【CVPR 2020】SEED:用于场景文本识别的语义增强编解码器框架

本文简要介绍2020年被CVPR录用论文“SEED:Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition”的主要工作。该论文通过引入全局语义信息来解决场景文本识别中的低质量文本的识别。以下内容沿用文章对该方法的缩写:SEED。

随着模型的不断迭代,场景文本识别器在许多规则文本上已经具有足够的鲁棒性。而不规则文本的识别在纠正、多方向编码等模块的帮助下也取得了长足的发展,但是很少有学者会关注到低质量文本识别的问题。面对模糊、遮挡、字体残缺等情况,现有的识别器很难从局部图像特征中识别出字符,因此,这篇文章引入了一个全局的语义信息来指导字符的识别,一些识别样例如Fig.1所示。

Fig.2是SEED的整体结构。SEED可以简单的分成四个部分:第一部分(Encoder)利用CNN以及RNN进行特征提取;第二部分(Semantic Module)利用编码之后的特征进行全局语义信息预测;第三部分(Pre-trained Language Model)用来监督全局语义信息的预测;第四部分(Decoder)是Attention-based文本预测模块。
显而易见,文章的核心内容是围绕Semantic Module展开的。Semantic Module利用来自Encoder中RNN的每个时刻输出特征,并将这些特征Flatten为一维向量I,然后通过两层全连接层预测出全局语义信息S:
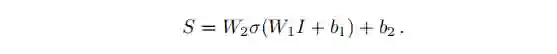
其中W1,W2,b1,b2皆为可训练参数,σ是激活函数ReLU。
该全局语义信息在Decoder阶段将会被用来初始化RNN的隐藏层状态。因此对于Decoder中每个时刻的预测都能够获得到全局语义信息的指导。
同时,在训练阶段,文章引用了FastText[3]的预训练模型来监督全局语义信息S的预测。FastText[3]预训练模型对每一个标签生成一个词向量,相似语义的标签生成的词向量会较为相近。在FastText[3]模型中,词向量由子词向量以及它自身组成,因而可以节省编码维度,可以编码不在词库中的单词。文章使用了Cosine相似度损失函数来监督全局语义信息S的预测,其中em是FastText[3]模型对标签编码的词向量。
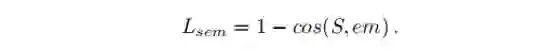
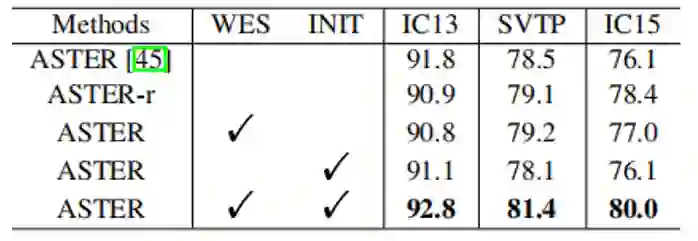
TABLE 1中的结果是在ASTER[1]模型的基础上整合SEED部件的消融实验,INIT是有初始化Decoder的RNN,而WES是有预训练的FastText[3]模型的监督。二者单独使用对几个数据集提升不大,甚至可能会更差。二者的组合使用能够有较大的提升。

Fig.3 展示了预测的全局语义信息与一些单词的cosine相似性。可以发现,全局语义信息与语义相近单词的向量具有比较强的相似性,对于结构相似,语义相差甚远的单词则相似性较低,由此也印证了模型的纠错功能。
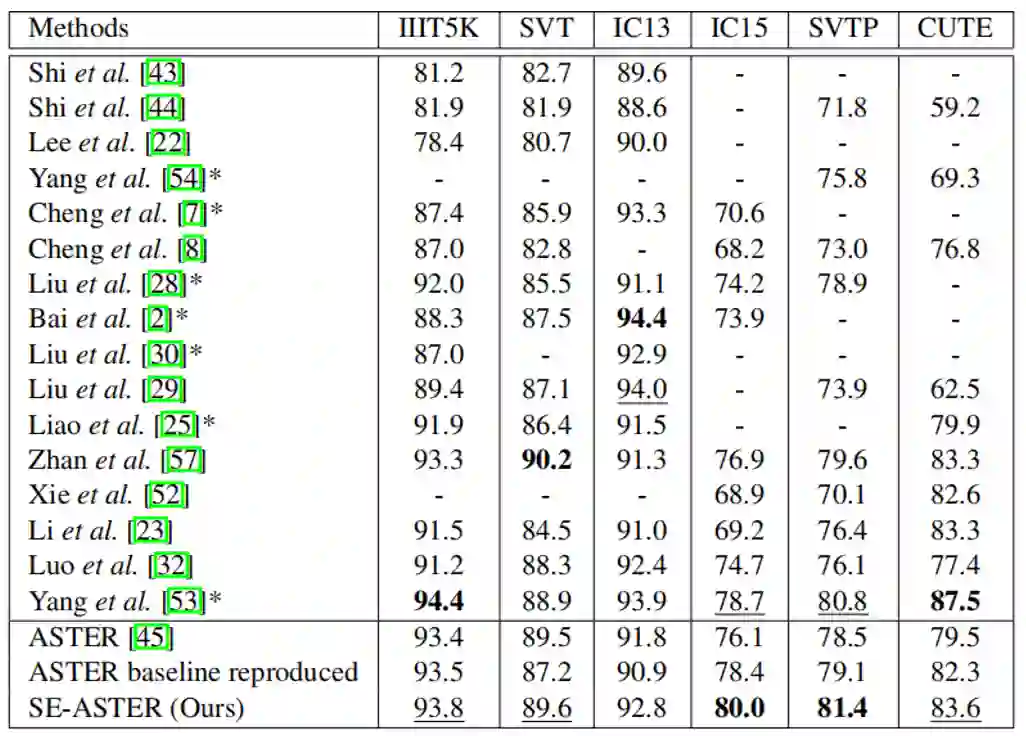
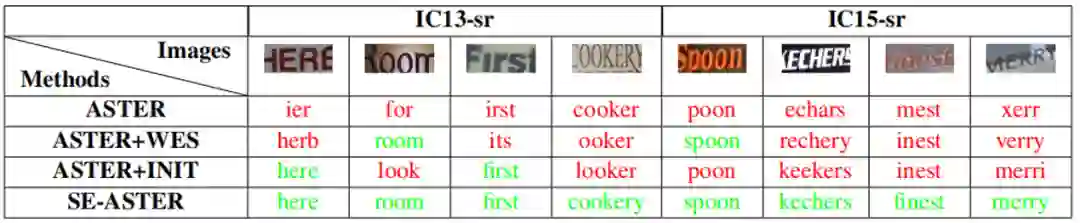

SE-ASTER和SE-SAR分别是在ASTER[1]和SAR[2]与SEED的整合。TABLE 2展示了SE-ASTER与其他SOTA识别器的对比,可以看到SE-ASTER的性能具有一定的竞争力。TABLE 3和 Fig.4是一些识别的可视化,可以看到,SE-ASTER和SE-SAR是能够对低质量文本起到一定作用的。
SEED使用了全局语义信息来初始化Decoder的RNN,这能够提升模型对于低质量文本的鲁棒性。
将SEED与ASTER模型相结合,可以达到SOTA的效果。
SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition论文地址:https://arxiv.org/pdf/2005.10977.pdf
Aster: Anattentional scene text recognizer with flexible rectification论文地址:https://www.vlrlab.net/representatives/6
Show, attend andread: A simple and strong baseline for irregular text recognition论文地址:https://arxiv.org/pdf/1811.00751.pdf
Enriching Word Vectors with Subword Information论文地址:https://arxiv.org/pdf/1607.04606.pdf
参考文献
[1] Shi B, Yang M, Wang X, et al. Aster: An attentional scene text recognizer with flexible rectification[J]. IEEE transactions on pattern analysis and machine intelligence, 2018.
[2] Li, H., Wang, P., Shen, C., Zhang, G., 2018. Show, attend andread: A simple and strong baseline for irregular text recognition,in,in:Thirty-Third AAAI Conference on Artificial Intelligence.
[3] Bojanowski P , Grave E , Joulin A , et al. Enriching Word Vectors with Subword Information[J]. Transactions of the Association for Computational Linguistics, 2017, 5:135-146.
[4] Qiao Z, Zhou Y, Yang D, et al. SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020.
原文作者:Zhi Qiao, Yu Zhou, Dongbao Yang, Yucan Zhou, Weiping Wang
编排:高 学
审校:殷 飞
发布:金连文




