比xgboost强大的LightGBM:调参指南(带贝叶斯优化代码)

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM、SVM、LASSO........。现在,微软推出了一个新的boosting框架,想要挑战xgboost的江湖地位。笔者尝试了一下,下面请看来自第一线的报告。
包含以下几个部分:
一. 基本介绍
二. XGBOOST原理及缺点
三. LightGBM的优化
一. 基本介绍
LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的,它有以下优势:
- 更快的训练效率
- 低内存使用
- 更好的准确率
- 支持并行学习
- 可处理大规模数据
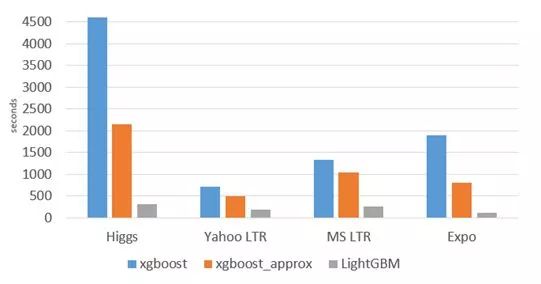
与常用的机器学习算法进行比较:
· 速度飞起
二. XGBOOST原理及缺点
1. 原理
1 ) 有监督学习
有监督学习的目标函数是下面这个东东:
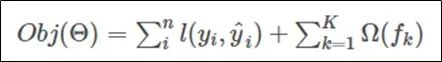
其中,第一项称为误差函数,常见的误差函数有平方误差,logistic误差等等,第二项称为正则项,常见的有L1正则和L2正则,神经网络里面的dropout等等
2)Boosted Tree
i)基学习器:分类树和回归树(CART)
ii ) Tree Ensemble
一个CART往往过于简单无法有效地预测,因此一个更加强力的模型叫做tree ensemble。
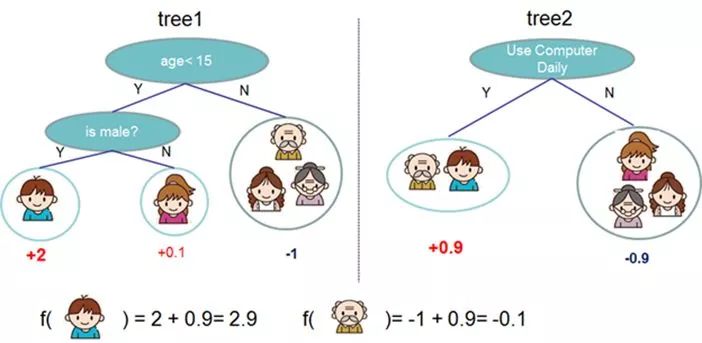
简而言之,Boosted Tree 就是一种 Tree Ensemble的方法,和RF一样,只是构造(学习)模型参数的方法不同。
iii)模型学习:additive training
每一次保留原来的模型不变,加入一个新的函数f到我们的模型中。

f 的选择标准---最小化目标函数!
通过二阶泰勒展开,以及(中间省略N步),我们得到了最终的目标函数:
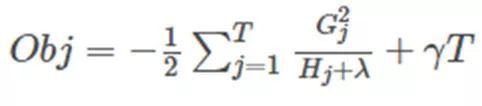
G、H:与数据点在误差函数上的一阶、二阶导数有关,T:叶子的个数
iv ) 枚举所有不同树结构的贪心算法
不断地枚举不同树的结构,根据目标函数来寻找出一个最优结构的树,加入到我们的模型中,再重复这样的操作。不过枚举所有树结构这个操作不太可行,所以常用的方法是贪心法,每一次尝试去对已有的叶子加入一个分割。对于一个具体的分割方案,我们可以获得的增益可以由如下公式计算。

对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有 x<a 这样的条件,对于某个特定的分割a我们要计算a左边和右边的导数和。

我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL和GR。然后用上面的公式计算每个分割方案的分数就可以了。
2. 缺点
-- 在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
-- 预排序方法(pre-sorted):
首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
三. LightGBM的优化
基于Histogram的决策树算法
带深度限制的Leaf-wise的叶子生长策略
直方图做差加速
直接支持类别特征(Categorical Feature)
Cache命中率优化
基于直方图的稀疏特征优化
多线程优化
下面主要介绍Histogram算法、带深度限制的Leaf-wise的叶子生长策略。
>>>>
Histogram算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
图:直方图算法
>>>>
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
细节大家直接看作者的解释以及GitHub上的介绍吧,还是挺好理解的~
链接:
https://www.zhihu.com/question/51644470/answer/130946285
https://github.com/Microsoft/LightGBM/wiki/Features
接下来将介绍官方LightGBM调参指南,最后附带小编良心奉上的贝叶斯优化代码供大家试用。
与大多数使用depth-wise tree算法的GBM工具不同,由于LightGBM使用leaf-wise tree算法,因此在迭代过程中能更快地收敛;但leaf-wise tree算法较容易过拟合;为了更好地避免过拟合,请重点留意以下参数:
1. num_leaves. 这是控制树模型复杂性的重要参数。理论上,我们可以通过设定num_leaves = 2^(max_depth) 去转变成为depth-wise tree。但这样容易过拟合,因为当这两个参数相等时, leaf-wise tree的深度要远超depth-wise tree。因此在调参时,往往会把 num_leaves的值设置得小于2^(max_depth)。例如当max_depth=6时depth-wise tree可以有个好的准确率,但如果把 num_leaves 设成 127 会导致过拟合,要是把这个参数设置成 70或 80 却有可能获得比depth-wise tree有更好的准确率。事实上,当我们用 leaf-wise tree时,我们可以忽略depth这个概念,毕竟leaves跟depth之间没有一个确切的关系。
2. min_data_in_leaf. 这是另一个避免leaf-wise tree算法过拟合的重要参数。该值受到训练集数量和num_leaves这两个值的影响。把该参数设的更大能够避免生长出过深的树,但也要避免欠拟合。在分析大型数据集时,该值区间在数百到数千之间较为合适。
3. max_depth. 也可以通过设定 max_depth 的值来限制树算法生长过深。
提高速度的参数
· 通过设定bagging_fraction和bagging_freq来使用 bagging算法
· 通过设定 feature_fraction来对特征采样
· 设定更小的max_bin值
· 使用save_binary 以方便往后加载数据的速度
· 设定平行计算参数
提高精度的参数
· 设定更大的max_bin值(但会拖慢速度)
· 设定较小的learning_rate值,较大的num_iterations值
· 设定更大的num_leaves值(但容易导致过拟合)
· 加大训练集数量(更多样本,更多特征)
· 试试boosting= dart
避免过拟合的参数
· 设定较小的max_bin
· 设定更小的num_leaves
· 设定min_data_in_leaf和min_sum_hessian_in_leaf
· 通过设定bagging_fraction和bagging_freq来使用 bagging算法
· 通过设定feature_fraction来对特征采样。
· 加大训练集数量(更多样本,更多特征)
· 通过设定lambda_l1, lambda_l2以及min_gain_to_split来采取正则化措施
· 通过设定max_depth以避免过拟合
贝叶斯优化LightGBM超参数的代码
此处借用rBayesianOptimization包完成贝叶斯超参数搜索任务:
#加载lgb以及贝叶斯优化所需包
library(lightgbm)
library(rBayesianOptimization)
#载入样例数据集
data(agaricus.train, package = "lightgbm")
dtrain <- lgb.Dataset(agaricus.train$data,
label = agaricus.train$label)
#定义k折交叉检验的k值
cv_folds <- KFold(agaricus.train$label, nfolds = 5,
stratified = TRUE, seed = 0)
#定义lgb调参函数
lgb_cv_bayes <- function(num_leaves, learning_rate) {
cv <- lgb.cv(params = list(num_leaves = num_leaves,
learning_rate = learning_rate),
device = 'cpu',
objective = "regression",
metric = "l2",
data = dtrain,
nrounds = 100,
folds = cv_folds,
early_stopping_rounds = 5,
verbose = 0)
list(Score = min(unlist(cv$record_evals$valid$l2$eval)))
}
#实施贝叶斯优化调参
OPT_Res <- BayesianOptimization(lgb_cv_bayes,
bounds = list(learning_rate =
c(0, 1),
num_leaves = c(20L, 40L)),
init_grid_dt = NULL,
init_points = 10,
n_iter = 20,
acq = "ucb",
kappa = 2.576,
eps = 0.0,
verbose = TRUE)上面的代码仅作参考,实际中请根据自身对参数及实际数据的理解再作修改。
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注



