深度学习面试100题(第31-35题)
31.梯度爆炸会引发什么问题?
解析:
在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
梯度爆炸导致学习过程不稳定。—《深度学习》,2016。
在循环神经网络中,梯度爆炸会导致网络不稳定,无法利用训练数据学习,最好的结果是网络无法学习长的输入序列数据。
32.如何确定是否出现梯度爆炸?
解析:
训练过程中出现梯度爆炸会伴随一些细微的信号,如:
模型无法从训练数据中获得更新(如低损失)。
模型不稳定,导致更新过程中的损失出现显著变化。
训练过程中,模型损失变成 NaN。
如果你发现这些问题,那么你需要仔细查看是否出现梯度爆炸问题。
以下是一些稍微明显一点的信号,有助于确认是否出现梯度爆炸问题。
训练过程中模型梯度快速变大。
训练过程中模型权重变成 NaN 值。
训练过程中,每个节点和层的误差梯度值持续超过 1.0。
33.如何修复梯度爆炸问题?
解析:
有很多方法可以解决梯度爆炸问题,本节列举了一些最佳实验方法。
(1) 重新设计网络模型
在深度神经网络中,梯度爆炸可以通过重新设计层数更少的网络来解决。
使用更小的批尺寸对网络训练也有好处。
在循环神经网络中,训练过程中在更少的先前时间步上进行更新(沿时间的截断反向传播,truncated Backpropagation through time)可以缓解梯度爆炸问题。
(2)使用 ReLU 激活函数
在深度多层感知机神经网络中,梯度爆炸的发生可能是因为激活函数,如之前很流行的 Sigmoid 和 Tanh 函数。
使用 ReLU 激活函数可以减少梯度爆炸。采用 ReLU 激活函数是最适合隐藏层的新实践。
(3)使用长短期记忆网络
在循环神经网络中,梯度爆炸的发生可能是因为某种网络的训练本身就存在不稳定性,如随时间的反向传播本质上将循环网络转换成深度多层感知机神经网络。
使用长短期记忆(LSTM)单元和相关的门类型神经元结构可以减少梯度爆炸问题。
采用 LSTM 单元是适合循环神经网络的序列预测的最新最好实践。
(4)使用梯度截断(Gradient Clipping)
在非常深且批尺寸较大的多层感知机网络和输入序列较长的 LSTM 中,仍然有可能出现梯度爆炸。如果梯度爆炸仍然出现,你可以在训练过程中检查和限制梯度的大小。这就是梯度截断。
处理梯度爆炸有一个简单有效的解决方案:如果梯度超过阈值,就截断它们。
——《Neural Network Methods in Natural Language Processing》,2017.
具体来说,检查误差梯度的值是否超过阈值,如果超过,则截断梯度,将梯度设置为阈值。
梯度截断可以一定程度上缓解梯度爆炸问题(梯度截断,即在执行梯度下降步骤之前将梯度设置为阈值)。
——《深度学习》,2016.
在 Keras 深度学习库中,你可以在训练之前设置优化器上的 clipnorm 或 clipvalue 参数,来使用梯度截断。
默认值为 clipnorm=1.0 、clipvalue=0.5。详见:https://keras.io/optimizers/。
(5)使用权重正则化(Weight Regularization)
如果梯度爆炸仍然存在,可以尝试另一种方法,即检查网络权重的大小,并惩罚产生较大权重值的损失函数。该过程被称为权重正则化,通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。
对循环权重使用 L1 或 L2 惩罚项有助于缓解梯度爆炸。
——On the difficulty of training recurrent neural networks,2013.
在 Keras 深度学习库中,你可以通过在层上设置 kernel_regularizer 参数和使用 L1 或 L2 正则化项进行权重正则化。
34.LSTM神经网络输入输出究竟是怎样的?
解析:
第一要明确的是神经网络所处理的单位全部都是:向量
下面就解释为什么你会看到训练数据会是矩阵和张量
常规feedforward 输入和输出:矩阵
输入矩阵形状:(n_samples, dim_input)
输出矩阵形状:(n_samples, dim_output)
注:真正测试/训练的时候,网络的输入和输出就是向量而已。加入n_samples这个维度是为了可以实现一次训练多个样本,求出平均梯度来更新权重,这个叫做Mini-batch gradient descent。 如果n_samples等于1,那么这种更新方式叫做Stochastic Gradient Descent (SGD)。
Feedforward 的输入输出的本质都是单个向量。
常规Recurrent (RNN/LSTM/GRU) 输入和输出:张量
输入张量形状:(time_steps, n_samples, dim_input)
输出张量形状:(time_steps, n_samples, dim_output)
注:同样是保留了Mini-batch gradient descent的训练方式,但不同之处在于多了time step这个维度。
Recurrent 的任意时刻的输入的本质还是单个向量,只不过是将不同时刻的向量按顺序输入网络。所以你可能更愿意理解为一串向量 a sequence of vectors,或者是矩阵。
python代码表示预测的话:
import numpy as np
#当前所累积的hidden_state,若是最初的vector,则hidden_state全为0
hidden_state=np.zeros((n_samples, dim_input))
#print(inputs.shape): (time_steps, n_samples, dim_input)
outputs = np.zeros((time_steps, n_samples, dim_output))
for i in range(time_steps):
#输出当前时刻的output,同时更新当前已累积的hidden_state
outputs[i],hidden_state = RNN.predict(inputs[i],hidden_state)
#print(outputs.shape): (time_steps, n_samples, dim_output)
但需要注意的是,Recurrent nets的输出也可以是矩阵,而非三维张量,取决于你如何设计。
(1)若想用一串序列去预测另一串序列,那么输入输出都是张量 (例如语音识别 或机器翻译 一个中文句子翻译成英文句子(一个单词算作一个向量),机器翻译还是个特例,因为两个序列的长短可能不同,要用到seq2seq;
(2)若想用一串序列去预测一个值,那么输入是张量,输出是矩阵 (例如,情感分析就是用一串单词组成的句子去预测说话人的心情)
Feedforward 能做的是向量对向量的one-to-one mapping,
Recurrent 将其扩展到了序列对序列 sequence-to-sequence mapping.
但单个向量也可以视为长度为1的序列。所以有下图几种类型:
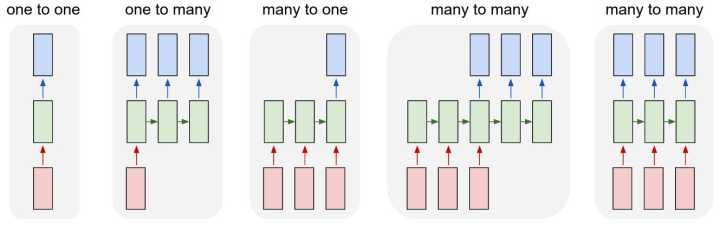
除了最左侧的one to one是feedforward 能做的,右侧都是Recurrent所扩展的
若还想知道更多
(1)可以将Recurrent的横向操作视为累积已发生的事情,并且LSTM的memory cell机制会选择记忆或者忘记所累积的信息来预测某个时刻的输出。
(2)以概率的视角理解的话:就是不断的conditioning on已发生的事情,以此不断缩小sample space
(3)RNN的思想是: current output不仅仅取决于current input,还取决于previous state;可以理解成current output是由current input和previous hidden state两个输入计算而出的。并且每次计算后都会有信息残留于previous hidden state中供下一次计算。
35.什么是RNN?
解析:
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:
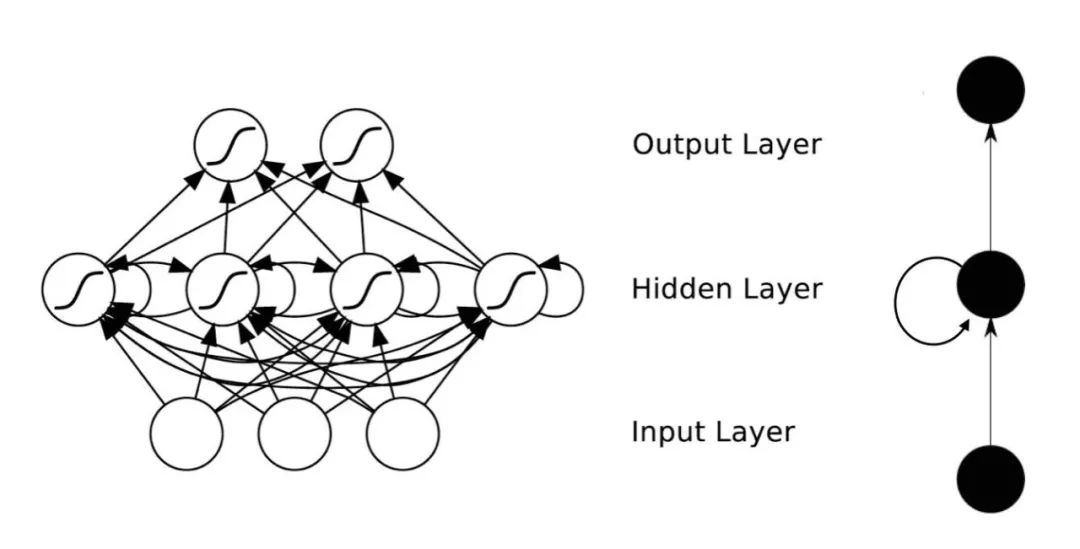
RNNs包含输入单元(Input units),输入集标记为{x0,x1,...,xt,xt+1,...},而输出单元(Output units)的输出集则被标记为{y0,y1,...,yt,yt+1.,..}。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,...,st,st+1,...},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
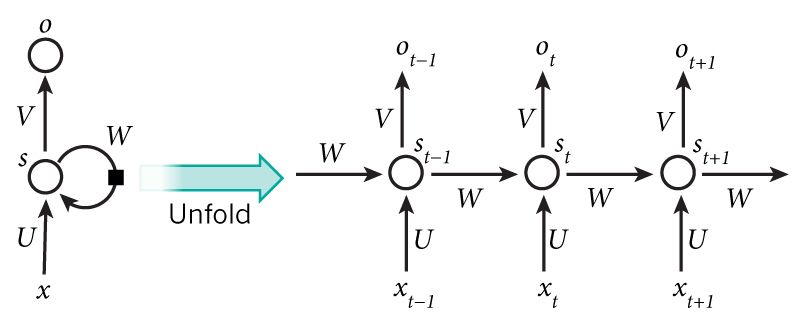
上图将循环神经网络进行展开成一个全神经网络。例如,对一个包含5个单词的语句,那么展开的网络便是一个五层的神经网络,每一层代表一个单词。对于该网络的计算过程如下:
(1)xt表示第t,t=1,2,3...步(step)的输入。比如,x1为第二个词的one-hot向量(根据上图,x0为第一个词);
(2) st为隐藏层的第t步的状态,它是网络的记忆单元。 st根据当前输入层的输出与上一步隐藏层的状态进行计算。st=f(Uxt+Wst−1),其中f一般是非线性的激活函数,如tanh或ReLU,在计算s0时,即第一个单词的隐藏层状态,需要用到s−1,但是其并不存在,在实现中一般置为0向量;
(3)ot是第t步的输出,如下个单词的向量表示,ot=softmax(Vst).
参考资料:
1. YJango,
https://www.zhihu.com/question/41949741
2. 一只鸟的天空,
http://blog.csdn.net/heyongluoyao8/article/details/48636251
题目来源:
七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——深度学习 第26-30题。

为了帮助大家更好的学习和理解深度学习,我们特意推出了“深度学习第四期”课程,7月31日开课,每周二周四晚上8~10点直播上课,每次课至少2小时,共10次课;本课程提供以下服务:直播答疑、课后回放、布置作业且解答、毕业考试且批改、面试辅导。课程详情可点击文末“阅读原文”进行查看,或者加微信客服:julyedukefu_02 进行咨询。
扫码加客服微信