一文看尽 CVPR2022 最新 22 篇论文(附打包下载)

极市导读
本文汇总了22篇最新放出的CVPR 2022网络架构设计、姿态估计、语义分割、动作检测、三维视觉等方向的论文,附文章打包下载地址。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
神经网络架构设计
[1] An Image Patch is a Wave: Quantum Inspired Vision MLP(量子启发的视觉 MLP)
paper:https://arxiv.org/abs/2111.12294
code1:https://github.com/huawei-noah/CV-Backbones/tree/master/wavemlp_pytorch
code2:https://gitee.com/mindspore/models/tree/master/research/cv/wave_mlp
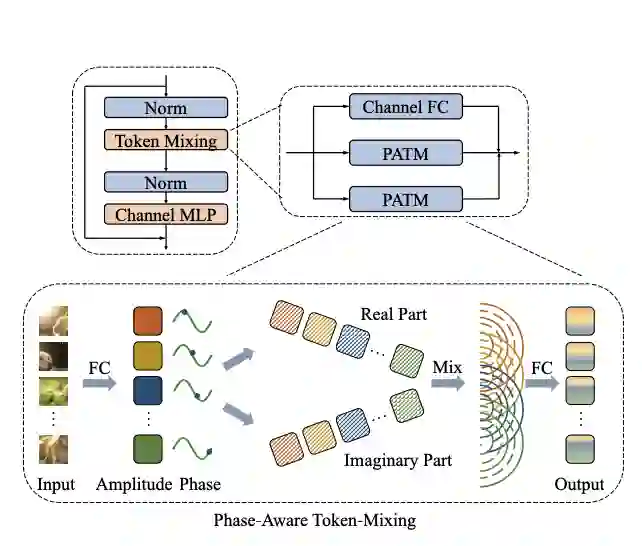
在CV领域的最近工作表明,主要由全连接层堆叠的纯 MLP 架构可以实现与 CNN 和 Transformer 竞争的性能。视觉 MLP 的输入图像通常被拆分为多个tokens,而现有的 MLP 模型直接将它们以固定的权重聚合,忽略了来自不同图像的tokens的变化语义信息。为了动态聚合tokens,本文建议将每个token表示为具有振幅和相位两部分的波函数。基于类波token表示,本文为视觉任务建立了一种新颖的 Wave-MLP 架构。大量实验表明,在图像分类、对象检测和语义分割等各种视觉任务上,所提出的 Wave-MLP 优于最先进的 MLP 架构。
【2】 A ConvNet for the 2020s
paper:https://arxiv.org/abs/2201.03545
code:https://github.com/facebookresearch/ConvNeXt
详细解读:“文艺复兴” ConvNet卷土重来,压过Transformer!FAIR重新设计纯卷积新架构
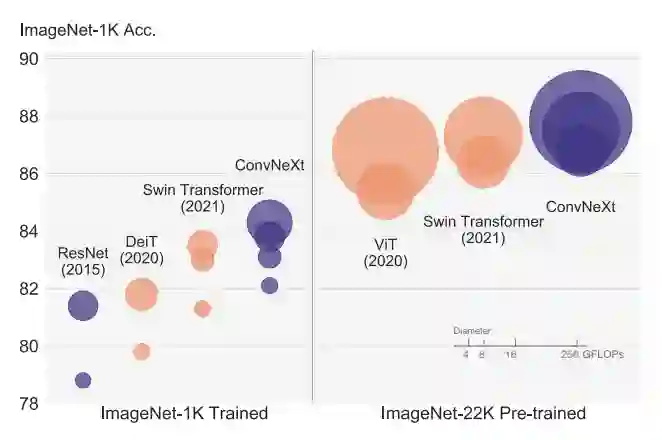
这项工作重新检查了设计空间并测试了纯 ConvNet 所能达到的极限。本文逐渐将标准 ResNet “现代化”为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。这一探索的结果是一系列纯 ConvNet 模型,称为 ConvNeXt。ConvNeXts 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面与 Transformer 竞争,实现 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformers,同时保持标准 ConvNet 的简单性和效率。
【3】Mobile-Former: Bridging MobileNet and Transformer(连接 MobileNet 和 Transformer)
paper:https://arxiv.org/abs/2108.05895
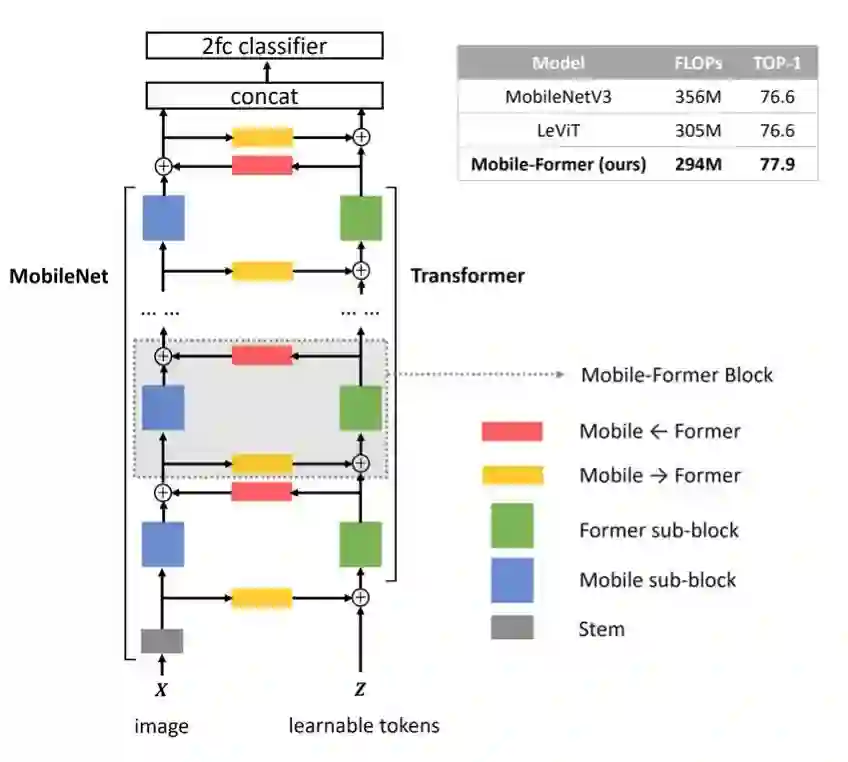
Mobile-Former是一种 MobileNet 和 Transformer 的并行设计,中间有一个双向桥,这种结构利用了 MobileNet 在本地处理和全局交互中的 Transformer 的优势,同时可以实现局部和全局特征的双向融合。
Mobile-Former 中的 Transformer 包含 token 非常少( 6 个或更少),并随机初始化这些 token 来学习全局先验,从而降低计算成本。结合提出的轻量级交叉注意力对桥梁进行建模,Mobile-Former 不仅计算效率高,而且具有更强的表示能力。它在低 FLOP 状态下性能优于 MobileNetV3。此外,通过用 Mobile-Former 替换 DETR 中的主干、编码器和解码器来构建的检测器性能优于 DETR 1.1 AP,但节省了 52% 的计算成本和 36% 的参数。
【4】BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning(学习探索样本关系以进行鲁棒表征学习)
paper:https://arxiv.org/abs/2203.01522
code:https://github.com/zhihou7/BatchFormer
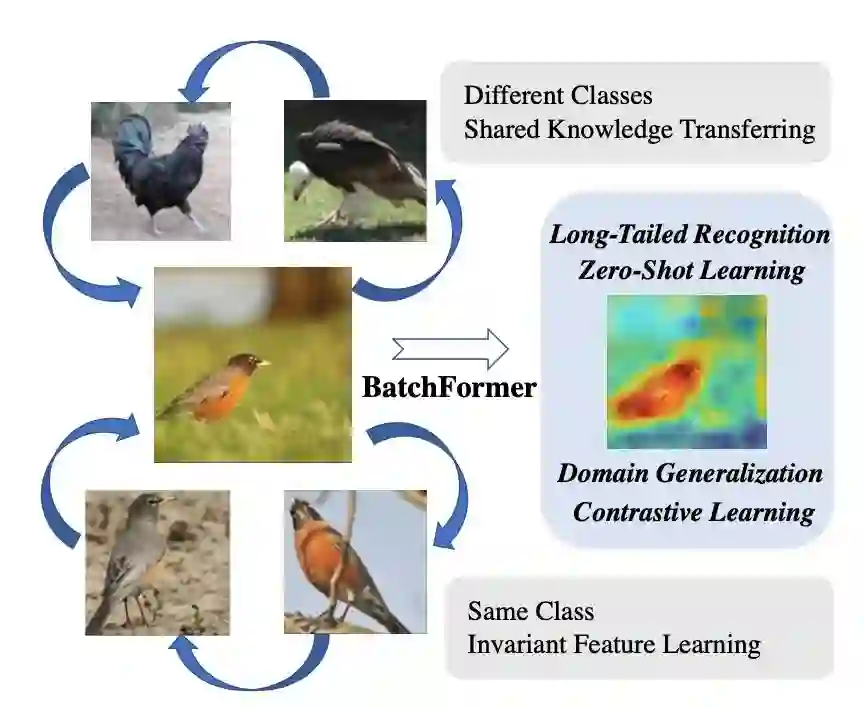
本文的目的在于让深度神经网络本身能够探索每个mini-batch的样本关系。具体操作上,本文引入了一个batch transformer模块,即BatchFormer,将其应用于每个mini-batch的batch维度,实现在训练期间隐式探索样本关系。通过这种方法可以实现不同样本的协作,例如头类样本也可以有助于尾类的学习来进行长尾识别。在十个以上的数据集进行了广泛的实验,证明在没有其他多余操作的情况下,BatchFormer在不同的数据稀缺性问题上取得了显著的改进,包括长尾识别、组合零样本学习、域泛化和对比学习。
异常检测
【1】Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection(用于异常检测的自监督预测卷积注意力块)
paper:https://arxiv.org/abs/2111.09099
code:https://github.com/ristea/sspcab
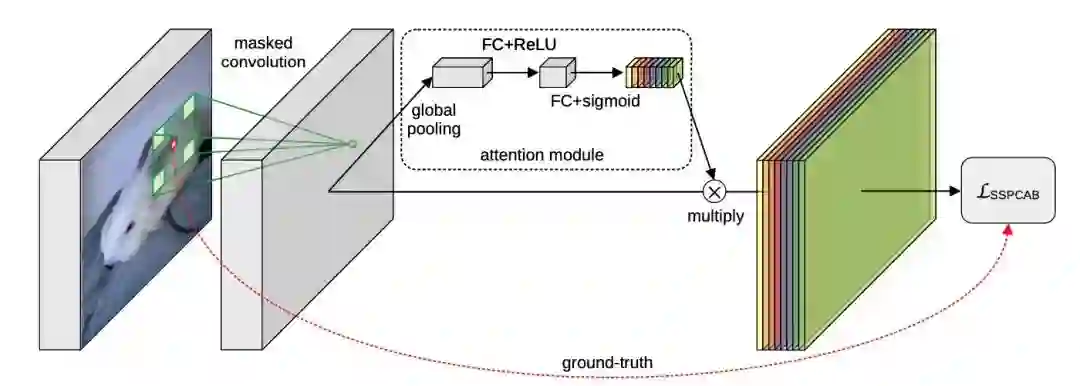
本文提出了一种由掩码卷积层和通道注意模块组成的新型模块 SSPCAB,它可以预测卷积感受野中的掩码区域。SSPCAB以自监督的方式通过自身的重建损失进行训练。这一自监督块是通用的,并且可以很容易地融入到各种最先进的异常检测方法中。SSPCAB 从一个带有扩张滤波器的卷积层开始,其中感受野的中心区域被掩码,生成的激活图通过通道注意模块传递,同时配置了一个损失,可以最大限度地减少感受野中被掩码区域的重建误差。SSPCAB 在图像和视频异常检测任务上都验证了其对性能的提升。
三维视觉
【1】 CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding(用于 3D 点云理解的自监督跨模态对比学习)
paper:https://arxiv.org/abs/2203.00680
code:http://github.com/MohamedAfham/CrossPoint
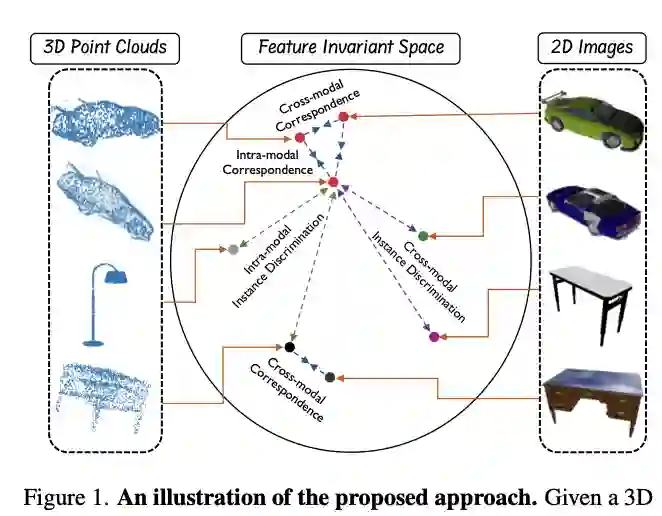
本文提出了 CrossPoint,这是一种简单的跨模态对比学习方法,用于学习可迁移的 3D 点云表示。它通过最大化点云和不变空间中相应渲染的 2D 图像之间的一致性来实现对象的 3D-2D 对应,同时鼓励对点云模态中的变换保持不变。本文的联合训练目标结合了模态内和模态之间的特征对应关系,从而以自我监督的方式集成了来自 3D 点云和 2D 图像模态的丰富学习信号。实验结果表明,本文的方法在包括 3D 对象分类和分割在内的各种下游任务上优于以前的无监督学习方法。
【2】 A Unified Query-based Paradigm for Point Cloud Understanding(一种基于统一查询的点云理解范式)
paper:https://arxiv.org/pdf/2203.01252.pdf
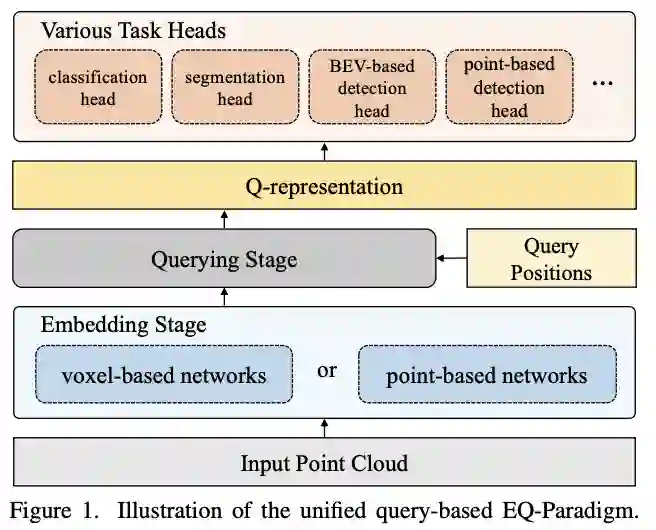
本文提出了一种新颖的嵌入查询范式 (EQ-Paradigm),用于 3D 理解任务,包括检测、分割和分类。EQ-Paradigm 是一个统一的范式,可以将任何现有的 3D 主干架构与不同的任务头结合起来。在 EQ-Paradigm 下,输入首先在嵌入阶段以任意特征提取架构进行编码,该架构独立于任务和头。然后,查询阶段使编码的特征适用于不同的任务头。这是通过在查询阶段引入中间表示(即 Q 表示)作为嵌入阶段和任务头之间的桥梁来实现的。本文设计了一个新颖的 Q-Net 作为查询阶段网络。各种 3D 任务的广泛实验结果表明,EQ-Paradigm 与 Q-Net 结合是一种通用且有效的管道,它可以实现骨干网和头部的灵活协作,并进一步提高最先进方法的性能.
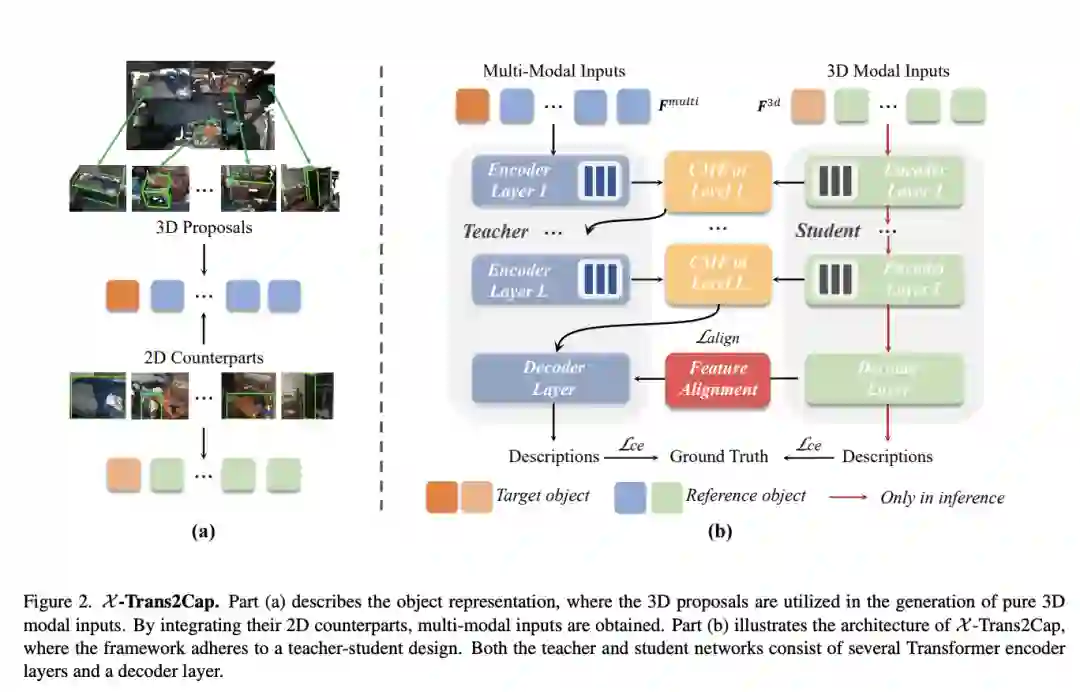
【3】 X -Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning(使用 Transformer 进行 3D 密集字幕的跨模式知识迁移)
paper:https://arxiv.org/pdf/2203.00843.pdf
本文研究了使用 Transformer 进行 3D 密集字幕的跨模式知识转移,即 X -Trans2Cap。本文提出的 X -Trans2Cap 通过师生框架支持的知识蒸馏有效地提高了单模态 3D 字幕的性能。在实践中,在训练阶段,教师网络利用辅助的 2D 模态,通过特征一致性约束引导仅以点云作为输入的学生网络。由于精心设计的跨模态特征融合模块和训练阶段的特征对齐,X-Trans2Cap 轻松获取嵌入在 2D 图像中的丰富外观信息。因此,在推理过程中只能使用点云来生成更忠实的字幕。
【4】 CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields(文本和图像驱动的神经辐射场操作)
paper:https://arxiv.org/abs/2112.05139
code:https://cassiepython.github.io/clipnerf/
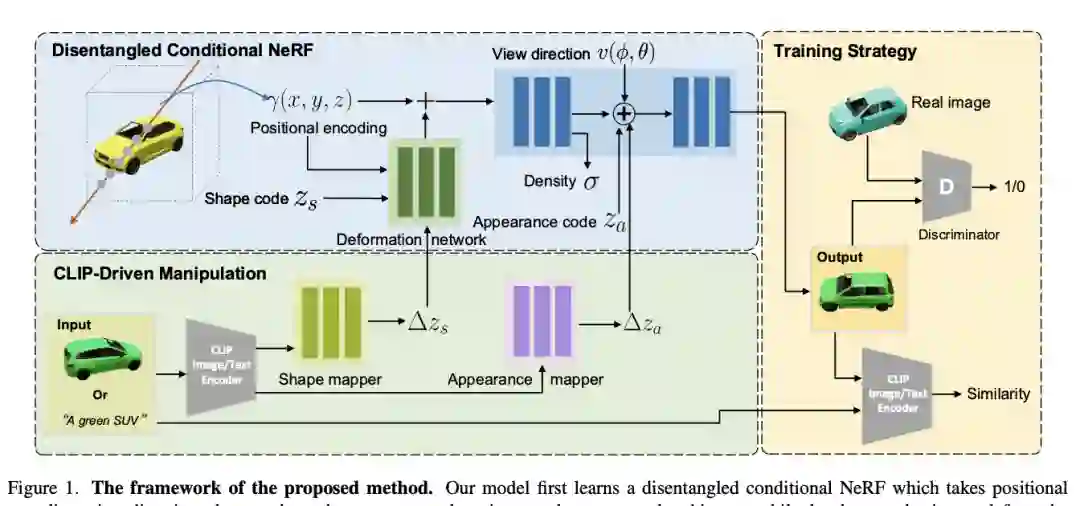
本文提出了 CLIP-NeRF,一种用于神经辐射场 (NeRF) 的多模态 3D 对象操作方法。通过利用最近的对比语言图像预训练(CLIP)模型的联合语言图像嵌入空间,本文提出了一个统一的框架,允许以用户友好的方式使用短文本提示或示例图像操作 NeRF。此外,本文提出了一种逆优化方法,该方法可以将输入图像准确地投影到潜在代码以进行操作,从而能够对真实图像进行编辑。
姿态估计
【1】 MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video(用于视频中 3D 人体姿势估计的 Seq2seq 混合时空编码器)
paper:https://arxiv.org/pdf/2203.00859.pdf
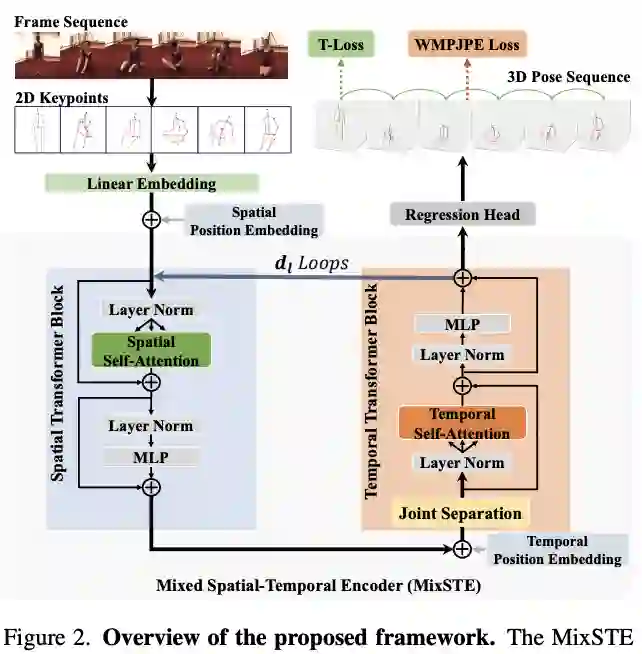
本文提出了 MixSTE(混合时空编码器),它有一个时间变换器块来分别建模每个关节的时间运动和一个空间变换器块来学习关节间的空间相关性。这两个块交替使用以获得更好的时空特征编码。此外,网络输出从中心帧扩展到输入视频的整个帧,从而提高了输入和输出序列之间的连贯性。在三个基准(即 Human3.6M、MPI-INF-3DHP 和 HumanEva)上进行了广泛的实验来评估所提出的方法。结果表明,该模型在 Human3.6M 数据集上优于最先进的方法 10.9% P-MPJPE 和 7.6% MPJPE。
【2】 H4D: Human 4D Modeling by Learning Neural Compositional Representation(通过学习神经组合表示进行人体 4D 建模)
paper:https://arxiv.org/pdf/2203.01247.pdf
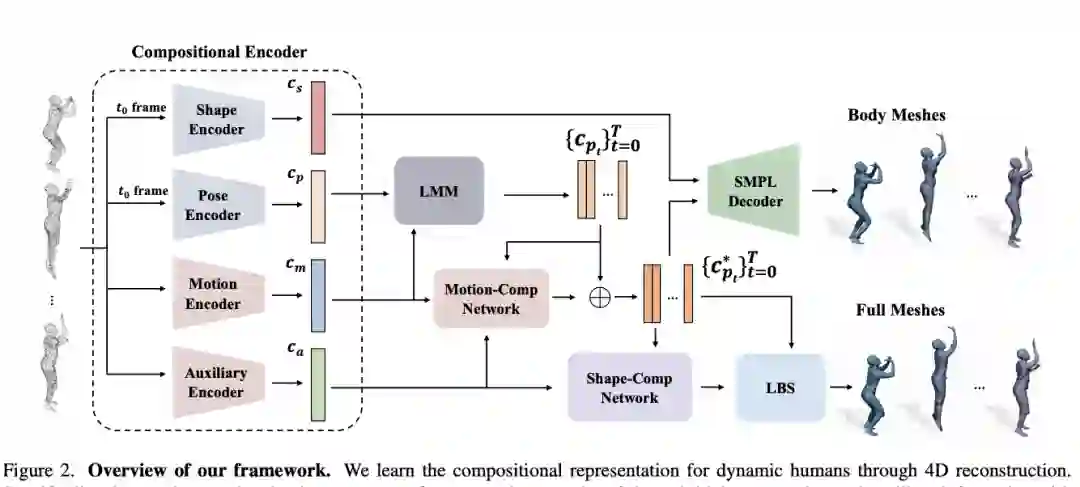
尽管基于深度学习的 3D 重建取得了令人印象深刻的成果,但对直接学习以详细几何对 4D 人体捕捉进行建模的技术的研究较少。这项工作提出了一个新颖的框架,可以通过从广泛使用的 SMPL 参数模型中利用人体先验来有效地学习动态人体的紧凑和组合表示。本文提出了一种简单而有效的线性运动模型来提供粗略和正则化的运动估计,然后使用辅助代码中编码的残差对位姿和几何细节进行每帧补偿。从技术上讲,本文引入了新的基于 GRU 的架构来促进学习和提高表示能力。
【3】 Learning Local-Global Contextual Adaptation for Multi-Person Pose Estimation(学习用于多人姿势估计的局部-全局上下文适应)
paper:https://arxiv.org/pdf/2109.03622.pdf
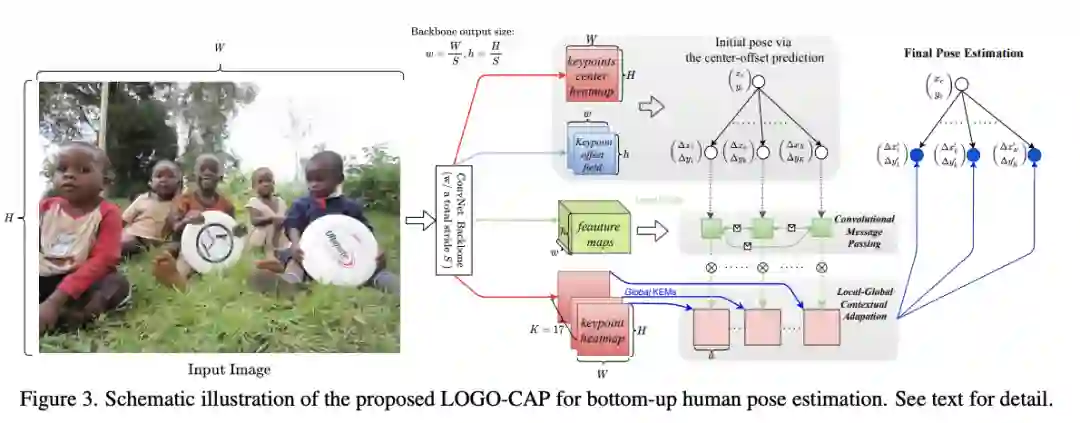
本文提出了一种多人姿态估计方法,称为 LOGO-CAP,通过学习人类姿势的 LOcal-GlObal 上下文适应。具体来说,本文的方法在第一步从小局部窗口中的局部关键点扩展图(KEM)中学习关键点吸引力图(KAM),随后将其视为以关键点为中心的全局热图上的动态卷积核,以进行上下文适应,实现准确的多人姿态估计。该方法是端到端可训练的,在单次前向传递中具有近乎实时的推理速度,在自下而上的人体姿态估计的 COCO 关键点基准上获得了最先进的性能。
图像修复
【1】 Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding(增量transformer结构增强图像修复与掩蔽位置编码)
paper:https://arxiv.org/abs/2203.00867
code:https://github.com/DQiaole/ZITS_inpainting
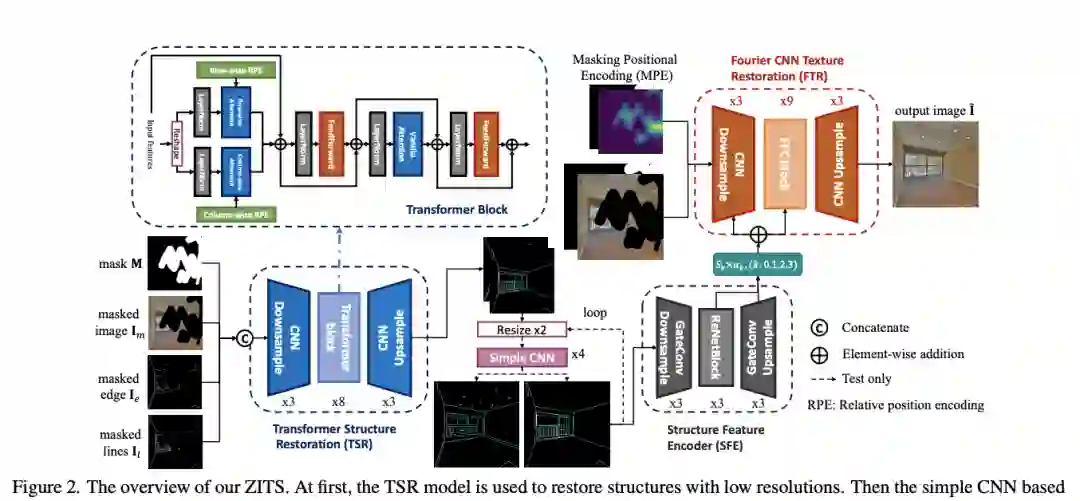
近年来,图像修复取得了重大进展。然而,恢复具有生动纹理和合理结构的损坏图像仍然具有挑战性。由于卷积神经网络 (CNN) 的感受野有限,一些特定的方法只能处理常规纹理,而会丢失整体结构。另一方面,基于注意力的模型可以更好地学习结构恢复的远程依赖性,但它们受到大图像尺寸推理的大量计算的限制。为了解决这些问题,本文建议利用额外的结构恢复器来逐步促进图像修复。所提出的模型在固定的低分辨率草图空间中使用强大的基于注意力的 Transformer 模型来恢复整体图像结构。
模型训练
【1】 DN-DETR: Accelerate DETR Training by Introducing Query DeNoising(通过引入查询去噪加速 DETR 训练)
paper:https://arxiv.org/abs/2203.01305
code:https://github.com/FengLi-ust/DN-DETR
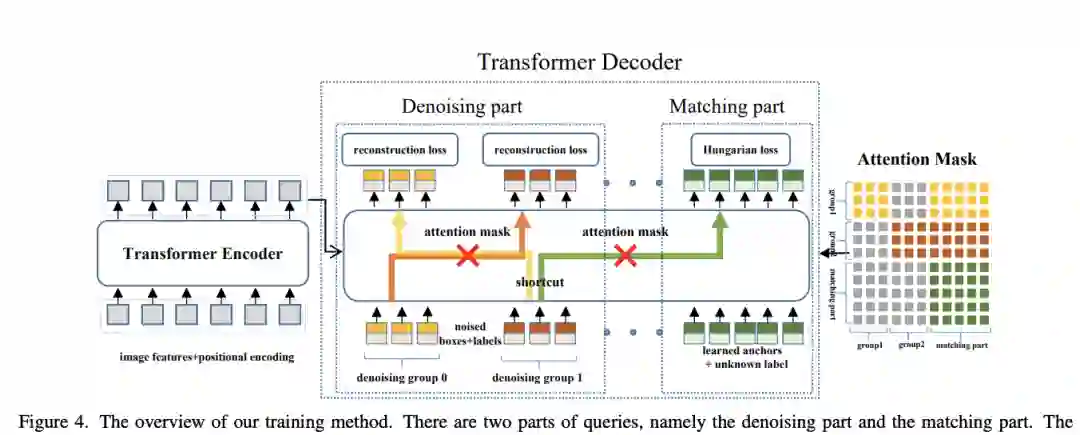
本文提出了一种新的去噪训练方法来加速DETR训练,并加深了对 DETR 类方法的缓慢收敛问题的理解。本文表明,缓慢收敛是由于二部图匹配的不稳定性导致早期训练阶段的优化目标不一致。为了解决这个问题,除了Hungarian损失之外,本文的方法还向Transformer解码器中添加了带有噪声的ground-truth边界框,并训练模型重建原始框,这有效地降低了二分图匹配难度并导致更快的收敛。该方法是通用的,可以通过添加数十行代码轻松插入任何类似 DETR 的方法中,以实现显着的改进。
视觉语言表征学习
【1】 HairCLIP: Design Your Hair by Text and Reference Image(通过文本和参考图像设计你的头发)
paper:https://arxiv.org/abs/2112.05142
project:https://github.com/wty-ustc/HairCLIP

头发编辑是计算机视觉和图形学中一个有趣且具有挑战性的问题。许多现有方法需要精心绘制的草图或蒙版作为编辑的条件输入,但是这些交互既不简单也不高效。本文提出了一种新的头发编辑交互模式,可以根据用户提供的文本或参考图像单独或联合操作头发属性。为此,本文在共享嵌入空间中对图像和文本条件进行编码,并通过利用对比语言-图像预训练(CLIP)模型强大的图像文本表示能力提出统一的头发编辑框架。通过精心设计的网络结构和损失函数,本文的框架可以以一种解开的方式执行高质量的头发编辑。
【2】 Vision-Language Pre-Training with Triple Contrastive Learning(三重对比学习的视觉语言预训练)
paper:https://arxiv.org/abs/2202.10401
code:https://github.com/uta-smile/TCL
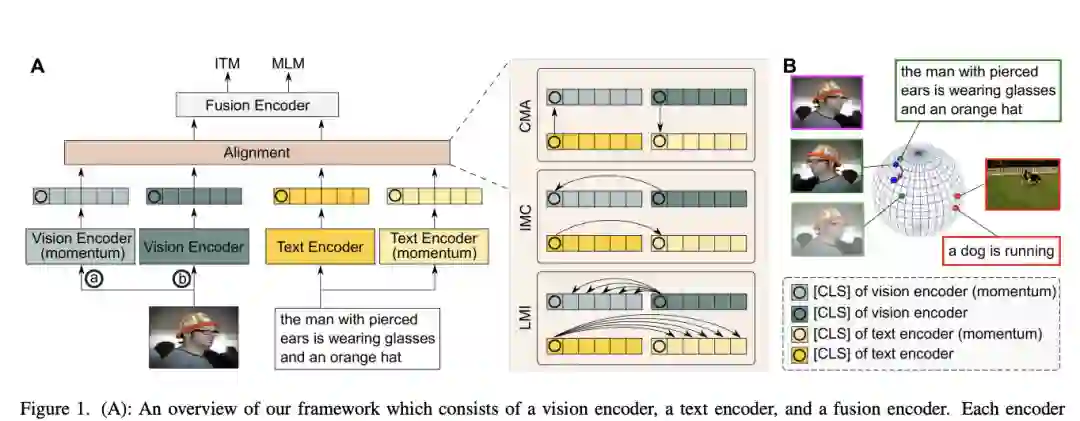
视觉语言表示学习通过对比损失(例如 InfoNCE 损失)在很大程度上受益于图像-文本对齐。这种对齐策略的成功归功于其最大化图像与其匹配文本之间的互信息 (MI) 的能力。然而,简单地执行跨模态对齐 (CMA) 会忽略每个模态中的数据潜力,这可能会导致表示下降。本文通过利用跨模态和模态内自我监督,提出了用于视觉语言预训练的三重对比学习 (TCL)。除了 CMA,TCL 还引入了模态内对比目标,以在表示学习中提供互补优势。为了利用来自图像和文本输入的本地化和结构信息,TCL 进一步最大化了图像/文本的局部区域与其全局摘要之间的平均 MI。该工作是第一个考虑多模态表示学习的局部结构信息的工作。
对比学习
【1】 Crafting Better Contrastive Views for Siamese Representation Learning(为连体表示学习制作更好的对比视图)
paper:https://arxiv.org/pdf/2202.03278.pdf
code:https://github.com/xyupeng/ContrastiveCrop

对于高性能连体表示学习,关键之一是设计好的对比对。大多数以前的工作只是简单地应用随机采样来对同一图像进行不同的裁剪,这忽略了可能降低视图质量的语义信息。本文提出 ContrastiveCrop,它可以有效地为连体表示学习生成更好的作物。值得注意的是,本文方法仔细考虑了用于对比学习的正对,而额外的训练开销可以忽略不计。作为一个即插即用且与框架无关的模块,ContrastiveCrop 在 CIFAR-10、CIFAR-100、Tiny ImageNet 和 STL-10 上持续将 SimCLR、MoCo、BYOL、SimSiam 的分类精度提高 0.4% ∼ 2.0%。
深度估计
【1】 OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion(通过几何感知融合进行 360 度单目深度估计)
paper:https://arxiv.org/abs/2203.00838
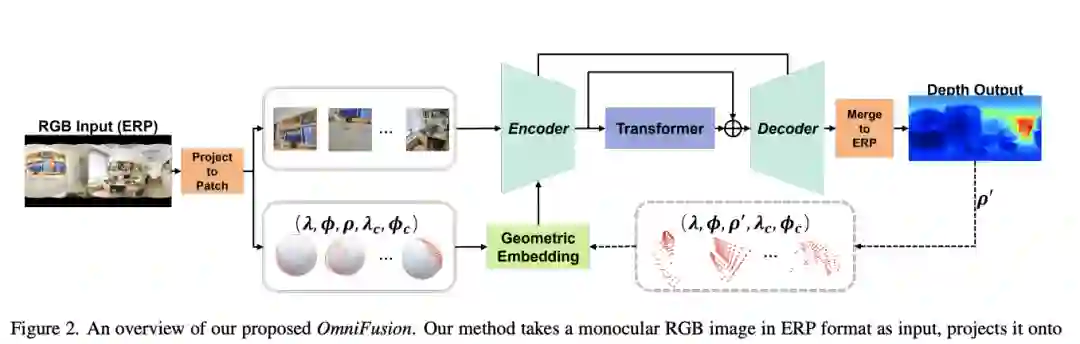
将深度学习方法应用于全向图像的一个最大的挑战是球面失真。在需要结构细节的深度估计等密集回归任务中,在扭曲的 360 度图像上使用普通 CNN 层会导致不希望的信息丢失。本文提出了一个 360 度单目深度估计管道OmniFusion,以解决球面失真问题。本文的管道将 360 度图像转换为失真较小的透视图块(即切线图像),以通过 CNN 获得块状预测,然后将块状结果合并为最终输出。为了处理补丁预测之间的差异,这是影响合并质量的主要问题,本文提出了一个具有以下关键组件的新框架。
语义分割
【1】 Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation(弱监督语义分割的类重新激活图)
paper:https://arxiv.org/pdf/2203.00962.pdf
code:https://github.com/zhaozhengChen/ReCAM
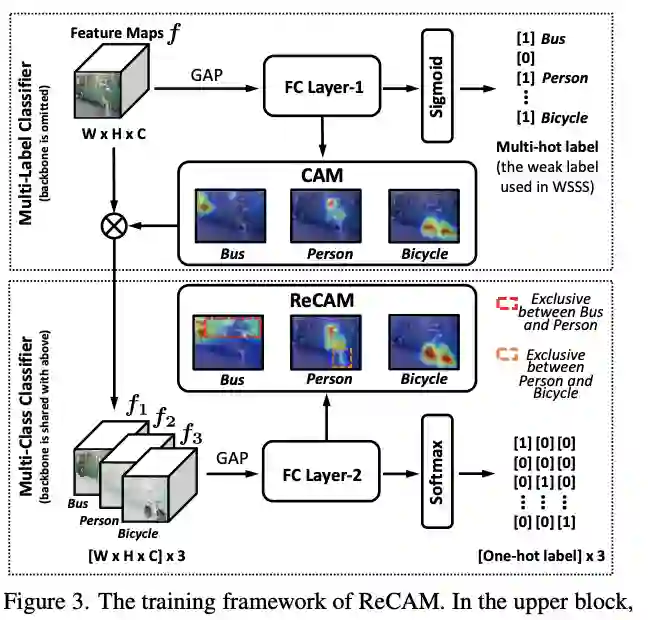
本文介绍了一种非常简单高效的方法:使用名为 ReCAM 的 softmax 交叉熵损失 (SCE) 重新激活具有 BCE 的收敛 CAM。给定一张图像,本文使用 CAM 提取每个类的特征像素,并使用它们与类标签一起使用 SCE 学习另一个全连接层(在主干之后)。收敛后,本文以与 CAM 中相同的方式提取 ReCAM。由于 SCE 的对比性质,像素响应被分解为不同的类别,因此预期的掩码模糊性会更小。对 PASCAL VOC 和 MS COCO 的评估表明,ReCAM 不仅可以生成高质量的遮罩,还可以在任何 CAM 变体中以很少的开销支持即插即用。
动作检测
【1】 Colar: Effective and Efficient Online Action Detection by Consulting Exemplars(通过咨询示例进行有效且高效的在线动作检测)
paper:https://arxiv.org/pdf/2203.01057.pdf
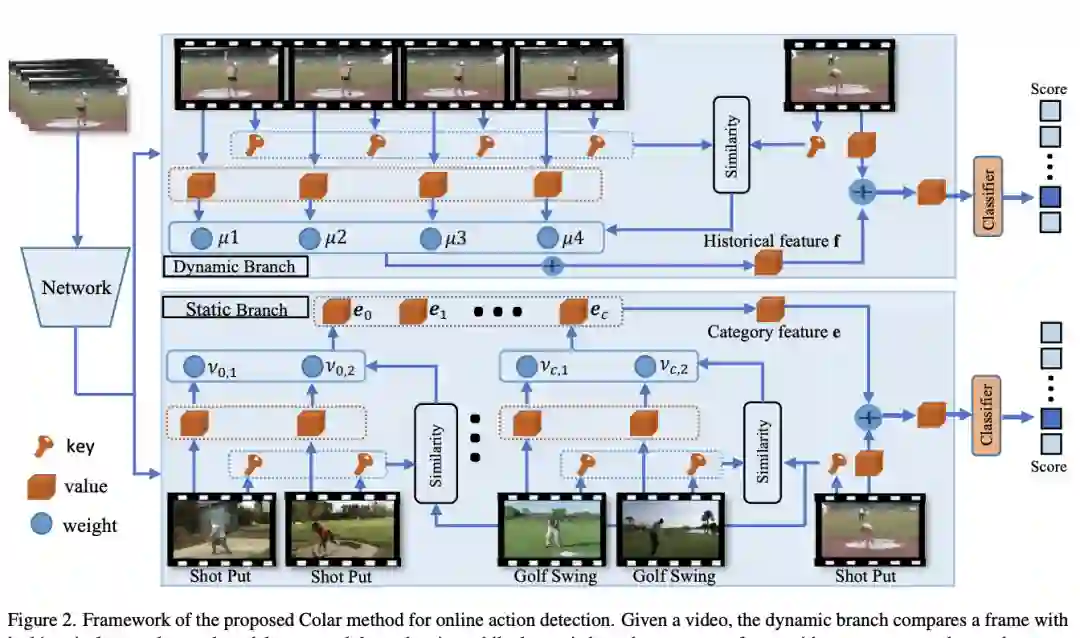
当前的工作模拟历史依赖关系并预测未来以感知视频片段中的动作演变并提高检测准确性。但是,现有的范式忽略了类别级别的建模,对效率没有给予足够的重视。本文开发了一种有效的示例咨询机制,该机制首先测量框架与示例框架之间的相似度,然后根据相似度权重聚合示例特征。这也是一种有效的机制,因为相似性测量和特征聚合都需要有限的计算。基于样例协商机制,可以将历史帧作为样例来捕捉长期依赖关系,将某个类别中的代表性帧作为样例来实现类别级建模。
人脸防伪
【1】 Protecting Celebrities with Identity Consistency Transformer(使用身份一致性transformer保护名人)
paper:https://arxiv.org/abs/2203.01318

这项工作提出了身份一致性转换器,这是一种新颖的人脸伪造检测方法,专注于高级语义,特别是身份信息,并通过发现内部和外部人脸区域的身份不一致来检测可疑人脸。身份一致性转换器包含用于身份一致性确定的一致性损失。本文表明,Identity Consistency Transformer 不仅在不同的数据集上表现出卓越的泛化能力,而且在包括 deepfake 视频在内的真实应用中发现的各种类型的图像退化形式上也表现出卓越的泛化能力。当此类信息可用时,身份一致性转换器可以很容易地通过附加身份信息进行增强,因此它特别适合检测涉及名人的面部伪造。
长尾识别
【1】 Targeted Supervised Contrastive Learning for Long-Tailed Recognition(用于长尾识别的有针对性的监督对比学习)
paper:https://arxiv.org/pdf/2111.13998.pdf
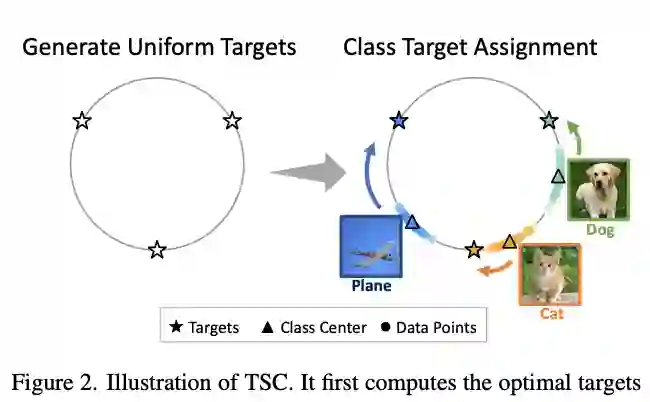
现实世界的数据通常表现出具有严重类不平衡的长尾分布,其中多数类可以主导训练过程并改变少数类的决策边界。最近,研究人员研究了监督对比学习在长尾识别方面的潜力,并证明它提供了强大的性能提升。本文表明,虽然有监督的对比学习可以帮助提高性能,但过去的基线受到数据分布不平衡带来的一致性差的影响。这种差的均匀性表现在来自少数类的样本在特征空间中的可分离性差。为了解决这个问题,本文提出了有针对性的监督对比学习(TSC),它提高了超球面上特征分布的均匀性。在多个数据集上的实验表明,TSC 在长尾识别任务上实现了最先进的性能。
公众号后台回复“数据集”获取60+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





