Tree-CNN:一招解决深度学习中的「灾难性遗忘」

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @Cratial。深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力。
为解决这一问题,本文提出了树卷积神经网络,通过先将物体分为几个大类,然后再将各个大类依次进行划分、识别,就像树一样不断地开枝散叶,最终叶节点得到的类别就是我们所要识别的类。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:吴仕超,东北大学硕士生,研究方向为脑机接口、驾驶疲劳检测和机器学习。
■ 论文 | Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
■ 链接 | https://www.paperweekly.site/papers/1839
■ 作者 | Deboleena Roy / Priyadarshini Panda / Kaushik Roy
网络结构及学习策略
网络结构
Tree-CNN 模型借鉴了层分类器,树卷积神经网络由节点构成,和数据结构中的树一样,每个节点都有自己的 ID、父亲(Parent)及孩子(Children),网(Net,处理图像的卷积神经网络),LT("Labels Transform",就是每个节点所对应的标签,对于根节点和枝节点来说,可以是对最终分类类别的一种划分,对于叶节点来说,就是最终的分类类别),其中最顶部为树的根节点。
本文提出的网络结构如下图所示。对于一张图像,首先会将其送到根节点网络去分类得到“super-classes”,然后根据所识别到的“super-classes”,将图像送入对应的节点做进一步分类,得到一个更“具体”的类别,依次进行递推,直到分类出我们想要的类。
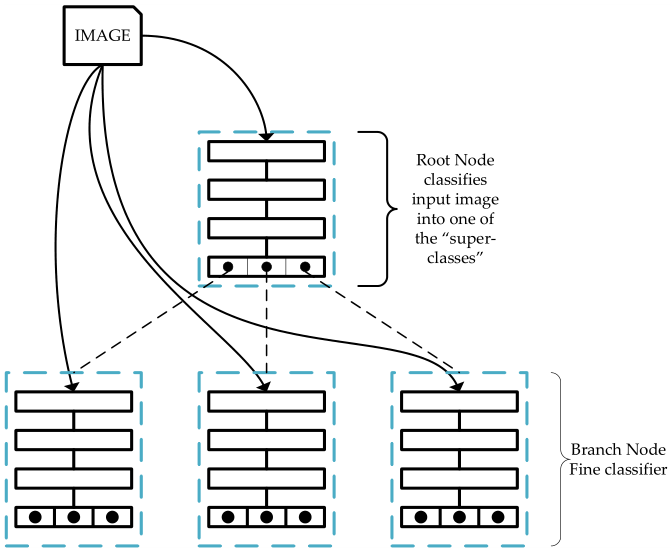
▲ 图1
其实这就和人的识别过程相似,例如有下面一堆物品:数学书、语文书、物理书、橡皮、铅笔。如果要识别物理书,我们可能要经历这样的过程,先在这一堆中找到书,然后可能还要在书里面找到理科类的书,然后再从理科类的书中找到物理书,同样我们要找铅笔的话,我们可能需要先找到文具类的物品,然后再从中找到铅笔。
学习策略
在识别方面,Tree-CNN 的思想很简单。如图 1 所示,主要就是从根节点出发,输出得到一个图像属于各个大类的概率,根据最大概率所对应的位置将识别过程转移到下一节点,这样最终我们能够到达叶节点,叶节点对应得到的就是我们要识别的结果。整个过程如图 2 所示。

▲ 图2
如果仅按照上面的思路去做识别,其实并没有太大的意义,不仅使识别变得很麻烦,而且在下面的实验中也证明了采用该方法所得到的识别率并不会有所提高。而这篇论文最主要的目的就是要解决我们在前面提到的“灾难性遗忘问题”,即文中所说的达到“lifelong”的效果。
对于新给的类别,我们将这些类的图像输入到根节点网络中,根节点的输出为 OK×M×I,其中 K、M、I 分别为根节点的孩子数、新类别数、每类的图像数。
然后利用式(1)来求得每类图像的输出平均值 Oavg,再使用 softmax 来计算概率情况。以概率分布表示该类与根节点下面子类的相似程度。对于第 m 类,我们按照其概率分布进行排列,得到公式(3)。
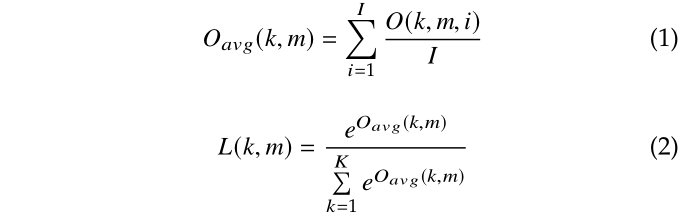
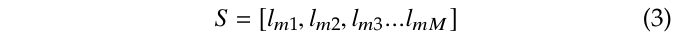
根据根节点得到的概率分布,文中分别对下面三种情况进行了讨论:
当输出概率中最大概率大于设定的阈值,则说明该类别和该位置对应的子节点有很大的关系,因此将该类别加到该子节点上;
若输出概率中有多个概率值大于设定的阈值,就联合多个子节点来共同组成新的子节点;
如果所有的输出概率值都小于阈值,那么就为新类别增加新的子节点,这个节点是一个叶节点。
同样,我们将会对别的支节点继续上面的操作。通过上面的这些操作,实现对新类别的学习,文中称这种学习方式为 incremental/lifelong learning。
实验方法与结果分析
在这部分,作者分别针对 CIFAR-10 及 CIFAT-100 数据集上进行了测试。
实验方法
1. CIFAR-10
在 CIFAR-10 的实验中,作者选取 6 类图像作为初始训练集,又将 6 类中的为汽车、卡车设定为交通工具类,将猫、狗、马设为动物类,因此构建出的初始树的结构如图 3(a)所示。
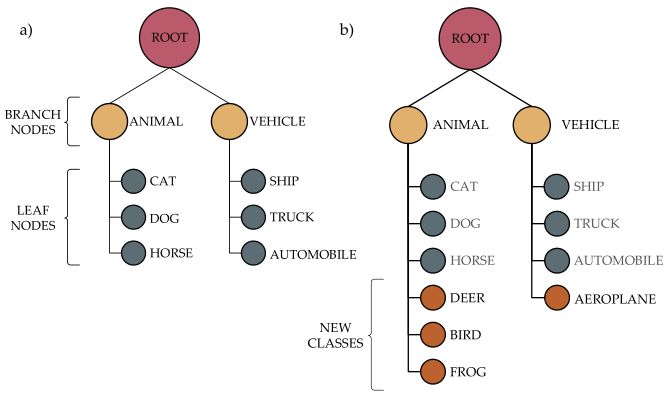
▲ 图3
具体网络结构如图 4 所示,根节点网络是包含两层卷积、两层池化的卷积神经网络,支节点是包含 3 层卷积的卷积神经网络。
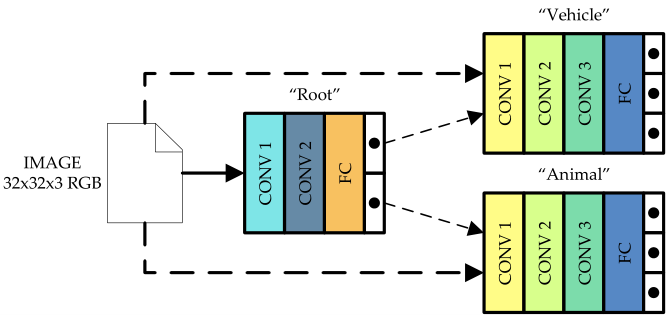
▲ 图4
当新的类别出现时(文中将 CIFAR-10 另外 4 个类别作为新类别),按照文中的学习策略,我们先利用根节点的网络对四种类别的图片进行分类,得到的输出情况如图 5 所示,从图中可以看出,在根节点的识别中 Frog、Deer、Bird 被分类为动物的概率很高,Airplane 被分类为交通工具的概率较高。

▲ 图5
根据文中的策略,Frog、Deer、Bird 将会被加入到动物类节点,同样 Airplane 将会被加入到交通工具类节点。经过 incremental/lifelong learning 后的 Tree-CNN 的结构如图 3(b)所示。 具体训练过程如图 6 所示。

▲ 图6
为了对比 Tree-CNN 的效果,作者又搭建了一个包含 4 层卷积的神经网络,并分别通过调节全连接层、全连接 +conv1、全连接 +conv1+conv2、全连接 +conv1+conv2+conv3、全连接 +conv1+conv2+conv3+conv4 的参数来进行微调。
2. CIFAR-100
对于 CIFAR-100 数据集,作者将 100 类数据分为 10 组,每组包含 10 类样本。在网络方面,作者将根节点网络的卷积层改为 3,并改变了全连接层的输出数目。
实验结果分析
在这部分,作者通过设置两个参数来衡量 Tree-CNN 的性能。
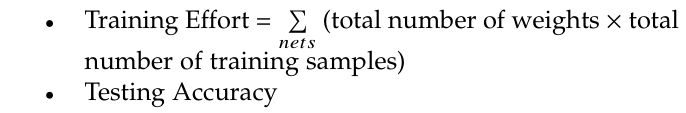
其中,Training Effort 表示 incremental learning 网络的更改程度,即可以衡量“灾难性遗忘”的程度,参数改变的程度越高,遗忘度越强。
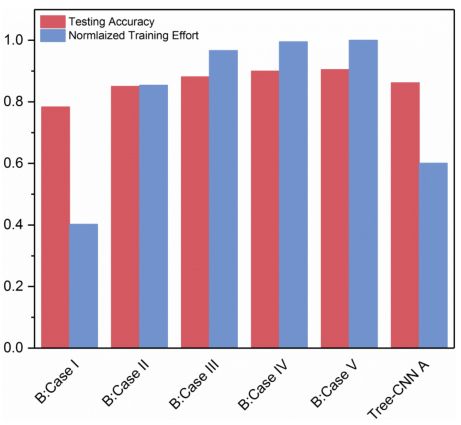
图 7 比较了在 CIFAR-10 上微调网络和 Tree-CNN 的识别效果对比,可以看出相对于微调策略,Tree-CNN 的 Training Effort 仅比微调全连接层高,而准确率却能超出微调全连接层 +conv1。
▲ 图7
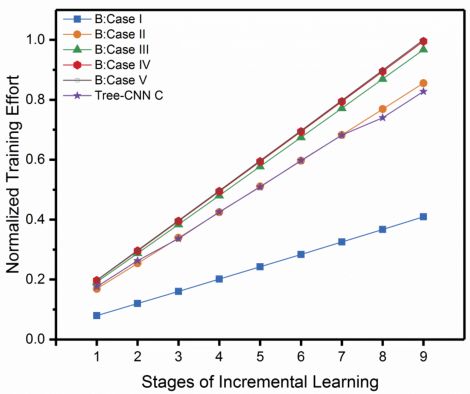
这一现象在 CIFAR-100 中表现更加明显。
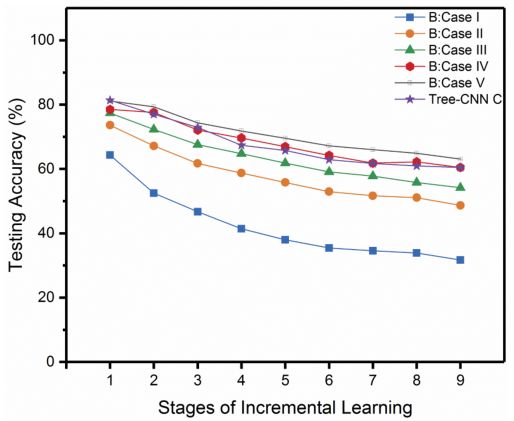
▲ 图8
从图 7、图 8 中可以看出 Tree-CNN 的准确率已经和微调整个网络相差无几,但是在 Training Effort 上却远小于微调整个网络。
从图 9 所示分类结果中可以看出,在各个枝节点中,具有相同的特性的类被分配在相同的枝节点中。这一情况在 CIFAR-100 所得到的 Tree-CNN 最终的结构中更能体现出来。

除了一些叶节点外,在语义上具有相同特征的物体会被分类到同一支节点下,如图 10 所示。
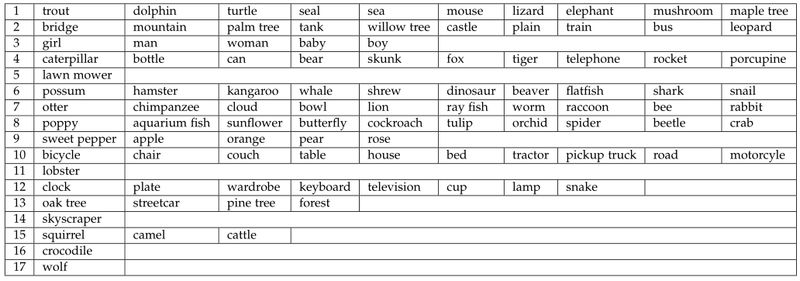
▲ 图10
总结与分析
本文虽然在一定程度上减少了神经网络“灾难性遗忘”问题,但是从整篇文章来看,本文并没能使网络的识别准确率得到提升,反而,相对于微调整个网络来说,准确率还有所降低。
此外,本文搭建的网络实在太多,虽然各个子网络的网络结构比较简单,但是调节网络会很费时。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

▲ 戳我查看招聘详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文

