代码+实战:TensorFlow Estimator of Deep CTR —— DeepFM/NFM/AFM/FNN/PNN

AI 研习社按,本文作者 lambdaJi,本文首发于知乎,AI 研习社获其授权转载。
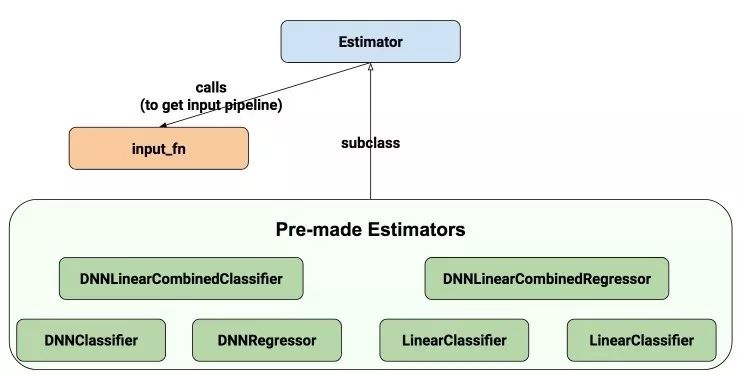
深度学习在 ctr 预估领域的应用越来越多,新的模型不断冒出。从 ctr 预估问题看看 f(x) 设计—DNN 篇(https://zhuanlan.zhihu.com/p/28202287)整理了各模型之间的联系之后,一直在琢磨这些东西如何在工业界落地。经过几个月的调研,发现目前存在的一些问题:
开源的实现基本都是学术界的人在搞,距离工业应用还有较大的鸿沟
模型实现大量调用底层 API,各版本实现千差万别,代码臃肿难懂,迁移成本较高
单机,放到工业场景下跑不动
针对存在的问题做了一些探索,摸索出一套可行方案,有以下特性:
读数据采用 Dataset API,支持 parallel and prefetch 读取
通过 Estimator model_fn 来实现 f(x),迁移到其他算法非常方便,只需要改写 model_fn f(x) 部分
支持分布式以及单机多线程训练
支持 export model,然后用 TensorFlow Serving 提供线上预测服务
按工业界的套路,完整的机器学习项目应该包含五个部分:特征框架,训练框架,服务框架,评估框架和监控框架,这里只讨论前三个框架。
特征框架 -- logs in,samples out
实验数据集用 criteo,特征工程参考: https://github.com/PaddlePaddle/models/blob/develop/deep_fm/preprocess.py
#1 连续特征 剔除异常值/归一化
#2 离散特征 剔掉低频,然后统一编码(特征编码需要保存下来,线上预测的时候要用到)
对大规模离散特征建模是用 DNN 做 ctr 预估的优势,paper 关注点大都放在 ID 类特征如何做 embedding 上,至于连续特征如何处理很少讨论,大概有以下 3 种方式:
--不做 embedding
|1--concat[continuous, emb_vec] 做 fc
--做 embedding
|2--离散化之后 embedding
|3--类似 FM 二阶部分, 统一做 embedding,离散特征 val=1.0
为了模型设计上的简单统一,采用第 3 种方式,感兴趣的读者可是试试前两种的效果。
训练框架 -- samples in,model out
目前实现了 DeepFM/wide_n_deep/NFM/AFM/FNN/PNN 几个算法。以 DeepFM 为例来看看如何使用 TensorFlow Estimator and Datasets API 来实现 input_fn and model_fn:
#1 1:0.5 2:0.03519 3:1 4:0.02567 7:0.03708 8:0.01705 9:0.06296 10:0.18185 11:0.02497 12:1 14:0.02565 15:0.03267 17:0.0247 18:0.03158 20:1 22:1 23:0.13169 24:0.02933 27:0.18159 31:0.0177 34:0.02888 38:1 51:1 63:1 132:1 164:1 236:1def input_fn(filenames, batch_size=32, num_epochs=1, perform_shuffle=False):
print('Parsing', filenames)
def decode_libsvm(line):
columns = tf.string_split([line], ' ')
labels = tf.string_to_number(columns.values[0], out_type=tf.float32)
splits = tf.string_split(columns.values[1:], ':')
id_vals = tf.reshape(splits.values,splits.dense_shape)
feat_ids, feat_vals = tf.split(id_vals,num_or_size_splits=2,axis=1)
feat_ids = tf.string_to_number(feat_ids, out_type=tf.int32)
feat_vals = tf.string_to_number(feat_vals, out_type=tf.float32)
return {"feat_ids": feat_ids, "feat_vals": feat_vals}, labels
# Extract lines from input files using the Dataset API, can pass one filename or filename list
dataset = tf.data.TextLineDataset(filenames).map(decode_libsvm, num_parallel_calls=10).prefetch(500000) # multi-thread pre-process then prefetch
# Randomizes input using a window of 256 elements (read into memory)
if perform_shuffle:
dataset = dataset.shuffle(buffer_size=256)
# epochs from blending together.
dataset = dataset.repeat(num_epochs)
dataset = dataset.batch(batch_size) # Batch size to use
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
def model_fn(features, labels, mode, params):
"""Bulid Model function f(x) for Estimator."""
#------hyperparameters----
field_size = params["field_size"]
feature_size = params["feature_size"]
embedding_size = params["embedding_size"]
l2_reg = params["l2_reg"]
learning_rate = params["learning_rate"]
layers = map(int, params["deep_layers"].split(','))
dropout = map(float, params["dropout"].split(','))
#------bulid weights------
FM_B = tf.get_variable(name='fm_bias', shape=[1], initializer=tf.constant_initializer(0.0))
FM_W = tf.get_variable(name='fm_w', shape=[feature_size], initializer=tf.glorot_normal_initializer())
FM_V = tf.get_variable(name='fm_v', shape=[feature_size, embedding_size], initializer=tf.glorot_normal_initializer())
#------build feaure-------
feat_ids = features['feat_ids']
feat_ids = tf.reshape(feat_ids,shape=[-1,field_size])
feat_vals = features['feat_vals']
feat_vals = tf.reshape(feat_vals,shape=[-1,field_size])
#------build f(x)------
with tf.variable_scope("First-order"):
feat_wgts = tf.nn.embedding_lookup(FM_W, feat_ids) # None * F * 1
y_w = tf.reduce_sum(tf.multiply(feat_wgts, feat_vals),1)
with tf.variable_scope("Second-order"):
embeddings = tf.nn.embedding_lookup(FM_V, feat_ids) # None * F * K
feat_vals = tf.reshape(feat_vals, shape=[-1, field_size, 1])
embeddings = tf.multiply(embeddings, feat_vals) #vij*xi
sum_square = tf.square(tf.reduce_sum(embeddings,1))
square_sum = tf.reduce_sum(tf.square(embeddings),1)
y_v = 0.5*tf.reduce_sum(tf.subtract(sum_square, square_sum),1) # None * 1
with tf.variable_scope("Deep-part"):
if FLAGS.batch_norm:
if mode == tf.estimator.ModeKeys.TRAIN:
train_phase = True
else:
train_phase = False
deep_inputs = tf.reshape(embeddings,shape=[-1,field_size*embedding_size]) # None * (F*K)
for i in range(len(layers)):
#if FLAGS.batch_norm:
# deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i)
#normalizer_params.update({'scope': 'bn_%d' %i})
deep_inputs = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=layers[i], \ #normalizer_fn=normalizer_fn, normalizer_params=normalizer_params, \
weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='mlp%d' % i)
if FLAGS.batch_norm:
deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i) #放在RELU之后 https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md#bn----before-or-after-relu
if mode == tf.estimator.ModeKeys.TRAIN:
deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[i]) #Apply Dropout after all BN layers and set dropout=0.8(drop_ratio=0.2)
#deep_inputs = tf.layers.dropout(inputs=deep_inputs, rate=dropout[i], training=mode == tf.estimator.ModeKeys.TRAIN)
y_deep = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=1, activation_fn=tf.identity, \ weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='deep_out')
y_d = tf.reshape(y_deep,shape=[-1])
with tf.variable_scope("DeepFM-out"):
#y_bias = FM_B * tf.ones_like(labels, dtype=tf.float32) # None * 1 warning;这里不能用label,否则调用predict/export函数会出错,train/evaluate正常;初步判断estimator做了优化,用不到label时不传
y_bias = FM_B * tf.ones_like(y_d, dtype=tf.float32) # None * 1
y = y_bias + y_w + y_v + y_d
pred = tf.sigmoid(y)
predictions={"prob": pred}
export_outputs = {tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: tf.estimator.export.PredictOutput(predictions)}
# Provide an estimator spec for `ModeKeys.PREDICT`
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions,export_outputs=export_outputs)
#------bulid loss------
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=labels)) + \ l2_reg * tf.nn.l2_loss(FM_W) + l2_reg * tf.nn.l2_loss(FM_V)
# Provide an estimator spec for `ModeKeys.EVAL`
eval_metric_ops = {
"auc": tf.metrics.auc(labels, pred)
}
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions,loss=loss,eval_metric_ops=eval_metric_ops)
#------bulid optimizer------
if FLAGS.optimizer == 'Adam':
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8)
elif FLAGS.optimizer == 'Adagrad':
optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate, initial_accumulator_value=1e-8)
elif FLAGS.optimizer == 'Momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.95)
elif FLAGS.optimizer == 'ftrl':
optimizer = tf.train.FtrlOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
# Provide an estimator spec for `ModeKeys.TRAIN` modes
if mode == tf.estimator.ModeKeys.TRAIN:
return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions,loss=loss,train_op=train_op)
封装成 estimator 之后,调用非常简单
#train
python DeepFM.py --task_type=train --learning_rate=0.0005 --optimizer=Adam --num_epochs=1 --batch_size=256 --field_size=39 --feature_size=117581 --deep_layers=400,400,400 --dropout=0.5,0.5,0.5 --log_steps=1000 --num_threads=8 --model_dir=./model_ckpt/criteo/DeepFM/ --data_dir=../../data/criteo/
#predict
python DeepFM.py --task_type=infer --learning_rate=0.0005 --optimizer=Adam --num_epochs=1 --batch_size=256 --field_size=39 --feature_size=117581 --deep_layers=400,400,400 --dropout=0.5,0.5,0.5 --log_steps=1000 --num_threads=8 --model_dir=./model_ckpt/criteo/DeepFM/ --data_dir=../../data/criteo/
完整代码: lambdaji/tf_repos
https://github.com/lambdaji/tf_repos/tree/master/deep_ctr/Model_pipeline
服务框架 -- request in,pctr out
TensorFlow Serving 是一个用于机器学习模型 serving 的高性能开源库。它可以将训练好的机器学习模型部署到线上,使用 gRPC 作为接口接受外部调用。更加让人眼前一亮的是,它支持模型热更新与自动模型版本管理。这意味着一旦部署 TensorFlow Serving 后,你再也不需要为线上服务操心,只需要关心你的线下模型训练。
首先要导出 TF-Serving 能识别的模型文件
python DeepFM.py --task_type=export --learning_rate=0.0005 --optimizer=Adam --batch_size=256 --field_size=39 --feature_size=117581 --deep_layers=400,400,400 --dropout=0.5,0.5,0.5 --log_steps=1000 --num_threads=8 --model_dir=./model_ckpt/criteo/DeepFM/ --servable_model_dir=./servable_model/
默认以时间戳来管理版本,生成文件如下:
$ ls -lh servable_model/1517971230
|--saved_model.pb
|--variables
|--variables.data-00000-of-00001
|--variables.index
然后写一个client发送请求,这里用C++来写
PredictRequest predictRequest;
PredictResponse response;
ClientContext context;
predictRequest.mutable_model_spec()->set_name(model_name);
predictRequest.mutable_model_spec()->set_signature_name(model_signature_name); //serving_default
google::protobuf::Map<tensorflow::string, tensorflow::TensorProto>& inputs = *predictRequest.mutable_inputs();
//feature to tfrequest
std::vector<long> ids_vec = {1,2,3,4,5,6,7,8,9,10,11,12,13,15,555,1078,17797,26190,26341,28570,35361,35613,35984,48424,51364,64053,65964,66206,71628,84088,84119,86889,88280,88283,100288,100300,102447,109932,111823};
std::vector<float> vals_vec = {0.05,0.006633,0.05,0,0.021594,0.008,0.15,0.04,0.362,0.1,0.2,0,0.04,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1};
tensorflow::TensorProto feat_ids;
for (uint32_t i = 0; i < ids_vec.size(); i++) {
feat_ids.add_int64_val(ids_vec[i]);
}
feat_ids.mutable_tensor_shape()->add_dim()->set_size(1); //batch_size
feat_ids.mutable_tensor_shape()->add_dim()->set_size(feat_ids.int64_val_size());
feat_ids.set_dtype(tensorflow::DataType::DT_INT64);
inputs["feat_ids"] = feat_ids;
tensorflow::TensorProto feat_vals;
for (uint32_t i = 0; i < vals_vec.size(); i++) {
feat_vals.add_float_val(vals_vec[i]);
}
feat_vals.mutable_tensor_shape()->add_dim()->set_size(1); //batch_size
feat_vals.mutable_tensor_shape()->add_dim()->set_size(feat_vals.float_val_size()); //sample size
feat_vals.set_dtype(tensorflow::DataType::DT_FLOAT);
inputs["feat_vals"] = feat_vals;
Status status = _stub->Predict(&context, predictRequest, &response);
完整代码: lambdaji/tf_repos
https://github.com/lambdaji/tf_repos/tree/master/deep_ctr/Serving_pipeline
生产环境对时耗和性能的要求较高,而 DNN 的计算量比 LR 的简单查表操作大得多,往往需要在效果和性能之间做折中. 这个环节比较考验工程能力, 下图是 wide_n_deep model 放到线上环境的真实数据,可以看到:
截距部分15ms:对应解析请求包,查询redis/tair,转换特征格式以及打log等
斜率部分0.5ms:一条样本forward一次需要的时间
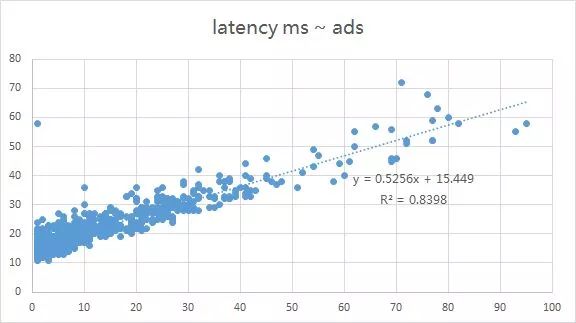
一个比较有意思的现象是:随着进一步放量,平均时耗不升反降,怀疑 TF-Serving 内部做了 cache 类的优化。
Model Performance
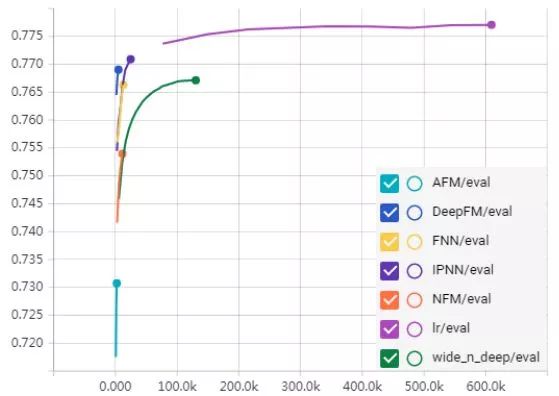
本来打算调好参再放出来,但是自从把机器跑挂三次就放弃了:(
图上跑出来的效果不好,可能有几个原因:
--特征工程没做好(连续特征不适合做embedding,负采样,shuffle等等)
--模型设计有问题(不确定有没有bug)
--调参,模型没有收敛到一个足够好的解
感兴趣的小伙伴可以fork下来折腾折腾,做人肉层面的并行,比一个人闭门搞快得多。
项目地址:https://github.com/lambdaji/tf_repos
最后提前祝大家新年炼丹愉快!
参考资料:
https://github.com/wnzhang/deep-ctr
https://github.com/Atomu2014/product-nets
https://github.com/hexiangnan/attentional_factorization_machine
https://github.com/hexiangnan/neural_factorization_machine
https://github.com/ChenglongChen/tensorflow-DeepFM
https://zhuanlan.zhihu.com/p/32563337
https://zhuanlan.zhihu.com/p/28202287

春节 AI 学习狂欢,精品课程 豪华特辑
优惠折上折,福利抢不停!

进入阅读原文获取更多福利
▼▼▼



