超越MobileNetV3,谷歌提出MobileDets:移动端目标检测新标杆
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
极市导读:在移动端上的目标检测架构,目前比较流行的三大派系分别为:谷歌出品的MobileNet系列(v1-v3)、旷视科技产品的ShuffleNet系列(v1-v2)、Facebook出品的FBNet(v1-v3)系列。最近移动端的目标检测通过结合神经网络架构搜索,又新出了三篇移动端目标检测SOTA模型:一篇出自谷歌大牛Quoc V. Le的MixNet;另一篇出自Facebook 出品的FBNet 的升级版本 FBNetV2,就在6月3日,Facebook又推出了FBNetV3。
而今天,我们介绍的是来自谷歌和威斯康辛麦迪逊分校合作的一篇重量级论文—MobileDets,该论文可以说有着史上最强豪华作者阵营,包括了DARTS的作者-HanXiao Liu、Tan Mingxing(MixNet、MobileNetV3、MnasNet、EfficientNet、EfficientDet都出自他之手)。不得不说,谷歌真的是大牛云集啊!该论文一出,可以说是目前移动端目标检测结合NAS的另一新标杆。
MobileDets

论文地址:
https://arxiv.org/abs/2004.14525
论文摘要:
Inverted bottleneck layers, IBN已成为终端设备SOTA目标检测方法的主要模块。而在这篇文章里,作者通过重新分析研究终端芯片加速下的常规卷积而对“IBN主导的网络架构是否最优”提出了质疑。作者通过将常规卷积纳入搜索空间取得了延迟-精度均衡下的性能提升,得到了一类目标检测模型:MobileDets。在COCO目标检测任务上,基于同等终端CPU推理延迟,MobileDets以1.7mAP性能优于MobileNetV3+SSDLite,以1.9mAP性能优于MobileNetV2+SSDLite;在EdgeTPU平台上,以3.7mAP性能优于MobileNetV2+SSDLite且推理更快;在DSP平台上,以3.4mAP性能优于MobileNetV2+SSDLite且推理更快。与此同时,在不采用FPN的情况下,在终端CPU平台,MobileDets取得了媲美MnasFPN的性能;在EdgeTPU与DSP平台具有更优的mAP指标,同时推理速度快2倍。
Motivation与创新点
本文的Motivation 是关于 depthwise conv 在移动端使用的必要性。由于NAS已成功了搜索到大量具有高性能且适合于特定硬件平台的的模型,比如MobileNetV3、MixNet、EfficientNet、FALSR等等,其中分类模型往往以Inverted bottleneck作为核心关键模块。又因为inverted bottlenecks (IBN) 广泛采用了 depthwise conv + 1x1 pointwise conv 的结构,所以IBN可以减少参数量与FLOPS,同时深度分离卷积极为适合于终端CPU。
尽管如此,深度分离卷积对于当前终端芯片的适配性往往并非最优,比如在EdgeTPU与高通DSP上,具有特定形状的Tensor与核维度的常规卷积往往具有比深度分离卷积更快的速度(甚至高达3倍),尽管具有更多的FLOPS(理论计算复杂度与实际推理速度不成正比)。
因此作者提出一个扩大的搜索空间:包含IBN与受启发于Tensor Decomposition的全卷积序列,称之为Tensor Decomposition Based Search Space(TBD),它可以跨不同终端芯片应用。作者以CPU、EdgeTPU、DSP硬件平台为蓝本,在目标检测任务上采用NAS方式进行网络架构设计。仅仅采用一种简单的SSDLite进行目标检测架构组成,所设计的网络架构称之为MobileDets,在同等推理延迟约束下,它以1.9mAP@CPU、3.7mAP@EdgeTPU、3.4mAP@DSP优于MobileNetV2,同时它以1.7mAP@CPU优于MobileNetV3。与此同时,在未采用NAS-FPN的条件下,取得了媲美此前终端SOTA方法MnasFPN的性能且具有更快的推理速度(在EdgeTPU、DSP上快2倍)。

本文的贡献主要包含以下几点:
-
广泛采用
IBN-only的搜索空间对于EdgeTPU、DSP等终端加速芯片平台是次优的; -
作者提出一种新颖的搜索空间--
TBD,它通过研究了常规卷积的作用可以适用于不同的终端加速芯片; -
通过学习利用网络中选定位置的常规卷积,验证了采用NAS工具可以为不同的加速硬件平台挖掘具有高性能的网络架构;
-
提出来一类可以在多个终端加速芯片平台上达到SOTA性能的方法:
MobileDets。
Revisiting Full Convs in Mobile Search Spaces
在这里,我们首先对IBN模块进行了介绍,并且解释了为什么IBN层可能不足以适用于除终端CPU以外的其它终端加速平台。尽管常规卷积可能会具有更多的FLOPS,但有时候,在某些终端加速平台中(比如 EdgeTPU 和 DSPs),常规卷积会比深度分离卷积快3x。因此,我们基于常规卷积提出了两种新的blocks,以丰富我们的搜索空间。最后,我们讨论了这些构件的布局与Tucker / CP分解的线性结构之间的关系。
Inverted bottlenecks (IBN)。如下图 Fig.2 所示,输入的 shape 为 (N, C1, H1, W1),先过一个 1 * 1 pointwise conv,和 input expansion ratio s, 变成 (N,s * C1, H1, W1)。随后过一个 K * K 的 depthwise conv 变成 (N, s * C1, H2, W2);最后过 1 * 1 的 pointwise conv 变成 (N, C2, H2, W2)。IBN 里面用到了两次 pointwise conv 和一次 depthwise conv。在上述的参数中,C1, s, K, C2 都是可以搜的参数。
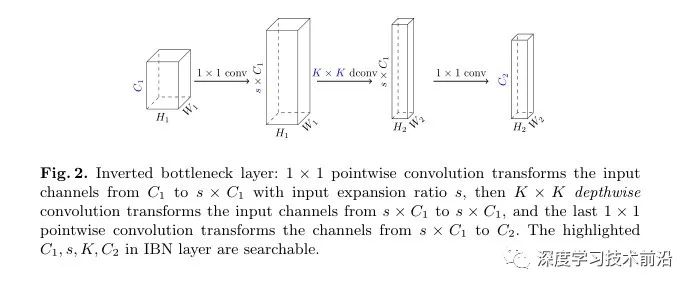
IBN的优缺点:
IBN模块旨在降低参数量与减少FLOPS,虽然利用深度分离卷积可以实现在终端CPU平台的推理加速。然而,在其他终端加速器(如EdgeTPU、DSP)上,尽管具有更多的FLOPS,常规卷积往往比深度分离卷积更快(3x)。这就意味着,对于现代移动加速器而言,广泛使用的IBN-only搜索空间可能不是最佳选择。鉴于此,作者提出另外两种用于通道扩展和压缩的灵活层。
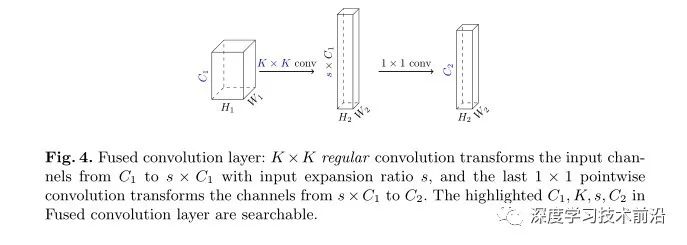
第一种:Fused Inverted Bottleneck Layers (Expansion)
由于深度分离卷积是IBN的重要组成成分,其背后核心思想:采用深度卷积+1x1point卷积替换expensive的全卷积(即常规卷积)。但是这种expensive的定义大多源自于FLOPS或者参数量,而非实际硬件平台的推理速度。因此在这里,我们直接通过一个 K * K 的普通的卷积在 spatial 维度上计算,加上一个 1* 1 的 pointwise conv 改变 channel。这样就可以直接不要 depthwise conv了。具体形式如下图所示:
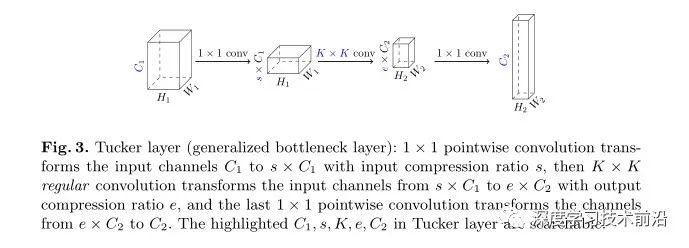
第二种:Tucker layer(Generalized Bottleneck Layers)
它是比 inverted bottlenecks 更泛化的形式,如下图 Fig.3,Bottleneck首次是由ResNet引入并用于降低高维特征的计算量,它采用两个1x1卷积进行通道降维与升维。Bottleneck有助于在更细粒度层面控制通道大小(通道大小将直接影响推理延迟),在此基础上,作者引入两个压缩比例系数对其进行了扩展,整体架构见下图。作者将这种改进后的模块称之为Tucker Convolution。
由于 depthwise conv 的输入和输出 channel 要求是一样的,作者这里把它替换成了 K * K 的普通 conv, 输出 channel 变成了 e * S1。这样就多了一个可以搜的参数 e 。
Search Space Definition
-
IBN:仅包含IBN的最小搜索空间。kernel size在(3,5)中选择, expansion factors在(4,8)中选择。
-
IBN + Fused:扩大的搜索空间,不仅包含上述所有IBN变体,而且还包含融合卷积层以及可搜索的kernel size(3,5)和expansion factors(4,8)。
-
IBN + Fused + Tucker:进一步扩大的搜索空间,其中另外包含Tucker(压缩)层。每个Tucker层都允许在(0.25,0.75)之内搜索输入和输出压缩比。
对于上述所有搜索空间变体,我们还将在(0.5,0.625,0.75,1.0,1.25,1.5,2.0)乘以基本通道大小(通常为8的倍数,这样对硬件设备比较好)之间搜索每一层的输出通道大小。同一block中的层共享相同的基本通道大小,尽管它们最终可能会得到不同的通道数。所有block的基本通道大小为32-16-32-48-96-96-160-192-192。乘法器和基本通道的大小的设计类似参考文献中的几种代表性架构,例如MobileNetV2和MnasNet。
Search Space Ablation
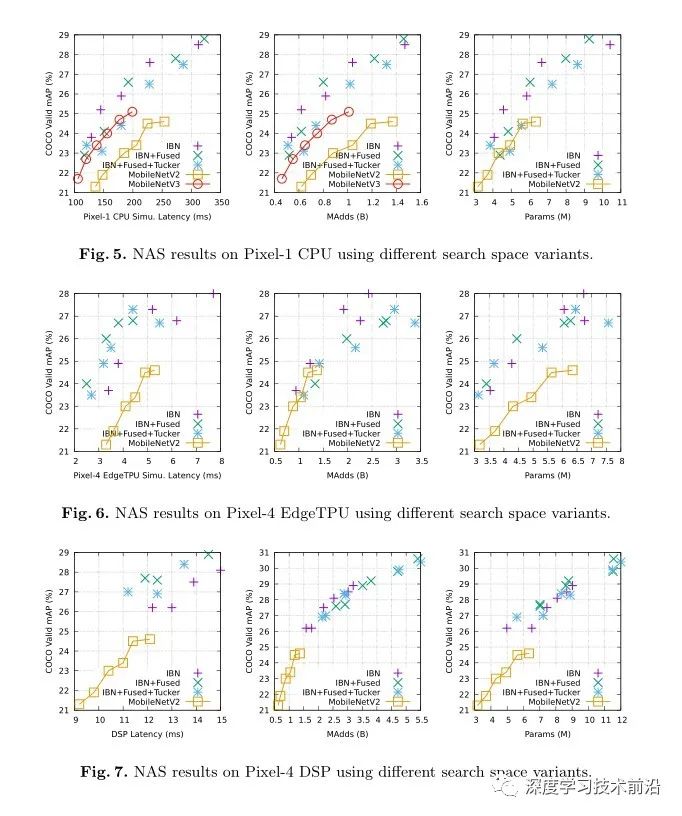
针对三种不同的硬件平台(CPU,EdgeTPU和DSP),我们利用上述三种不同的搜索空间进行架构搜索,并通过从头开始训练得到的模型来评估搜索的模型。目的是在与NAS算法配对时验证每个搜索空间的有效性。使用完美的架构搜索算法,可以确保最大的搜索空间胜过较小的搜索空间,因为它包含了后者的解决方案。但是,实际上并不一定是这种情况,因为该算法可能会获得次优的解决方案,尤其是在搜索空间较大的情况下。 因此,如果搜索空间使NAS方法能够识别足够好的架构,即使它们不是最佳的,它也被认为是有价值的。
最后在三个搜索空间上搜出来的结构如下图 Fig. 8。结果也验证了之前的 motivation,包含普通的卷积的 Tucker layer 和 Fused convolution layer 在 EdgeTPU 和 DSP 上被广泛使用。
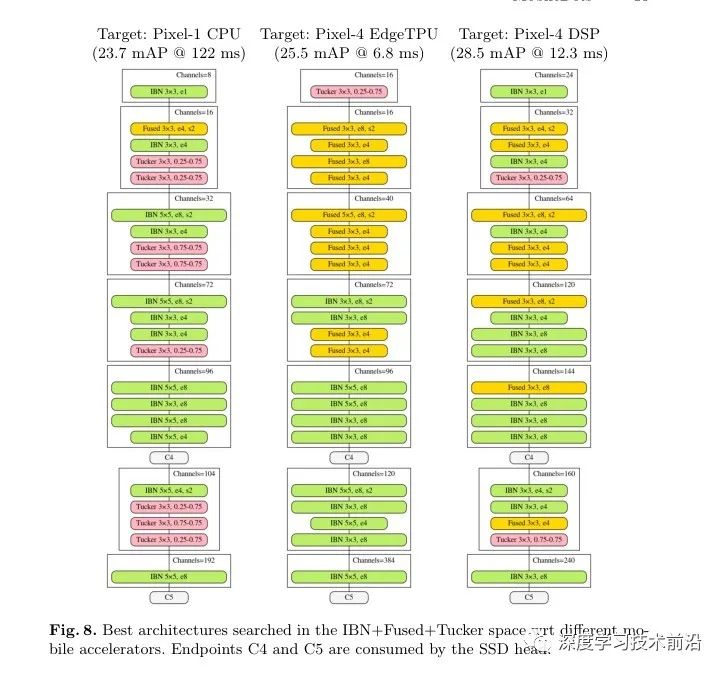
实验结果展示
作者在COCO数据集上将之前最先进的移动检测模型和文章中通过搜索得到的网络架构在终端平台进行性能测试对比,见下表。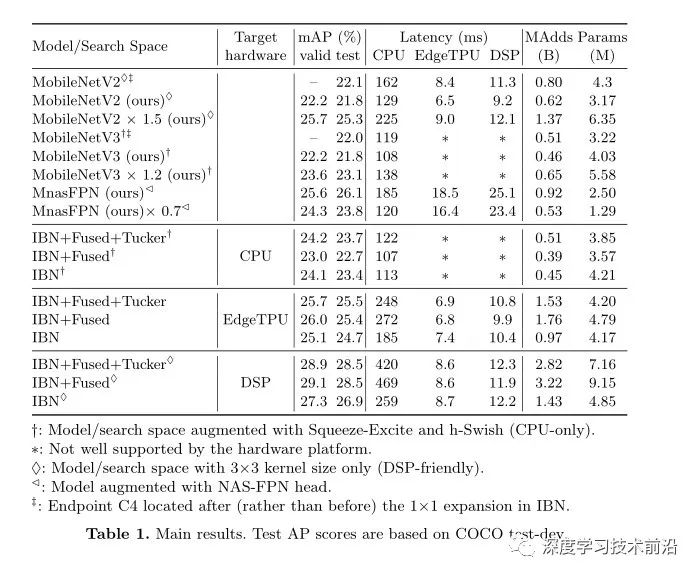
1. 终端CPU:
-
在同等推理延迟下,MobileDet以1.7mAP指标优于MobileNetV3+SSDLite;
-
在不采用NAS-FPN中的head情况下,取得了媲美MnasFPN的性能。因此哦我们可以得出:IBN确实是可以适用于终端CPU平台的模块。
2. EdgeTPU:
-
在同等推理延迟下,MobileDet以3.7mAP指标优于MobileNetV2+SSDLite。这种性能增益源自:域相关NAS、全卷积序列模块(Fused、Tucker)。
3. DSP:
-
MobileDet取得28.5mAP@12.ms的性能,以3.2mAP指标优于MobileNetV2+SSDLite;
-
以2.4mAP指标优于MnasFPN,同时具有更快的推理速度。
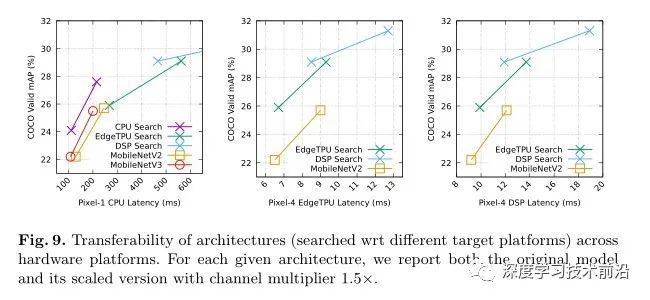
最后,作者还进行了跨硬件平台网络架构可移植性的性能测试, 图9比较了使用不同硬件平台的MobileDets(通过针对不同的加速器获得)。我们的结果表明,在EdgeTPU和DSP上搜索的体系结构可以相互移植。实际上,这两种搜索架构都充分利用了常规卷积。另一方面,专用于EdgeTPU或DSP的体系结构(往往是FLOP密集型)无法很好地传输到终端CPU。
Conclusion
本文,作者对以“IBN主导的网络架构是否最优”提出了质疑,以目标检测任务作为基础,重新分析研究了不同终端芯片加速下的常规卷积的有效性。这里主要列举了三种终端加速平台(CPU、EdgeTPU、DSP)。通过一系列的实验结果表明,在不同终端设备加速平台,在网络中合适的位置嵌入常规卷积可以取得精度-推理方面的性能提升。由此产生得到的新架构MobileDets可以在不同硬件平台下取得比以往更优异的检测结果。

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~


