KDD 2019 | 不用反向传播就能训练DL模型,ADMM效果可超梯度下降
机器之心发布
随机梯度下降 (SGD) 是深度学习的标准算法,但是它存在着梯度消失和病态条件等问题。本文探索与反向传播(BP)完全不同的方向来优化深度学习模型,即非梯度优化算法,提出了「反向前向的交替方向乘子法」的深度模型优化算法,即 dlADMM。该方法解决了随机梯度下降存在的问题,在多个标准数据集上达到并超过梯度下降算法的效果,并且第一次给出了全局收敛的数学证明。同时增强了算法的可扩展性,为解决一些当前重要的瓶颈问题提供了全新视角,比如复杂不可导问题以及非常深的神经网络的高性能计算问题。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文地址:https://arxiv.org/pdf/1905.13611.pdf
代码地址:https://github.com/xianggebenben/dlADMM

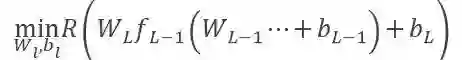
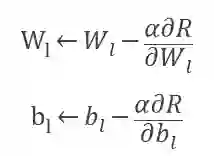
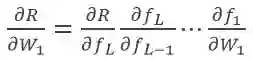 如果
如果
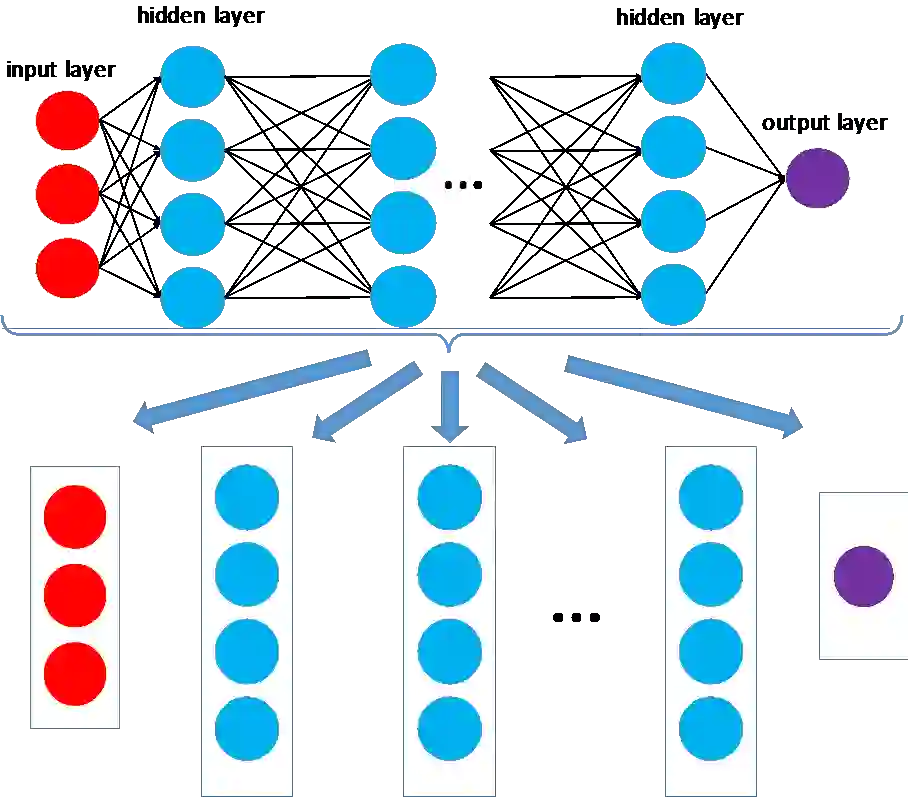
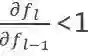 , 那么随着层数的增加,梯度信号发生衰减直至消失。连提出 BP 的 Geoffrey Hinton 都对它充满了质疑。主要是因为反向传播机制实在是不像大脑。Hinton 在 2017 年的时候提出胶囊理论尝试替代标准神经网络。但是只要反向传播的机制不改变,梯度消失的问题就不会解决。因此目前有许多研究者尝试采用各种机制训练神经网络,早在 2016 年,Gavin Taylor[1] 等人就提出了 ADMM 的替代想法,ADMM 的原理如图 1 所示,一个神经网络按照不同的层被分解成若干个子问题,每个子问题可以并行求解,这样不需要求复合目标函数 R(∙) 的导数,解决了梯度下降的问题。按照 ADMM 的思路,神经网络问题被等价转换为如下问题 1:
, 那么随着层数的增加,梯度信号发生衰减直至消失。连提出 BP 的 Geoffrey Hinton 都对它充满了质疑。主要是因为反向传播机制实在是不像大脑。Hinton 在 2017 年的时候提出胶囊理论尝试替代标准神经网络。但是只要反向传播的机制不改变,梯度消失的问题就不会解决。因此目前有许多研究者尝试采用各种机制训练神经网络,早在 2016 年,Gavin Taylor[1] 等人就提出了 ADMM 的替代想法,ADMM 的原理如图 1 所示,一个神经网络按照不同的层被分解成若干个子问题,每个子问题可以并行求解,这样不需要求复合目标函数 R(∙) 的导数,解决了梯度下降的问题。按照 ADMM 的思路,神经网络问题被等价转换为如下问题 1:
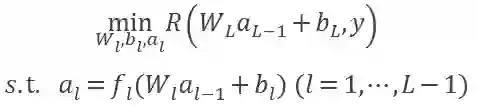
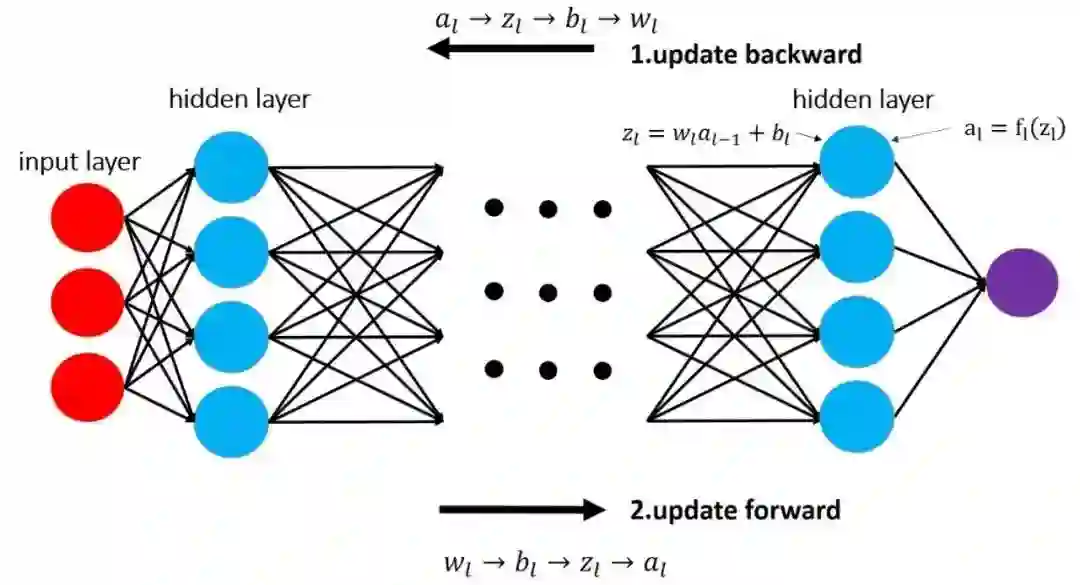
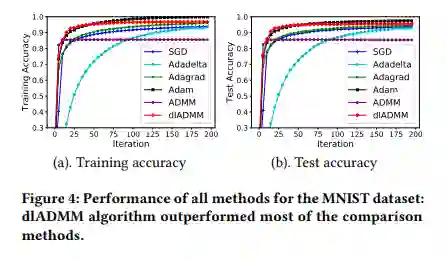
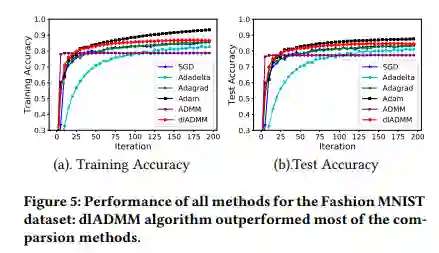
加快收敛。文章提出了一种新的迭代方式加强了训练参数的信息交换,从而加快了 dlADMM 的收敛过程。
加快运行速度。作者通过二次近似的技术避免了求解逆矩阵,把时间复杂度从 O(n^3 ) 降低到 O(n^2 ),即与梯度下降相同的复杂度。从而大幅提高 ADMM 的运行速度。
具备收敛保证。本文第一次证明了 dlADMM 可以全局收敛到问题的一个驻点(该点导数为 0)。
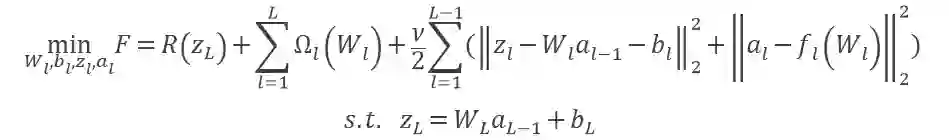
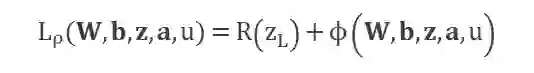
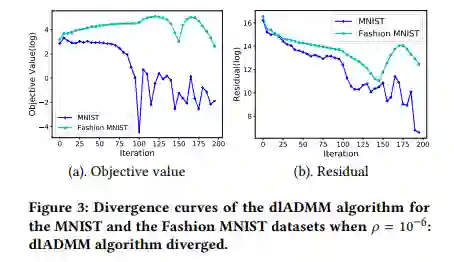
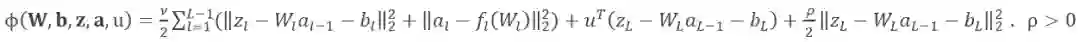 是 dlADMM 中的一个超参数。
是 dlADMM 中的一个超参数。
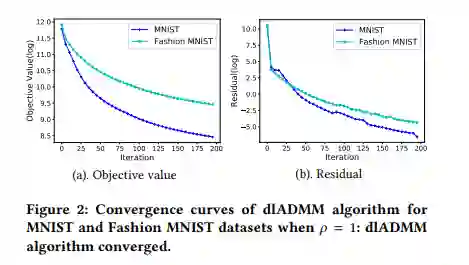
是有界的,L_ρ是有下界的。
L_ρ是单调下降的。
L_ρ的次梯度趋向于 0。
登录查看更多
相关内容

Arxiv
11+阅读 · 2018年7月12日




相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2018年7月12日