LibRec 每周算法:DeepFM
本周介绍一篇来自与哈工大与华为诺亚方舟实验室的论文。 本文提出的DeepFM模型有效的结合了神经网络与因子分解机在特征学习中的优点。DeepFM可以同时提取到低阶组合特征与高阶组合特征,并除了得到原始特征之外无需其他特征工程。实验表明DeepFM比其他用于CTR的模型更加有效和高效。
Guo et al., DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, arXiv:1703.04247v1 [cs.IR] 13 Mar 2017
动机
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。而根据google提出的Wide&Deep model表示,同时考虑到低阶特征与高阶特征会比单独考虑其中一个有额外的提升。
目前最大的挑战是有效的提取到特征组合。有些组合很好被理解,但是有些特征组合很难找到对应的先验知识。而且即使特征组合有明确的语义,当特征数目比较大的时候也几乎不可行。
目前常用的CTR预估模型分别存在这些问题。
在使用线性模型中,提取高阶特征的普遍方式其实是基于手工和先验知识。一方面当特征维度比较高时几乎不可行。另外一方面,这些模型也很难对在训练集中很少出现的组合特征进行建模。
因子分解机(Factorization Machines, FM)通过对于每一维特征的隐变量内积来提取特征组合。最终的结果也非常好。但是,理论上来讲FM可以对高阶特征组合进行建模,实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
深度神经网络在学习复杂的特征关系中非常有潜力。目前也有很多基于CNN与RNN的用于CTR预估的模型。但是基于CNN的模型比较偏向于相邻的特征提取,基于RNN的模型更适合有序列依赖的点击数据。
zhang et al. 提出的FNN(Factorization-machine supported Neural Network)模型首先预训练FM,再将训练好的FM应用到DNN中。Qu et al. 在PNN网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。PNN和FNN与其他深度学习模型相似,很难有效的提取出低阶特征。
wide&deep模型混合了宽度(wide)模型与深度模型。但是宽度模型的输入依旧依赖于特征工程。
因此,现在的模型要不然偏向于低阶特征或者高阶特征的提取,要不然依赖于特征工程。而本文提出了DeepFM模型可以以端对端的方式来学习不同阶组合特征的模型,并且不需要其他特征工程。本文主要贡献点如下:
本文提出了全新的神经网络模型,命名为DeepFM。DeepFM的结构中包含了因子分解机部分以及深度神经网络部分,分别负责低阶特征的提取和高阶特征的提取。与Wide&Deep Model不同,DeepFM在训练过程中不需要特征工程。
DeepFM的训练更高效。与Wide&Deep Model不同,DeepFM共享相同的输入与embedding向量。在Wide&Deep Model中,因为在Wide部分包含了人工设计的成对特征组,所以输入向量的长度也会显著增加。这也增加了其复杂性。
在不同的数据集上对DeepFM进行了验证。最终结果显示,与用于CTR预估的已有模型相比,deepFM模型均有提升。
模型
首先给出DeepFM的模型:
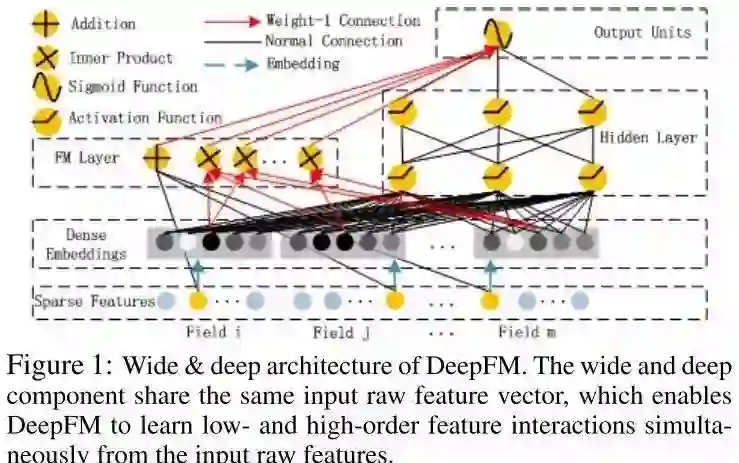
DeepFM模型的数据集的输入数据χ包含m个域的数据。χ包含连续数据与离散数据。离散数据一般进行one-hot编码,连续数据使用本身的数值或者离散之后的one-hot编码。对应的标签取值为0或者1, 其中0表示没有点击,1表示点击。这样一个实例中x就可以表示为d维的长向量[x_field1,x_field2,…,x_fieldj,…,x_fieldm]。一般来说,输入数据x是一个高维稀疏向量。而点击率预估任务则是构建一个预测模型 \hat{y}=CTR_model(x),从而估计在给定的情景下用户点击一个特定app的概率。
DeepFM
DeepFM包含两部分:神经网络部分与因子分解机部分。这两部分共享同样的输入。对于给定特征ii,向量wiwi用于表征一阶特征的重要性,隐变量ViVi用于表示与其他特征的相互影响。在FM部分,ViVi用于表征二阶特征,同时在神经网络部分用于构建高阶特征。对于当前模型,所有的参数共同参与训练。DeepFM的预测结果可以写为
\hat{y}=sigmoid(yFM+yDNN)
其中y∈(0,1)是预测的点击率,yFM与yDNN分别是FM部分与DNN部分。
FM部分的详细结构如下:
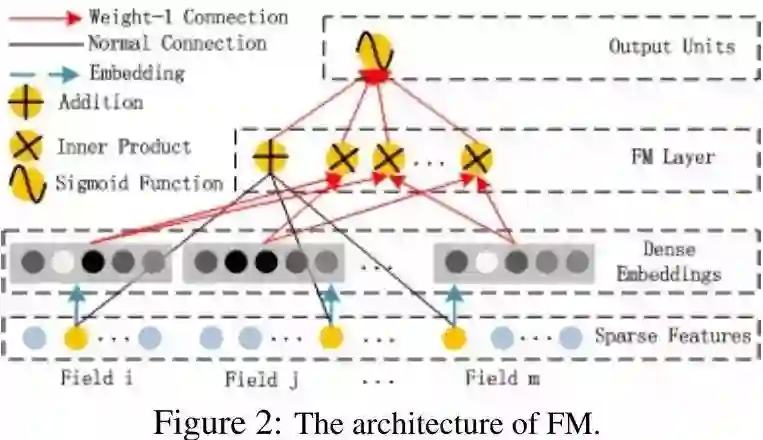
FM部分是一个因子分解机。关于因子分解机可以参阅文章[Rendle, 2010] Steffen Rendle. Factorization machines. In ICDM, 2010.。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。
如图二所示,FM的输出如下公式:
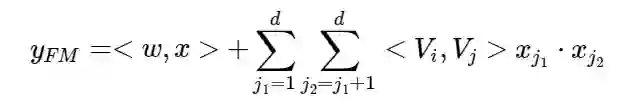
其中w∈R^d,V_i∈R^k. 加法部分<w,x>反映了一阶特征,而内积部分反应了二阶特征。
深度部分详细如下:
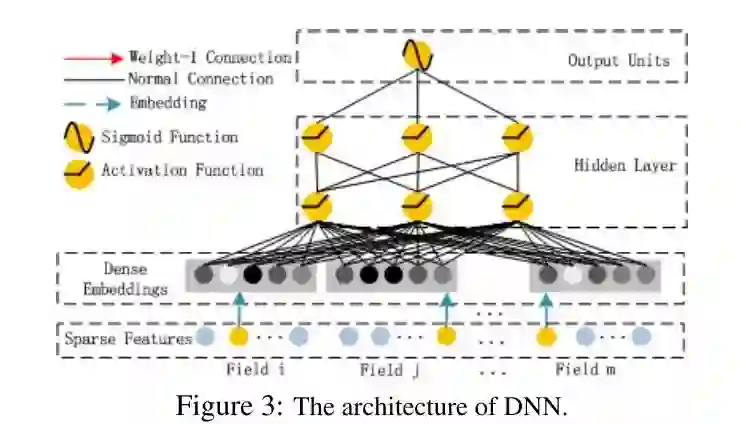
深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。
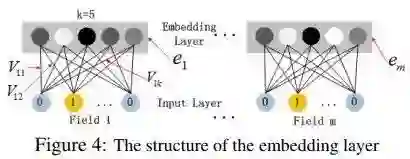
嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性,1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为 (k)。2)在FM里得到的隐变量VV现在作为了嵌入层网络的权重。在文献Weinan Zhang, Tianming Du, and Jun Wang. Deep learning over multi-field categorical data - - A case study on user response prediction. In ECIR, 2016.中,V是通过FM来预训练,但是本文中,FM模型作为整个模型的一部分与其他深度学习模型一起参与整体的学习。此时,整个模型可以通过end-to-end的方式来完成训练。嵌入层的表示如下:
a_0=[e_1,e_2,⋯,e_m]
其中e_i表示嵌入层的第i个field,m为#field。a_0为输入深度神经网络的向量,前馈过程可以表示为
a_{l+1}=σ(W^(l) a^(l) + b^(l))
需要指出的是,FM部分与深度部分共享相同的embedding带来了两个好处:
从原始数据中同时学习到了低维与高维特征。
不再需要特征工程。而Wide&Deep Model需要。
与其他模型的联系
该部分主要讨论了本文提出的DeepFM模型与已经存在的深度学习模型之间的差异。不同模型的结构如下图所示:
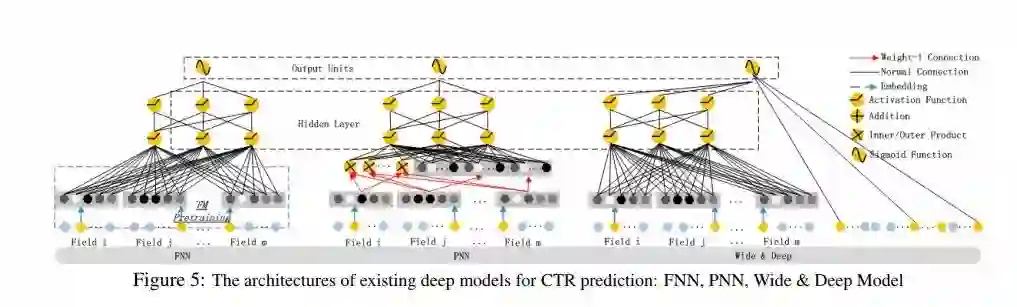
FNN:[Zhang et al., 2016] Weinan Zhang, Tianming Du, and Jun Wang. Deep learning over multi-field categorical data - - A case study on user response prediction. In ECIR, 2016. 本模型中FM需要预训练。而此带来了这两点局限:1)FM可能过于影响到嵌入层的参数。2)预训练也降低了效率。另外,FNN只能捕捉到高维特征。
PNN:为了捕捉到高阶特征,PNN在嵌入层与隐含层第一层之间引入了product layer。而根据不同的乘积方式,PNN有三种变种:IPNN,OPNN,PNN*,分别对应內积,外积,內积与外积。在具体使用中,因为外积的近似计算损失了大量的信息,使得外积的结果不如內积可靠。然而尽管如此,考虑到product layer的输出与第一层隐含层的连接为全连接,內积计算的计算复杂度比较高。不同于PNN,DeepFM的procdutlayer只和最终的输出连接,也就是一个神经元。与FNN相似,不同类型的PNN都忽略了低阶特征。
Wide&Deep: Wide&Deep Model是google提出的可以同时提取低阶和高阶组合特征的模型。wide部分的输入需要进行特征工程。相应的,DeepFM可以直接处理原始输入特征而不需要特征工程。
不同模型之间的关系如下表

另外一个非常直观的扩展是将此模型中的FM部分使用LR来代替。在DeepFM中,FM部分与深度部分的feature embedding是共享的。而这种共享的策略又进一步通过反向传播的方式影响了低阶与高阶的特征组合,从而构建出更具有表征能力的特征。
实验
在Kaggle比赛中使用的公开数据集Criteo Dataset与私有数据集中对LR,FM,FNN,PNN,Wide&Deep,与DeepFM模型进行对比实验。在性能评估中,在GPU与CPU两种计算模式下,DeepFM几乎均为最有效的模型。在有效性评估中,AUC与LogLoss两种评价指标下,DeepFM均达到了最优的结果。
相关阅读
LibRec 每周算法:Wide & Deep (by Google)


