PyTorch 深度学习新手入门指南
原标题 | Starter Pack for Deep Learning Projects in PyTorch — for Extreme Beginners — by a beginner!
作 者 | Nikhila Munipalli
翻 译 | 天字一号(郑州大学)、Ryan(西安理工大学)、申影(山东大学)、邺调(江苏科技大学)、Loing(华中科技大学)
审 校 | 唐里、鸢尾、skura
来 源 | AI开发者
让我们开始吧!
老生常谈的话题:
from keras.models import Sequential
from keras.layers import Dense, Dropout
import Andrew as ng !
开始设置

模块 1:网络类
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.linear = nn.linear(input dim, output dim)
def forward(self,x):
out = self.linear1(x)
out = self.linear2(out)
return out
模块 2:自定义数据加载器
class dataset(data.Dataset):
class dataset(data.Dataset):
def __init__(self, partition):
if partition==’train’:
self.sequences = X_train
self.labels = y_train
params= {‘batch_size’ : 10,
‘shuffle’ : True,
‘num_workers’ : 20}
training_set = dataset(X, y, ‘train )
training_generator = torch.utils.data.dataloader(training_set, **params)
模块 3:训练函数
net.train()
criterion = nn.MSELoss() optimizer = torch.optim.Adam(net.parameters(), lr=lr)
t = tqdm(iter(training_generator), leave=False, total=len(training_generator))
for i, batch in enumerate(t):
x_batch, y_batch = next(iter(training_generator))
torch.cuda.set_ device(0)
:
X= X.cuda()
output = net(x)
loss = criterion(output, targets)
loss.backward()
optimizer.step()
t.set_postfix(loss=train_loss)
net.eval()
torch.save(net, path) #saving
net = torch.load(path) #loading
torch.save(net.state_dict(), path) #saving
net = Network(*args, **kwargs) #loading
net.load_state_dict(torch.load(path))
第三个问题:
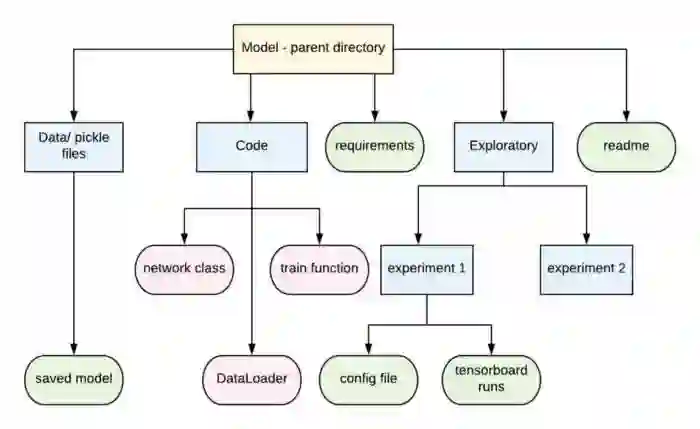
最后:组织
from config import *
writer = SummaryWriter(path)
writer.add_scalar(‘loss’, loss, epoch_number)
writer.add_scalar( accuracy , accuracy, epoch_number)
writer.close()

登录查看更多
相关内容

Arxiv
10+阅读 · 2018年12月4日
Arxiv
15+阅读 · 2018年10月11日




相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2018年12月4日
Arxiv
15+阅读 · 2018年10月11日