【教程】如何使用深度学习为照片自动生成文本描述?
选自machinelearningmastery
来源:机器之心
参与:Panda
对图像搜索和帮助视觉障碍者「查看」世界等应用而言,让图像带有文本描述是非常有价值的。使用人力标注显然不现实,而随着深度学习技术的发展,使用机器为图像自动生成准确的文本描述成为了可能。Jason Brownlee 博士的这篇文章对使用深度学习的图像描述进行了介绍,机器之心对本文进行了编译。
图像描述涉及到为给定图像(比如照片)生成人类可读的文本描述。这个问题对人类而言非常简单,但对机器来说却非常困难,因为它既涉及到理解图像的内容,还涉及到将理解到的内容翻译成自然语言。
最近,在为图像自动生成描述(称为「字幕」)的问题上,深度学习方法已经替代了经典方法并实现了当前最佳的结果。在这篇文章中,你将了解可以如何使用深度神经网络模型为照片等图像自动生成描述。
读完本文之后,你将了解:
为图像生成文本描述的难点以及将计算机视觉和自然语言处理领域的突破结合起来的必要性。
神经特征描述模型(即特征提取器和语言模型)的组成元素。
可以如何将这些模型元素组合到编码器-解码器(Encoder-Decoder)中,也许还会用到注意机制。
概述
这篇文章分为三部分,分别是:
1. 使用文本描述图像
2. 神经描述模型
3. 编码器-解码器结构
使用文本描述图像
描述图像是指为图像(比如某个物体或场景的照片)生成人类可读的文本描述。
这个问题有时候也被称为「自动图像标注」或「图像标注」。
这个问题对人类而言轻而易举,但对机器来说却非常困难。
快速一瞥足以让人类指出和描述一个视觉场景的丰富细节。但事实证明,我们的视觉识别模型难以掌握这样出色的能力。
——《用于生成图像描述的深度视觉-语义对齐》,2015
要解决这个问题,既需要理解图像的内容,也需要将其中的含义用词语表达出来,并且所表达出的词语必须以正确的方式串接起来才能被理解。这需要将计算机视觉和自然语言处理结合起来,是广义的人工智能领域的一大难题。
自动描述图像内容是人工智能领域的一个基本问题,该问题将计算机视觉和自然语言处理连接到了一起。
——《Show and Tell:一种神经图像描述生成器》,2015
此外,这个问题也有不同的难度;让我们通过例子看看这个问题的三种不同变体。
1. 分类图像
从数百个或数千个已知分类中为图像分配一个类别标签。

2. 描述图像
生成图像内容的文本描述。
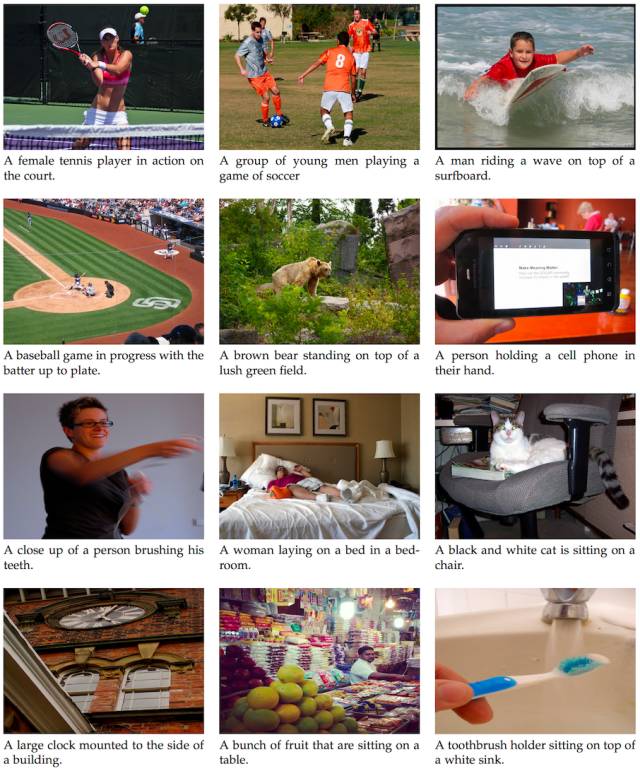
为照片生成描述的示例;来自《用于视觉识别和描述的长期循环卷积网络》,2015
3. 标注图像
为图像中的特定区域生成文本描述。
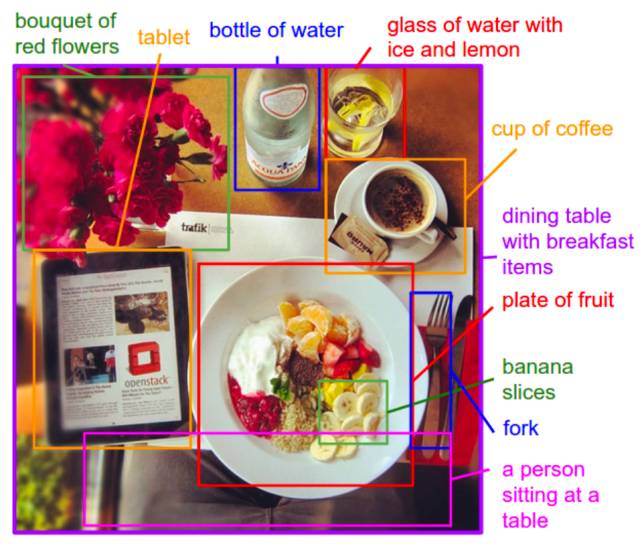
用描述标注图像区域的示例;来自《用于生成图像描述的深度视觉-语义对齐》,2015
这个问题还可以延伸到随时间描述视频中的图像。
在这篇文章中,我们关注的重点是描述图像,我们称之为图像描述(image captioning)。
神经描述模型
神经网络模型已经主导了自动描述生成领域;这主要是因为这种方法得到了当前最佳的结果。
在端到端的神经网络模型之前,生成图像描述的两种主要方法是基于模板的方法和基于最近邻并修改已有描述的方法。
在将神经网络用于生成描述之前,有两种方法占主导地位。第一种涉及到生成描述模板,该模板会基于目标检测和属性发现(attribute discovery)的结果进行填充。第二种方法是首先从一个大型数据库中检索有描述的相似图像,然后修改这些检索到的描述以符合查询的情况。…… 在现在占主导地位的神经网络方法出现后,这两种方法都已经失去了人们的支持。
——《Show and Tell:一种神经图像描述生成器》,2015
用于描述的神经网络模型涉及到两个主要元素:
1. 特征提取
2. 语言模型
特征提取模型
特征提取模型是一种神经网络。给定一张图像,它可以提取出显著的特征,通常用固定长度的向量表示。
提取出的特征是该图像的内部表征,不是人类可以直接理解的东西。
用作特征提取子模型的通常是深度卷积神经网络(CNN)。这种网络可以在图像描述数据集中的图像上直接训练。
或者可以使用预训练的模型(比如用于图像分类的当前最佳的模型),或者也可以使用混合方法,即使用预训练的模型并根据实际问题进行微调。
使用为 ILSVRC 挑战赛在 ImageNet 数据集上开发的表现最好的模型是很常见的做法,比如 Oxford Vision Geometry Group 模型,简称 VGG。
……我们探索了多种解决过拟合的技术。避免过拟合的最明显方法是将我们系统中的 CNN 组件的权重初始化为一个预训练的模型。
——《Show and Tell:一种神经图像描述生成器》,2015

特征提取器
语言模型
一般而言,当一个序列已经给出了一些词时,语言模型可以预测该序列的下一个词的概率。
对于图像描述,语言模型这种神经网络可以基于网络提取出的特征预测描述中的词序列并根据已经生成的词构建描述。
常用的方法是使用循环神经网络作为语言模型,比如长短期记忆网络(LSTM)。每个输出时间步骤都会在序列中生成一个新词。
然后每个生成的词都会使用一个词嵌入(比如 word2vec)进行编码,该编码会作为输入被传递给解码器以生成后续的词。
对该模型的一种改进方法是为输出序列收集词在词汇库中的概率分布并搜索它以生成多个可能的描述。这些描述可以根据似然(likelihood)进行评分和排序。常见的方式是使用波束搜索(Beam Search)进行这种搜索。
语言模型可以使用从图像数据集提取出的预计算的特征单独训练得到;也可以使用特征提取网络或某些组合方法来联合训练得到。
语言模型
编码器-解码器架构
构建子模型的一种常用方法是使用编码器-解码器架构,其中两个模型是联合训练的。
这种模型的基础是将图像编码成紧凑的表征的卷积神经网络,后面跟着一个循环神经网络来生成对应的句子。这种模型的训练目标是最大化给定图像的句子的似然。
——《Show and Tell:一种神经图像描述生成器》,2015
这种架构原本是为机器翻译开发的,其中输入的序列(比如法语)会被一个编码器网络编码成固定长度的向量。然后一个分立的解码器网络会读取这些编码并用另一种语言(比如英语)生成输出序列。
除了能力出色外,这种方法的好处是可以在该问题上训练单个端到端模型。
当将该方法用于图像描述时,编码器网络使用了深度卷积神经网络,解码器网络则是 LSTM 层的堆叠。
在机器翻译中,「编码器」RNN 会读取源句子并将其转换成信息丰富的固定长度的向量表征,这种表征又会被用作「解码器」RNN 的初始隐藏状态,进而生成目标句子。我们在这里提出遵循这种优雅的方案,并使用深度卷积神经网络(CNN)替代编码器 RNN。
——《Show and Tell:一种神经图像描述生成器》,2015
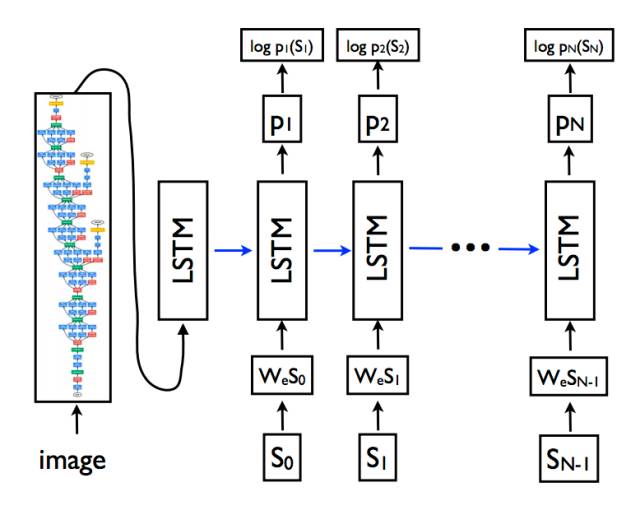
CNN 和 LSTM 架构的示例,来自《Show and Tell:一种神经图像描述生成器》,2015
使用注意机制的描述模型
编码器-解码器的一个局限性是使用了单个固定长度的表征来保存提取出的特征。
在机器翻译中,这个问题通过在更丰富的编码上开发的注意机制而得到了解决,从而让解码器可以学习在生成翻译中的每个词时应该注意哪里。
这种方法也已经被用于改进用于图像描述的编码器-解码器架构的表现水平——让解码器可以学习在生成描述中每个词时应该关注图像中的哪些部分。
受近来描述生成方面的进步的激励和在机器翻译和目标识别中成功应用注意机制的启发,我们调查了在生成描述时可以关注图像中突出部分的模型。
——《Show and Tell:一种神经图像描述生成器》,2015
这种方法的一大优势是可以准确可视化在生成描述中的每个词时所注意的位置。
我们还通过可视化展示了模型在生成输出序列中对应的词时自动学习关注突出对象的方式。
——《Show and Tell:一种神经图像描述生成器》,2015
用例子理解最简单,如下:

使用注意的图像描述示例,来自《Show and Tell:一种神经图像描述生成器》,2015
进阶阅读
如果你还想进一步更深入地了解图像描述,可以参看这里给出的资源。
论文
《Show and Tell:一种神经图像描述生成器(Show and Tell: A Neural Image Caption Generator)》,2015:https://arxiv.org/abs/1411.4555
《Show, Attend and Tell:使用视觉注意的神经图像描述生成(Show, Attend and Tell: Neural Image Caption Generation with Visual Attention)》,2015:https://arxiv.org/abs/1502.03044
《用于视觉识别和描述的长期循环卷积网络(Long-term recurrent convolutional networks for visual recognition and description)》,2015:https://arxiv.org/abs/1411.4389
《用于生成图像描述的深度视觉-语义对齐(Deep Visual-Semantic Alignments for Generating Image Descriptions)》,2015:https://arxiv.org/abs/1412.2306
文章
维基百科:自动图像标注:https://en.wikipedia.org/wiki/Automatic_image_annotation
Show and Tell:在 TensorFlow 中开源的图像描述:https://research.googleblog.com/2016/09/show-and-tell-image-captioning-open.html
Andrej Karpathy 和李飞飞:使用卷积网络和循环网络的自动图像描述;视频:https://www.youtube.com/watch?v=xKt21ucdBY0 ;幻灯片:https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
项目
用于生成图像描述的深度视觉-语义对齐,2015:http://cs.stanford.edu/people/karpathy/deepimagesent/
NeuralTalk2:运行在 GPU 上的有效图像描述 Torch 代码,来自 Andrej Karpathy:https://github.com/karpathy/neuraltalk2
原文链接:https://machinelearningmastery.com/how-to-caption-photos-with-deep-learning/
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【重磅】谷歌正式发布TensorFlowLite,半监督跨平台快速训练ML模型
☞ 【胶囊网络】CapsNet日益火爆!Hinton大神横扫AI界的「胶囊网络」如何理解?




