://github.com/dongwei156/n2n
神经网络结构设计
[1] DyRep: Bootstrapping Training with Dynamic Re-parameterization(使用动态重新参数化的引导训练)
paper:https://arxiv.org/abs/2203.12868
code:https://github.com/hunto/DyRep
CNN
[1] TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing(用于布局感知视觉处理的高效翻译变体卷积)(动态卷积)
paper:https://arxiv.org/abs/2203.10489
code:https://github.com/JierunChen/TVConv
Transformer
[5] Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training(引导 ViT:从预训练中解放视觉transformer)
paper:https://arxiv.org/abs/2112.03552
code:https://github.com/zhfeing/Bootstrapping-ViTs-pytorch
神经网络架构搜索
[1] Training-free Transformer Architecture Search(免训练transformer架构搜索)
paper:https://arxiv.org/abs/2203.12217
模型训练/泛化
[6] Out-of-distribution Generalization with Causal Invariant Transformations(具有因果不变变换的分布外泛化)
paper:https://arxiv.org/abs/2203.11528
噪声标签
[1] Scalable Penalized Regression for Noise Detection in Learning with Noisy Labels(带有噪声标签的学习中噪声检测的可扩展惩罚回归)
paper:https://arxiv.org/abs/2203.07788
code:https://github.com/Yikai-Wang/SPR-LNL
小样本学习
[1] Ranking Distance Calibration for Cross-Domain Few-Shot Learning(跨域小样本学习的排名距离校准)
paper:https://arxiv.org/abs/2112.00260
度量学习
[1] Hyperbolic Vision Transformers: Combining Improvements in Metric Learning(双曲线视觉transformer:结合度量学习的改进)
paper:https://arxiv.org/abs/2203.10833
code:https://github.com/htdt/hyp_metric
持续学习
[1] Learning to Prompt for Continual Learning(学习提示持续学习)
paper:https://arxiv.org/abs/2112.08654
code:https://github.com/google-research/l2p
[1] Meta-attention for ViT-backed Continual Learning(ViT 支持的持续学习的元注意力)
paper:https://arxiv.org/abs/2203.11684
code:https://github.com/zju-vipa/MEAT-TIL
联邦学习
[1] Federated Class-Incremental Learning(联邦类增量学习)
paper:https://arxiv.org/abs/2203.11473
code:https://github.com/conditionWang/FCIL
[2] FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction(通过局部漂移解耦和校正与非 IID 数据进行联邦学习)
paper:https://arxiv.org/abs/2203.11751
code:https://github.com/gaoliang13/FedDC
[1] FedCor: Correlation-Based Active Client Selection Strategy for Heterogeneous Federated Learning(用于异构联邦学习的基于相关性的主动客户端选择策略)
paper:https://arxiv.org/abs/2103.13822
元学习
[1] Multidimensional Belief Quantification for Label-Efficient Meta-Learning(标签高效元学习的多维信念量化)
paper:https://arxiv.org/abs/2203.12768
强化学习
[1] Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory(具有编排记忆的演员评论家 GPT 的 3D 舞蹈生成)
paper:https://arxiv.org/abs/2203.13055
code:https://github.com/lisiyao21/Bailando/
多模态学习
视觉-语言
[1] An Empirical Study of Training End-to-End Vision-and-Language Transformers(培训端到端视觉和语言transformer的实证研究)
paper:https://arxiv.org/abs/2111.02387
code:https://github.com/zdou0830/METER
[1] VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks(视觉和语言任务的参数高效迁移学习)
paper:https://arxiv.org/abs/2112.06825
code:https://github.com/ylsung/VL_adapter
[2] Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model(预测、预防和评估:由预训练的视觉语言模型支持的解耦的文本驱动图像处理)
paper:https://arxiv.org/abs/2111.13333
code:https://github.com/zipengxuc/PPE
[3] LAFITE: Towards Language-Free Training for Text-to-Image Generation(面向文本到图像生成的无语言培训)
paper:https://arxiv.org/abs/2111.13792
code:https://github.com/drboog/Lafite
视听学习
[1] UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection(用于联合视频时刻检索和高光检测的统一多模态transformer)
paper:https://arxiv.org/abs/2203.12745
code:https://github.com/TencentARC/UMT
[2] Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation(用于协同语音手势生成的学习分层跨模式关联)
paper:https://arxiv.org/abs/2203.13161
project:https://alvinliu0.github.io/projects/HA2G
视觉预测
[1] GaTector: A Unified Framework for Gaze Object Prediction(凝视对象预测的统一框架)
paper:https://arxiv.org/abs/2112.03549
[7] Remember Intentions: Retrospective-Memory-based Trajectory Prediction(记住意图:基于回顾性记忆的轨迹预测)
paper:https://arxiv.org/abs/2203.11474
code:https://github.com/MediaBrain-SJTU/MemoNet
视频计数
[1] DR.VIC: Decomposition and Reasoning for Video Individual Counting(视频个体计数的分解与推理)
paper:https://arxiv.org/abs/2203.12335
code:https://github.com/taohan10200/DRNet
其他
Robust and Accurate Superquadric Recovery: a Probabilistic Approach(稳健且准确的超二次曲线恢复:一种概率方法)
paper:https://arxiv.org/abs/2111.14517
code:http://github.com/bmlklwx/EMS-superquadric_fitting.git
Learning from All Vehicles(向所有车辆学习)(自动驾驶)
paper:https://arxiv.org/abs/2203.11934
code:https://github.com/dotchen/LAV
demo:https://dotchen.github.io/LAV/
Mixed Differential Privacy in Computer Vision(计算机视觉中的混合差分隐私)
paper:https://arxiv.org/abs/2203.11481
Ev-TTA: Test-Time Adaptation for Event-Based Object Recognition(基于事件的对象识别的测试时间适应)
paper:https://arxiv.org/abs/2203.12247
TransVPR: Transformer-based place recognition with multi-level attention aggregation(具有多级注意力聚合的基于 Transformer 的
位置识别)(
图像匹配)
paper:https://arxiv.org/abs/2201.02001
Hierarchical Nearest Neighbor Graph Embedding for Efficient Dimensionality Reduction(用于有效降维的分层最近邻图嵌入)
paper:https://arxiv.org/abs/2203.12997
code:https://github.com/koulakis/h-nne
Moving Window Regression: A Novel Approach to Ordinal Regression(序数回归的一种新方法)
paper:https://arxiv.org/abs/2203.13122 code:https://github.com/nhshin-mcl/MWR
公众号后台回复“数据集”获取30+深度学习数据集下载~
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()