200~1000+fps!谷歌公布亚毫秒级人脸检测算法BlazeFace,面向移动GPU
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
OpenCV中文网@公众号
人脸检测领域每年都会有大量算法被提出,拼精度当然很重要,但真正要做到实际的应用里,算法还必须要快。
算法设计时,追求复杂度低和适合硬件加速(比如适合GPU运算等)是算法加速的两大方向。
今天谷歌刚刚上传到arXiv的一篇论文BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs,推出了BlazeFace算法,这是一款专为移动GPU推理量身定制的轻量级且性能卓越的人脸检测器。
BlazeFace 在旗舰移动设备上以200-1000 + FPS的速度运行。 这种超实时性能使其能够应用于任何对性能要求极高的增强现实应用中。
算法主要创新点:
1)极轻量级特征提取网络,受MobileNet V1/V2启发,但又与其不同;
2)修改的SSD目标检测anchor机制,使其更适于GPU计算;
3)使用tie resolution 策略替换非极大抑制(NMS)。
简单总结,作者在MobileNet-SSD目标检测框架下,改进了网络结构、anchor机制、替换NMS后处理,使算法在人脸检测任务中保持高精度的同时,在移动GPU上速度还很快。
下面是作者信息:

该文作者均来自谷歌研究院。
模型架构与设计
BlazeFace模型架构设计主要考量了四个方面。
增大感受野。
在MobileNet架构中,使用5*5卷积核代替3*3卷积核,扩大感受野,而这种在深度可分离卷积中卷积核大小增大,而带来的计算量增加是有限的。
另外为了促进感受野Size的传递,提出了double BlazeBlock 模块,如下图:
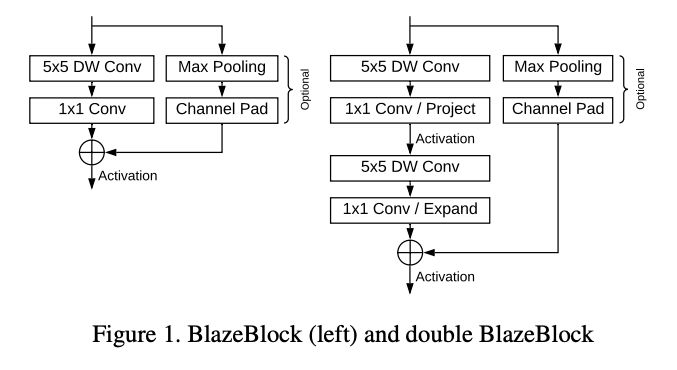
特征提取。
针对前置摄像头人脸检测的特定需要,人脸尺度变化较小,定义更加轻量级的特征提取,输入图像128*128,含有5个BlazeBlock和6个double BlazeBlock。
网络架构如下表:

改进的anchor 机制。
在8×8特征图尺寸处停止而无需进一步下采样(如下图2),将8×8,4×4和2×2分辨率中的每个像素的2个anchor替换为8×8的6个anchor。由于人脸长宽比的变化有限,因此作者们发现将anchor固定为1:1纵横比足以进行精确的面部检测。
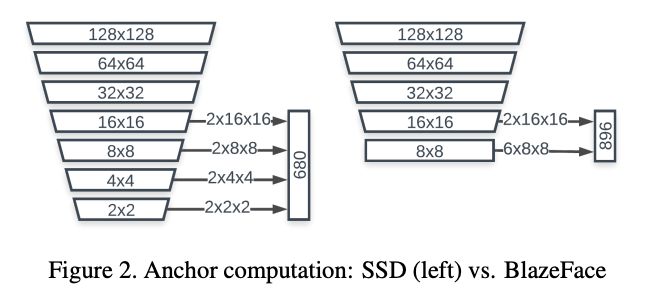
后处理机制
由于上述anchor机制中特征提取器未将分辨率降低到8×8以下,所以与给定对象重叠的anchor数量将会下降。在SSD的NMS中,只有一个胜出的anchor用于算法输出,这导致在视频中进行检测时,人脸框抖动明显。
为了降低这种效应,作者不再使用NMS,代之一种blending策略,将边界框的回归参数估计为重叠预测之间的加权平均值。它几乎不会产生之前NMS部分的成本。作者称对于在视频中的面部检测任务,此调整导致准确度提高10%。
实验结果
该文重点说明在手机终端真实应用中,检测算法的加速,故没有与目前精度达到SOTA的算法在公开数据库精度的比较。而只是在谷歌的私有数据集上与MobileNetV2-SSD的比较。
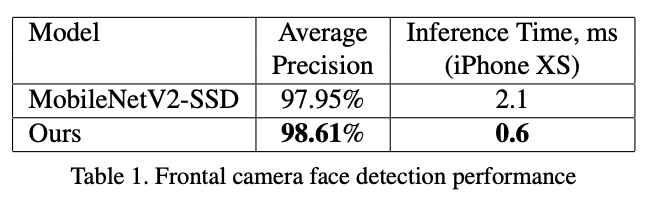
下图是比较结果,精度高于MobileNetV2-SSD,在iPhone XS上的速度也从2.1毫秒降到0.6毫秒。
更多手机上的运算速度比较:
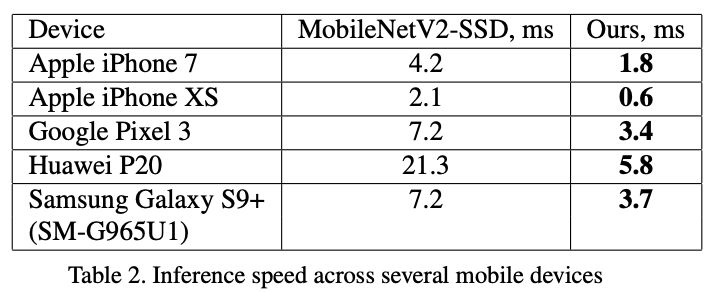
BlazeFace在不同的手机上都获得了成倍的速度提升!
下图中红色框和点是BlazeFace的输出结果,这六个点可用于人脸校正。
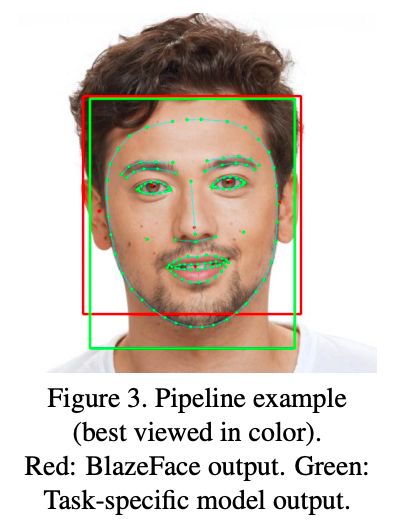
绿色框和点是其他特定任务输出的人脸框和各器官轮廓点,因为BlazeFace很快,可以很方便将一些快速人脸对齐算法与其结合。
作者在文末说“The technology described in this paper is driving major AR self-expression applications and AR developer APIs on mobile phones.”,可见BlazeFace已经被谷歌用于实际的工程中,所以对于工业界的朋友,这篇文章非常值得参考。
论文地址:
https://arxiv.org/pdf/1907.05047v1.pdf
-完-
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~


