看视频,讲故事,举一反三:详解英特尔弱监督视频密集描述生成模型
机器视觉领域的顶级盛会CVPR2017 于近日在夏威夷圆满落幕。来自英特中国研究院的最新成果 “弱监督视频描述生成”引起了业内的广泛关注。 利用这种方法,即使不对视频数据进行精确标注,计算机依旧可以针对视频中的不同区域内容,生成丰富的语义信息。

近年来,如何自动生成视频描述引起了研究人员的广泛兴趣。我们希望计算机在看到一段视频的时候,可以根据视频的内容“讲故事”。但是,视频描述模型的训练通常需要大量复杂的并且带有一定主观性的人工标注 。在目前的数据集构建过程中,标注人员会在看过一段视频之后,用一句话描述视频的内容。但是,一段视频中通常会发生几个不同的事件,而由于标注人员具有一定主观性,我们既不知道他的描述是针对哪个事件,也不知道他所描述的事件对应不同帧上的哪一个区域。现有方法的局限在于:或者认为一段视频当中只发生了一件事,只需要生成一句描述;或者需要训练数据对视频里的不同事件以及事件对应的不同区域进行详细的标注。这些都给视频的标注工作和结果评估带来了巨大的困难。
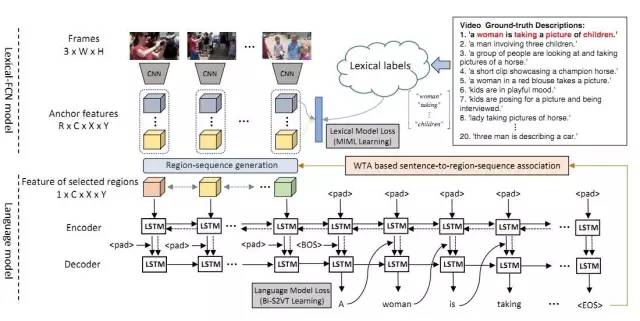
图 1 视频密集描述生成模型
针对上述问题,英特尔中国研究院率先提出了弱监督视频密集描述生成的方法,不需要训练数据对视频中的不同事件和对应区域进行分别标注,而仅仅使用标注员对视频的一句话描述,就可以自动产生多角度的视频描述,并且从中挑选出最具代表性的描述语句。这样,计算机就不用人“手把手教”,而是可以做到“举一反三,舌灿莲花”。
我们的模型可以分为三个部分:
首先,在提取视频特征时,我们提出了Lexical-FCN模型,使用弱监督多实例多标签算法 (Multi-instance Multi-label learning),构建一个从视频的区域序列到单词的弱映射,从而得到一个包含语义信息的视频特征。
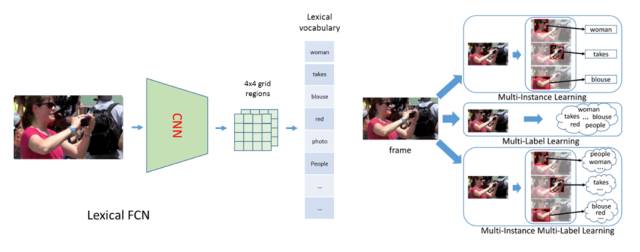
图 2 Lexical-FCN 生成视频区域到单词的弱映射
从图3可以看出,虽然训练数据并没有提供每个单词对应视频帧的位置,模型还是可以学习到视频在不同帧中对单词响应最大的区域。

图 3 视频特征语义响应示意图
其次,在生成视频区域序列时,我们采用子模块最大化方案,根据Lexical-FCN的输出在视频中自动生成具有多样性的区域序列。这种方法可以同时保证区域序列具有一定信息量,在不同帧的区域选择上具有内容一致性,并且可以最大限度的保留序列之间的差异。
转自:英特尔中国



