RNN | RNN实践指南(3)
目录
RNN的基本结构
RNN的实现
RNN的调参
RNN问题汇总
(接前文)
3 RNN的调参
a 预备知识
在对RNN进行调参之前,我们需要实现以下几点统一认识:
1)对实现的反向传播算法实施梯度校验;
2)明确数据集已按照一定的比例分为训练集、验证集和测试集;
3)对RNN每轮的(或者是每隔一定轮次的)损失函数值进行记录。
从梯度校验开始说起。如果是自己实现的RNN模型,那么梯度校验是RNN实现中必须的一个步骤。不同于传统机器学习模型,神经网络模型在训练过程中很难实现对单个神经元的跟踪,因此对RNN整体实现的正确性校验必须通过梯度校验完成。梯度校验的思路为:通过梯度定义,函数f(x)的导数f’(x)应等于极限[f(x+h)-f(x-h)]/2h, h→0。对具体某个神经元实现的校验,只需固定其他所有参数,对跟踪目标的神经元加上一个h的扰动,观测| f’(x)- [f(x+h)-f(x-h)]/2h |<Δ是否成立。一般地,在经验上令h和Δ为10-7。
另外,在对RNN进行训练时,需要将数据集分为三个部分,训练、验证和测试集,三类数据集的规模比例一般可以设为:8:1:1。三类数据集的作用分别为:训练集训练模型;验证集验证当前训练结果,判断是否应当终止模型训练,并在调参时使用;测试集确定模型效果。由于神经网络的收敛需要相当长的时间,并且在训练过程中容易出现过拟合,因此判断RNN收敛与否通常通过验证集来判断(early stopping策略),这一点是不同于经典机器学习收敛性判断准则的,需要有一个重新认识。
最后也是所有机器学习调参时必须要有的:记录RNN模型在一定周期上的损失函数值。这可以帮助我们观测模型当前的训练状态,设定调整策略。
b RNN各参数的调整方式
在这三点统一认识的基础上,下面开始介绍RNN的调参细节。RNN主要涉及需要调制的参数有:
1)参数规模,包括:输入层、隐藏层大小、隐藏层层数;
2)梯度优化相关参数,包括:学习率、minibatch大小等超参;
3)模型参数初始化。
接下来将展开介绍RNN的参数调整细节。
b.1 参数规模设置
不管使用的是何种学习算法,在具体应用前都需要明确问题规模,对问题有一个经验认识,并根据经验认识来进行模型的初始设置。对RNN进行参数调整的第一步也必须遵循此原则。RNN调参的第一步是要确定RNN的参数规模。由于RNN模型相对传统机器学习模型的规模有了很大提升,极易因为参数设置不当而导致过拟合问题,过拟合现象具体表现为:在训练集上收敛,在验证集上不收敛。其损失函数的曲线表现形式为:
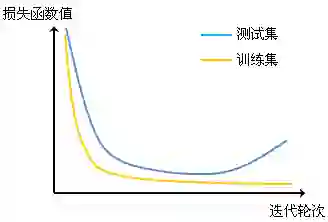
图 8 参数规模过大导致过拟合现象,表现为在训练和验证集上损失函数的收敛情况存在差异。
一般当RNN训练时出现这种情况时,需要尽量减少模型的参数规模,重新训练模型。一般在经验上我们设参数规模不大于训练集大小的10%。
参数规模的调整有时需要对训练过程有很长的观测,在有一些应用问题上可能会出现这样的损失函数曲线。

图 9 RNN的损失函数曲线表现出在更小规模参数情况下收敛情况优于更大规模参数情况下的模型结果。
一般情况下,建议在对参数规模的调整中,先取较小规模的参数量,在保证RNN结果收敛的情况下,逐步增加参数的数量用以确定模型最优的参数规模情况。
案例 问题:有一个字典规模为100的语料库,要求利用RNN拟合语料库中句子的生成过程。
|
增加隐藏层层数有时比单纯增加输入、输出层大小来提高模型参数规模要更为有效。但在不少问题上由于数据规模、计算资源的限制,隐藏层的增加非常有限。对隐藏层层数的设置建议从单层开始逐次的增加隐藏层层数,并最终确定隐藏层层数。
b.2 梯度相关参数的调整
梯度相关的参数根据具体的梯度优化策略存在变化。这里我们列举三种在RNN中较为典型的梯度优化策略来说明梯度相关参数的调整方法。
1) 普通的梯度优化策略,以及带moment(动量)的梯度优化策略。
由于普通的以及带moment的梯度优化策略实现较为简便,单次迭代的计算效率很高,并且算法本身对凸函数有严格的收敛保证,因此这组梯度优化策略主要适合在前期讨论RNN对问题的适用性上时使用。这组梯度优化策略所涉及的参数主要是学习率α的调节。一般地,学习率α的初始值可以从1/0.1开始,以每次调节降低一个量级逐步尝试(例如:1,0.1,0.01,0.001,…),直至适合当前的问题。如果选用带moment的梯度优化策略,对于动量部分的参数可以选择一个经验的固定值(一般为0.9)。由于普通和带moment的梯度优化策略对具体问题的优化效率相比后两组梯度优化策略要低很多,因此调参只需粗粒度的简单进行即可。
2) Adagrad优化策略[1]。
Adagrad优化策略对比上一组梯度优化策略,其优势是在训练过程中所涉及的所有变量的学习率都能根据当前的学习情况自适应的调整(具体Adagrad算法在我之前所发布的《梯度求解六式》中已做了介绍,可自行前往查看)。一般情况下,Adagrad的收敛速度和收敛时的结果要明显优于普通的梯度优化策略,因此Adagrad可以作为具体实现RNN的梯度策略之一。Adagrad需要调节的参数只有初始学习率η,其调节策略也是以每次调节降低一个量级逐步尝试,一般从0.1开始(例如: 0.1,0.01,0.001,…)。
3) Adam优化策略[2]。
Adam优化策略在实际问题中优化效率有时比Adagrad更佳。我个人也比较偏好在RNN的具体实现中采用这一优化策略。Adam的问题是有可能在一些应用上会存在较难收敛的情况(这也是为什么要选用普通的梯度优化策略的原因:确定问题是否适用RNN解决,然后采用高效的梯度优化策略)。Adam的具体实现方式在我之前所发布的《梯度求解六式》中已做了介绍。Adam需要调节的参数一般只有学习率α,调节策略以每次调节降低一个量级逐步尝试,一般从0.1开始(例如: 0.1,0.01,0.001,…)。Adam中另外两个参数一般固定为β1=0.9,β2=0.999。
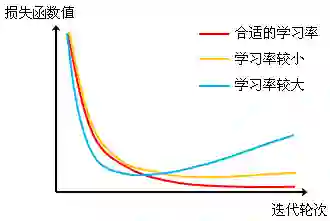
补充:梯度参数调整进阶(这里只关注Adagrad和Adam这两种方法) 之前的梯度调试我们只涉及到了在量级上的调整,一般我们还会在选定梯度量级的基础上做进一步地调整,以保证RNN模型能够收敛到最优情况。 首先,我们要明确一个观念,选用不同的学习率一般会影响RNN的收敛速度,但由于这两种优化策略本身的收敛速度很快,因此不同学习率的设置主要差别在于优化初期是否能够快速进入优化相对较为稳定的阶段,逐步逼近RNN最优解。但要注意的是,较快进入优化相对较为稳定的阶段不一定意味着最终RNN能够收敛到一个更好的结果上去。因此在调整学习率的问题上,我们需要观察不同学习率下RNN在收敛情况下的表现结果,确定最终的学习率值。这里我们给出一组示例来说明: 图 10 在不同学习率下RNN的收敛曲线。
在对学习率设置进行微调时,我们一般以当前选定的学习率(经过量级上的粗调)为界,采用折半查找的方法,在对应量级上确定更好的学习率值。以当前选定的学习率0.01为例,第一轮在[0,1, 0.01]区间(对应10-2量级)以及[0.01, 0.001]区间(对应10-3量级)内通过折半查找选择学习率0.05和0.005作为调试值。对比的在学习率0.01下的模型结果,若在学习率0.01上的模型结果仍为最佳,则继续在[0.05,0.01]和[0.01,0.005]这两个区间上选择做折半查找,选择0.03和0.003继续调试。否则,更改学习率的搜索空间,直至最后选择出最佳的学习率。 |
b.3 模型初始化选择
过去RNN的模型初始化一般有采用高斯、均匀分布这两种方式随机初始化参数。初始化的结果需要缩放到一个固定的范围。对于初始化的参数矩阵W,经过缩放调整后为:W'= 2*scale*W-scale。这里的scale是经验定义的。一般设定为{0.1, 0.2, 0.3, …, 0.9, 1.0}集合内的某一个值,具体的选择同样可以通过折半查找的方法确定。这里需要注意的是,采用高斯、均匀分布这种基于某种概率分布做随机初始化的方式,其效果会随学习率设置的变化而变化。因此需要采用“表格法(Grid search)”来确定学习率和scale值。例如,我们可以做下表进行记录,确定最优的scale和学习率设置对应为scale=0.5,学习率=0.01。
表1 表格法示意
scale \ 学习率 |
0.05 |
0.01 |
0.005 |
1.0 |
0.8 |
0.7 |
0.6 |
0.5 |
0.6 |
0.3(最优) |
0.5 |
0.1 |
0.65 |
0.7 |
0.55 |
个人建议采用正交矩阵分解的方法来初始化所有的参数矩阵。这样可以避免对模型初始化的讨论,并且正交矩阵分解还能在理论上对RNN梯度爆炸和消失起到预防作用,进一步提高了RNN模型的鲁棒性。
在模型初始化的最后,在提一下关于各层在实现中bias的初始化设置。一般不需要特别调节bias的值,个人一般经验的将各层的bias统一设置为0.1。
RNN调参小结
总结一下关于RNN的调参流程。具体的步骤为:
1)选用一个较小规模的参数设置,选用普通的梯度优化策略,确定RNN模型适用当前问题;
2)调整学习率等相关梯度相关参数,(选择高斯或均匀分布随机初始化参数的情况下)并结合模型初始化确定最终所确定的学习率以及初始化scale参数;
3)逐步增加参数规模,直至确定在当前应用问题下最实用的RNN参数规模。
4 RNN常见应用问题
问:观测的损失函数值存在很大的波动。
答:建议增大观测周期,取观测周期内损失值的均值作为损失变化的判断依据。
问:损失函数值收敛速度较慢。
答:选用Adagrad或Adam作为梯度优化策略,建议增大学习率设置。
问:损失函数不收敛。
答:1)增加训练数据集规模,或减少RNN模型参数规模;2)减小学习率设置;3)确定问题本身是否适合RNN求解。
问:损失函数值在训练集上收敛,在验证集上不收敛。
答:增加训练数据集规模,或减少RNN模型参数规模。
参考文献
[1] J. C. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for onlinelearning and stochastic optimization. Journal of Machine Learning Research,2011.
[2] Kingma, D. P. & Adam, J. B. Adam: A method for stochastic optimization.International Conference on Learning Representation, 2015.
[3] http://sebastianruder.com/optimizing-gradient-descent/
小记
相隔了有一个月,终于又回来啦!这一个月里忙完了毕业大大小小的事,终于可以安静地坐下来把这部分连载内容给踏踏实实的写完啦!这次连载的《RNN实践指南(3)》是全篇最为贴近工程实践的部分,大多为个人在RNN实践过程中结合前人以及自己的经验在RNN调参以及应用实践中的总结。另外,本篇的调参方法也多适合其他的机器学习算法实现(特别是神经网络相关的)。以上讨论的多为RNN实践中的共性问题,对于没有覆盖到具体细节,只要不涉及太多应用领域的知识,可以邮件至wangyongqing.casia@gmail.com留言提问哈:-)



