CVPR 2022 最新 65 篇论文分方向整理|包含目标检测、动作识别、人群计数等方向(附打包下载)

- 2D 目标检测
- 3D 目标检测
- 伪装目标检测
- 关键点检测
- 异常检测
- 超分辨率
- 图像翻译
- 风格迁移
- 姿态/光流估计
- 深度估计
- 点云
- 三维重建
- 场景重建/新视角合成
- 语义分割
- 实例分割
- 医学影像
- 动作识别/检测/定位
- 人群计数
- 图像/视频生成&合成
- GAN/生成式/对抗式
- 视觉预测
- 图像分类
- Transformer
- CNN
- 神经网络可解释性
- 图像特征提取与匹配
- 模型训练
- 量化
- 数据增广
- 视觉语言表征学习
- 对比学习
- 迁移学习
- 元学习
- 小样本/零样本学习
- 持续学习
- 联邦学习
- 数据集
2D 目标检测
【1】Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild
(未知感知对象检测:从开放视频中学习你不知道的东西)
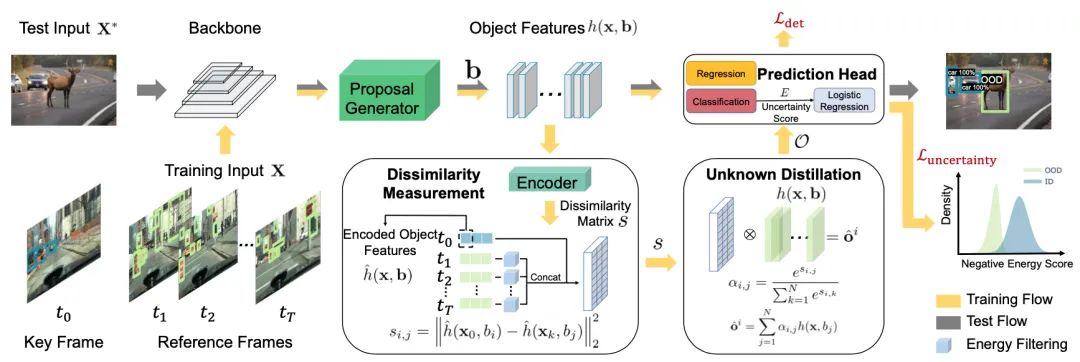
code: https://github.com/deeplearning-wisc/stud
【2】 Focal and Global Knowledge Distillation for Detectors
(探测器的焦点和全局知识蒸馏)
paper: https://arxiv.org/abs/2111.11837
code: https://github.com/yzd-v/FGD
3D 目标检测
【1】 Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D Scenes
(在 3D 场景中实现稳健的定向边界框检测)
code: https://github.com/qq456cvb/CanonicalVoting
伪装目标检测
【1】Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection
(放大和缩小:用于伪装目标检测的混合尺度三元组网络)
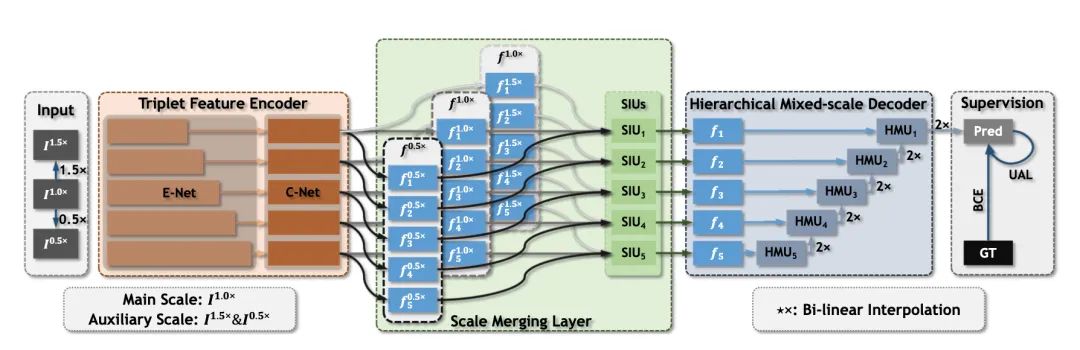
code: https://github.com/lartpang/ZoomNet
关键点检测
【1】 UKPGAN: A General Self-Supervised Keypoint Detector
(一个通用的自监督关键点检测器)
code: https://github.com/qq456cvb/UKPGAN
异常检测
【1】Generative Cooperative Learning for Unsupervised Video Anomaly Detection
(用于无监督视频异常检测的生成式协作学习)
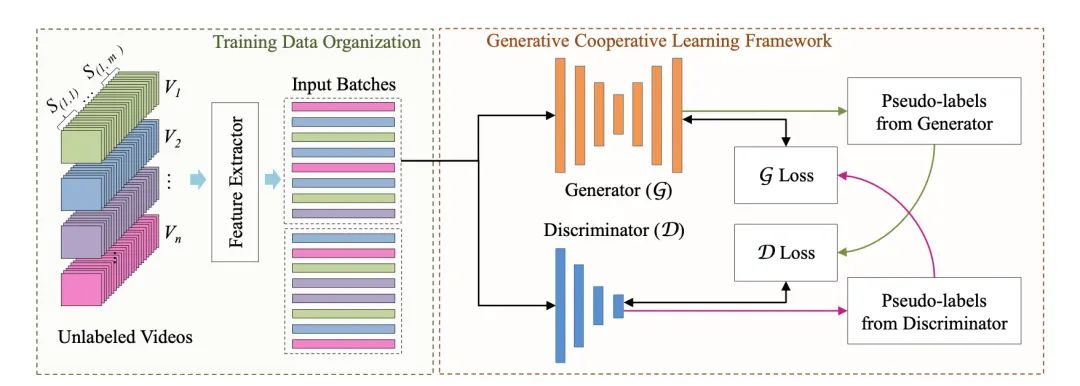
超分辨率
【1】Reflash Dropout in Image Super-Resolution
(图像超分辨率中的dropout)
【2】Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
(迈向双向任意图像缩放:联合优化和循环幂等)
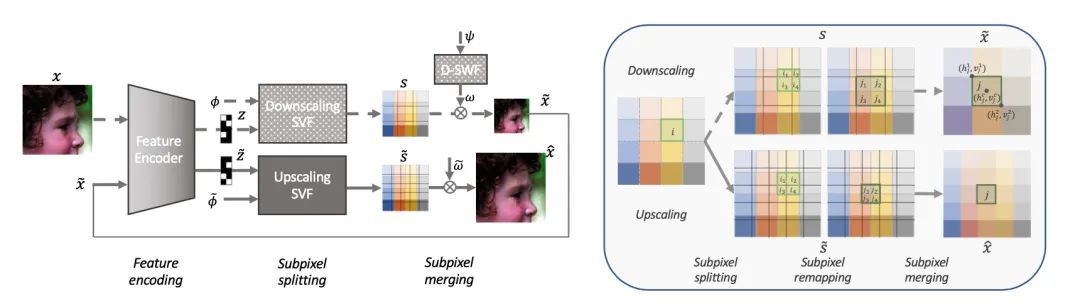
【3】【HyperTransformer: A Textural and Spectral Feature Fusion Transformer for Pansharpening
(用于全色锐化的纹理和光谱特征融合Transformer)
code: https://github.com/wgcban/HyperTransformer
图像翻译
【1】 FlexIT: Towards Flexible Semantic Image Translation
(迈向灵活的语义图像翻译)
风格迁移
【1】How Well Do Sparse Imagenet Models Transfer?
(稀疏 Imagenet 模型的迁移效果如何?)
【2】Style-ERD: Responsive and Coherent Online Motion Style Transfer
(响应式和连贯的在线运动风格迁移)
姿态/光流估计
【1】CPPF: Towards Robust Category-Level 9D Pose Estimation in the Wild(CPPF:在开放世界实现稳健的类别级 9D 位姿估计)
code: https://github.com/qq456cvb/CPPF
【2】OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation(用于基于深度的 6D 对象位姿估计的对象视点编码)
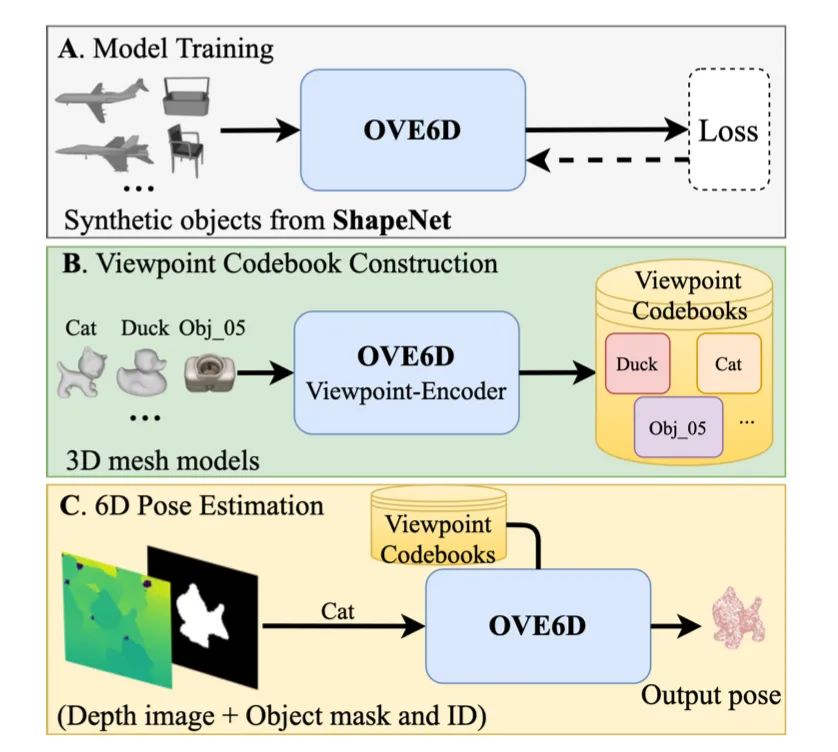
code: https://github.com/dingdingcai/OVE6D-pose
【3】CamLiFlow: Bidirectional Camera-LiDAR Fusion for Joint Optical Flow and Scene Flow Estimation(用于联合光流和场景流估计的双向相机-LiDAR 融合)
【4】Forecasting Characteristic 3D Poses of Human Actions
(预测人类行为的特征 3D 姿势)
project: https://charposes.christian-diller.de/
video: https://youtu.be/kVhn8OWMgME
深度估计
【1】Rethinking Depth Estimation for Multi-View Stereo: A Unified Representation and Focal Loss
(重新思考多视图立体的深度估计:统一表示和焦点损失)
code: https://github.com/prstrive/UniMVSNet
【2】 ChiTransformer:Towards Reliable Stereo from Cues
(从线索走向可靠的立体声)
点云
【1】Shape-invariant 3D Adversarial Point Clouds
(形状不变的 3D 对抗点云)
code: https://github.com/shikiw/SI-Adv
【2】ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
(通过对抗旋转提高点云分类器的旋转鲁棒性)
【3】Lepard: Learning partial point cloud matching in rigid and deformable scenes
(Lepard:在刚性和可变形场景中学习部分点云匹配)

code: https://github.com/rabbityl/lepard
三维重建
【1】Neural Face Identification in a 2D Wireframe Projection of a Manifold Object(流形对象的二维线框投影中的神经人脸识别)
code: https://manycore- research.github.io/faceformer
project: https://manycore-research.github.io/faceformer
【2】Generating 3D Bio-Printable Patches Using Wound Segmentation and Reconstruction to Treat Diabetic Foot Ulcers(使用伤口分割和重建生成 3D 生物可打印贴片以治疗糖尿病足溃疡)
paper: https://arxiv.org/pdf/2203.03814.pdf
场景重建/新视角合成
【1】Point-NeRF: Point-based Neural Radiance Fields
(基于点的神经辐射场)
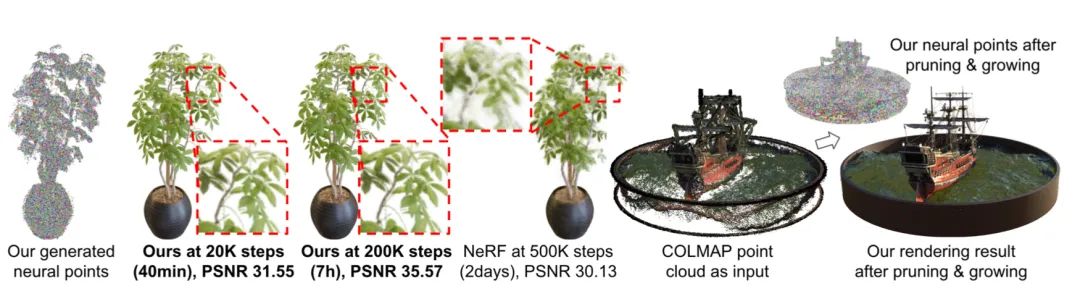
code: https://github.com/Xharlie/pointnerf
project: https://xharlie.github.io/projects/project_sites/pointnerf
语义分割
【1】Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
(使用不可靠伪标签的半监督语义分割)
code: https://github.com/Haochen-Wang409/U2PL/
project: https://haochen-wang409.github.io/U2PL/
【2】Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
(使用分布外数据的弱监督语义分割)
code: https://github.com/naver-ai/w-ood)
【3】Self-supervised Image-specific Prototype Exploration for Weakly Supervised Semantic Segmentation
(弱监督语义分割的自监督图像特定原型探索)
code: https://github.com/chenqi1126/SIPE
【4】Multi-class Token Transformer for Weakly Supervised Semantic Segmentation
(用于弱监督语义分割的多类token Transformer)
code: https://github.com/xulianuwa/MCTformer
【5】Cross Language Image Matching for Weakly Supervised Semantic Segmentation
(用于弱监督语义分割的跨语言图像匹配)
【6】Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
(从注意力中学习亲和力:使用 Transformers 的端到端弱监督语义分割)
code: https://github.com/rulixiang/afa
实例分割
【1】 E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation
(一种基于端到端轮廓的高质量高速实例分割方法)
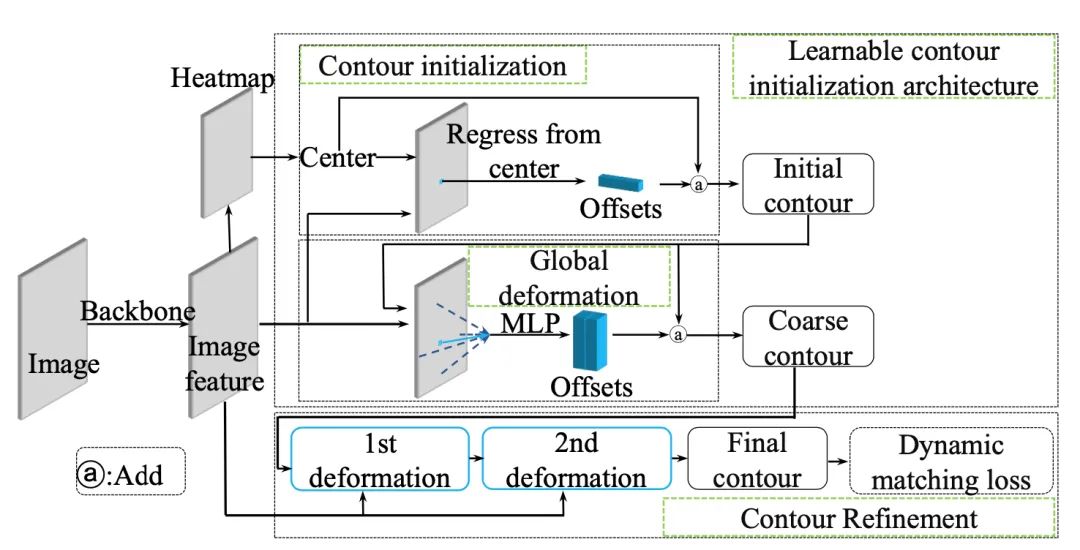
code: https://github.com/zhang-tao-whu/e2ec
医学影像
【1】Adaptive Early-Learning Correction for Segmentation from Noisy Annotations
(从噪声标签中分割的自适应早期学习校正)
paper: https://arxiv.org/abs/2110.03740
code: https://github.com/Kangningthu/ADELE
动作识别/检测/定位
【1】End-to-End Semi-Supervised Learning for Video Action Detection
(视频动作检测的端到端半监督学习)
【2】Learnable Irrelevant Modality Dropout for Multimodal Action Recognition on Modality-Specific Annotated Videos
(模态特定注释视频上多模态动作识别的可学习不相关模态丢失)
【3】Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation
(通过代表性片段知识传播的弱监督时间动作定位)
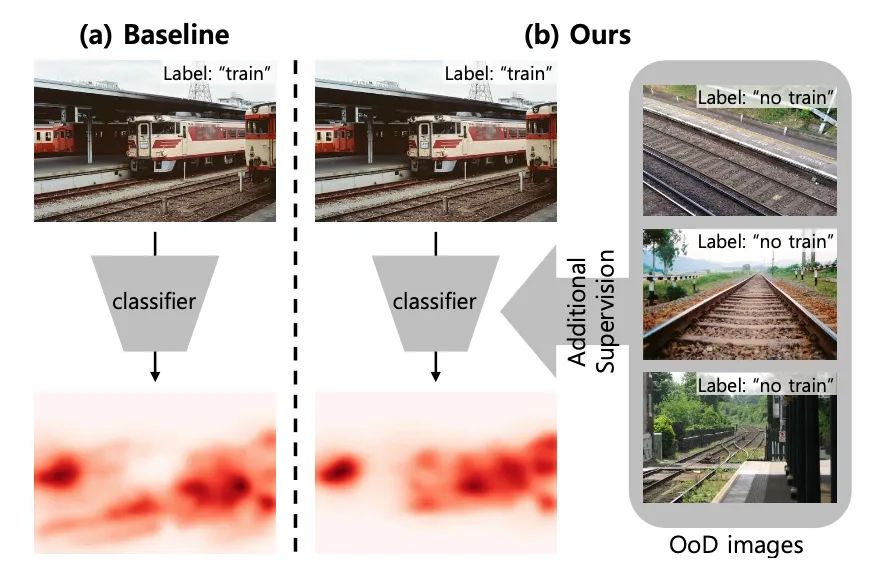
code: https://github.com/LeonHLJ/RSKP
人群计数
【1】Boosting Crowd Counting via Multifaceted Attention
(通过多方面注意提高人群计数)
code: https://github.com/LoraLinH/Boosting-Crowd-Counting-via-Multifaceted-Attention
图像/视频生成&合成
【1】Exploring Dual-task Correlation for Pose Guided Person Image Generation
(探索姿势引导人物图像生成的双任务相关性)
code: https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network
【2】Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
(告诉我什么并告诉我如何:通过多模式调节进行视频合成)
code: https://github.com/snap-research/MMVID
【3】 Dynamic Dual-Output Diffusion Models
(动态双输出扩散模型)
GAN/生成式/对抗式
【1】Shadows can be Dangerous: Stealthy and Effective Physical-world Adversarial Attack by Natural Phenomenon
(阴影可能很危险:自然现象的隐秘而有效的物理世界对抗性攻击)
【2】Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-robust Makeup Transfer
(保护面部隐私:通过风格稳健的化妆转移生成对抗性身份面具)
【3】Adversarial Texture for Fooling Person Detectors in the Physical World
(物理世界中愚弄人体探测器的对抗性纹理)
视觉预测
【1】Motron: Multimodal Probabilistic Human Motion Forecasting
(多模式概率人体运动预测)
【2】 How many Observations are Enough? Knowledge Distillation for Trajectory Forecasting
(多少个观察就足够了?轨迹预测的知识蒸馏)
paper: https://arxiv.org/abs/2203.04781
图像分类
【1】 GlideNet: Global, Local and Intrinsic based Dense Embedding NETwork for Multi-category Attributes Prediction
(用于多类别属性预测的基于全局、局部和内在的密集嵌入网络)
paper: https://arxiv.org/abs/2203.03079
code: https://github.com/kareem-metwaly/glidenet
project: http://signal.ee.psu.edu/research/glidenet.html
Transformer
【1】Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
(深入研究分布变化下的视觉Transformer的泛化)
paper: https://arxiv.org/abs/2106.07617
code: https://github.com/Phoenix1153/ViT_OOD_generalization
CNN
【1】DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos
(视频中稀疏帧差异的端到端 CNN 推断)
paper: https://arxiv.org/abs/2203.03996
神经网络可解释性
【1】Interpretable part-whole hierarchies and conceptual-semantic relationships in neural networks
(神经网络中可解释的部分-整体层次结构和概念语义关系)
图像特征提取与匹配
【1】 Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
(弱监督语义对应的概率扭曲一致性)
code: https://github.com/PruneTruong/DenseMatching
模型训练
【1】Towards Efficient and Scalable Sharpness-Aware Minimization(迈向高效和可扩展的锐度感知最小化)
paper: https://arxiv.org/abs/2203.02714
量化
【1】IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
(学习具有类内异质性的合成图像以进行零样本网络量化)
code: https://github.com/zysxmu/IntraQ
数据增广
【1】TeachAugment: Data Augmentation Optimization Using Teacher Knowledge
(使用教师知识进行数据增强优化)
code: https://github.com/DensoITLab/TeachAugment
视觉语言表征学习
【1】L-Verse: Bidirectional Generation Between Image and Text
(图像和文本之间的双向生成) (Oral Presentation)
对比学习
【1】Selective-Supervised Contrastive Learning with Noisy Labels
(带有噪声标签的选择性监督对比学习)
code: https://github.com/ShikunLi/Sel-CL
迁移学习
【1】A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation
(用于手语翻译的简单多模态迁移学习基线)
元学习
【1】 What Matters For Meta-Learning Vision Regression Tasks?
(元学习视觉回归任务的重要性是什么?)
小样本/零样本学习
【1】Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
(小样本分类的相互集中学习)
【2】MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
(用于零样本学习的相互语义蒸馏网络)
paper: https://arxiv.org/abs/2203.03137
code: https://github.com/shiming-chen/MSDN
持续学习
【1】On Generalizing Beyond Domains in Cross-Domain Continual Learning
(关于跨域持续学习中的域外泛化)
联邦学习
【1】 Differentially Private Federated Learning with Local Regularization and Sparsification
(局部正则化和稀疏化的差分私有联邦学习)
数据集
【1】Kubric: A scalable dataset generator
(Kubric:可扩展的数据集生成器)
code: https://github.com/google-research/kubric
【2】A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
(用于分段级视频复制检测的大规模综合数据集和复制重叠感知评估协议)
dataset, metric and benchmark codes: https://github.com/alipay/VCSL
其他
【1】Contrastive Conditional Neural Processes
(对比条件神经过程)
【2】Deep Rectangling for Image Stitching: A Learning Baseline
(图像拼接的深度矩形:学习基线)
code: https://github.com/nie-lang/DeepRectangling
【3】Online Learning of Reusable Abstract Models for Object Goal Navigation
(对象目标导航可重用抽象模型的在线学习)

公众号后台回复“数据集”获取50+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文