谷歌开源EfficientDet:实现新SOTA,又快又准的目标检测器
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:机器之心@微信公众号
什么检测器能够兼顾准确率和模型效率?如何才能实现?
去年11月底,谷歌大脑提出 EfficientDet,在广泛的资源限制下,这类模型的效率仍比之前最优模型高出一个数量级。具体来看,结构只使用了 52M 参数、326B FLOPS 的 EfficientDet-D7 在 COCO 数据集上实现了 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,而后者的 FLOPS 更是 EfficientDet-D7 的 9.3 倍。EfficientDet公布后,在COCO榜单上达到了史无前例的成绩。
昨天,谷歌开源了精简版EfficientDet-Lite,今天,官方公布了基于TensorFlow的完整代码:
代码链接:
https://github.com/google/automl/tree/master/efficientdet
论文链接:
https://arxiv.org/abs/1911.09070
下面,我们简单的介绍一下EfficientDet。
先看看效果
图 1 和图 4 展示了多个模型在 COCO 数据集上的性能对比情况。在类似的准确率限制下,EfficientDet 的 FLOPS 仅为 YOLOv3 的 1/28、RetinaNet 的 1/30、NASFPN 的 1/19。
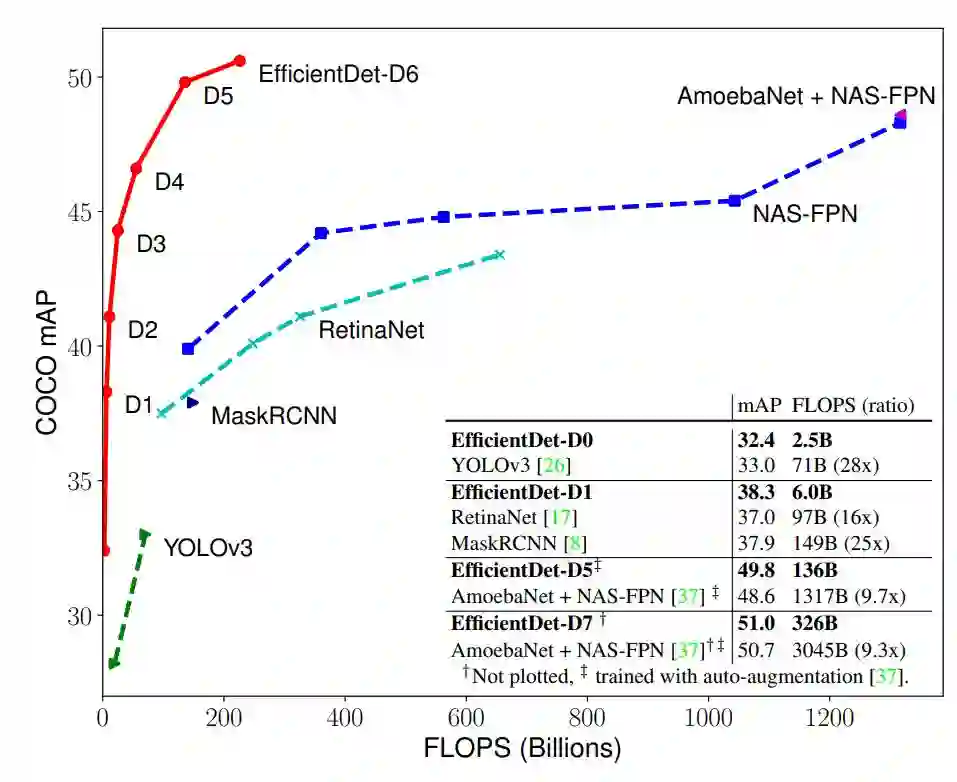
图 1:模型 FLOPS vs COCO 数据集准确率,所有数字均为单个模型在单一尺度下所得。EfficientDet 的计算量较其他检测器少,但准确率优于后者,其中 EfficientDet-D7 获得了当前最优性能。
具体而言,在都使用单个模型和单一测试时间尺度的前提下,EfficientDet-D7 以 52M 的参数量和 326B FLOPS,获得了当前最优性能 51.0 mAP,超出之前最优模型 0.3%,而且其规模和 FLOPS 分别是之前最优模型的 1/4 和 10.8%。此外,EfficientDet 模型在 GPU 和 CPU 上的计算速度分别是之前检测器的 3.2 倍和 8.1 倍,参见图 4 和表 2。
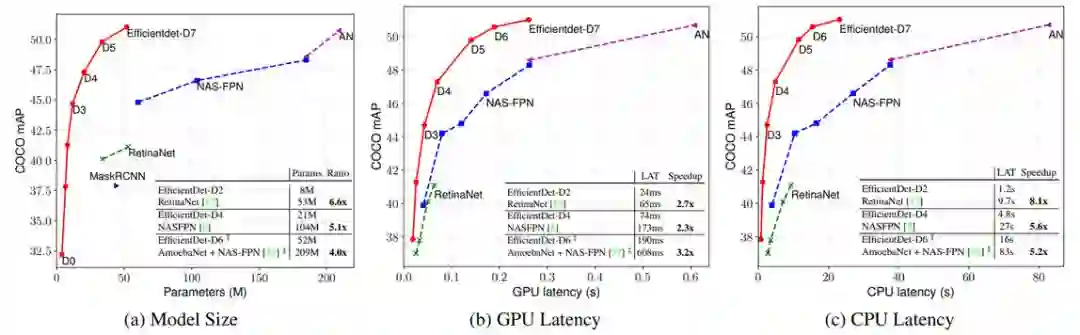
图 4:模型大小和推断延迟对比。延迟均为使用批大小 1 在同样的机器上测量得到(这些计算机均配备一块 Titan V GPU 和 Xeon CPU)。AN 表示使用自增强训练得到的 AmoebaNet + NAS-FPN。
目标检测能够既准确又快速吗?
我们常常有一个概念,SSD 等单阶段目标检测器很快,但准确性比不上 Mask R-CNN 等两阶段目标检测器,尽管两阶段目标检测推断速度要慢许多。那么有没有一种兼顾两者的目标检测器?设计这样的检测器又会出现什么挑战?这就是该论文作者所关心的。
近年来,在实现更准确的目标检测方面出现了大量进展,然而当前最优目标检测器的成本也越来越高昂。例如,近期提出的基于 AmoebaNet 的 NASFPN 检测器需要 167M 参数和 3045B FLOPS(是 RetinaNet 的 30 倍)才能获得当前最优准确率。大模型规模和昂贵的计算成本阻碍了它们在一些现实世界应用中的部署,例如模型规模和延迟高度受限的机器人、自动驾驶汽车等应用。由于这些现实世界的资源限制,模型效率对于目标检测的重要性越来越高。
已经有很多研究试图开发更高效的检测器架构,如单阶段检测器和 anchor-free 检测器,或者压缩现有模型。尽管这些方法可以实现更优的效率,但这通常是以准确率为代价的。此外,大部分之前研究仅关注某个或某些特定的资源要求,而大量现实应用(从移动设备到数据中心)通常具备不同的资源限制。
那么问题来了:在面对广泛的资源约束时(如 3B 到 300B FLOPS),构建兼具准确率和效率的可扩展检测架构是否可行?
谷歌大脑的这篇论文系统性地研究了多种检测器架构设计,试图解决该问题。基于单阶段检测器范式,研究者查看了主干网络、特征融合和边界框/类别预测网络的设计选择,发现了两大主要挑战:
挑战 1:高效的多尺度特征融合。尽管大部分之前工作融合了不同的输入特征,但它们仅仅是不加区分地将其汇总起来。而由于这些输入特征的分辨率不尽相同,它们对输出特征的贡献也不相等。
挑战 2:模型缩放。尽管之前研究主要依赖大型主干网络或者较大的输入图像规模,但研究者发现,在同时考虑准确率和效率的情况下,扩大特征网络和边界框/类别预测网络非常关键。
针对这两项挑战,研究者提出了应对方法。
挑战 1:高效的多尺度特征融合。研究者提出一种简单高效的加权双向特征金字塔网络(BiFPN),该模型引入了可学习的权重来学习不同输入特征的重要性,同时重复应用自上而下和自下而上的多尺度特征融合。
挑战 2:模型缩放。受近期研究 [31] 的启发,研究者提出一种目标检测器复合缩放方法,即统一扩大所有主干网络、特征网络、边界框/类别预测网络的分辨率/深度/宽度。
最后,研究者观察到,近期出现的 EfficientNets [31] 效率超过之前常用的主干网络。于是研究者将 EfficientNet 主干网络和 BiFPN、复合缩放结合起来,开发出新型目标检测器 EfficientDet,其准确率优于之前的目标检测器,同时参数量和 FLOPS 比它们少了一个数量级。
BiFPN
作者首先将多尺度特征融合问题公式化,然后为 BiFPN 引入两个主要想法:高效的双向跨尺度连接和加权特征融合。
跨尺度连接
多尺度特征融合旨在聚合不同分辨率的特征。图 2a 展示了传统自上而下的 FPN。它使用 level 3-7 作为输入特征,如果输入分辨率是 640x640,则 level 3 输入特征是 640/2^3 = 80,分辨率为 80x80。依此类推,特征 level 7 的分辨率为 5x5。
传统 FPN 以自上而下的方式聚合多尺度特征:
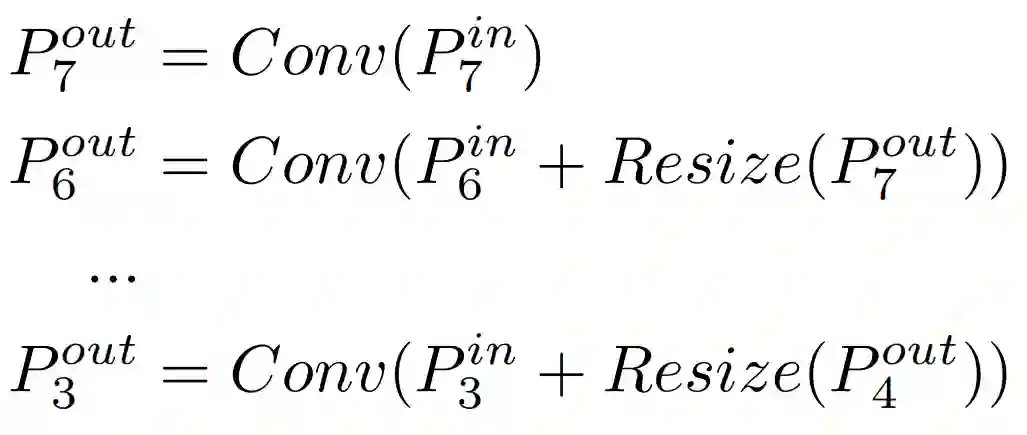
其中 Resize 通常表示分辨率匹配时的上采样或者下采样,Conv 通常表示特征处理时的卷积网络。
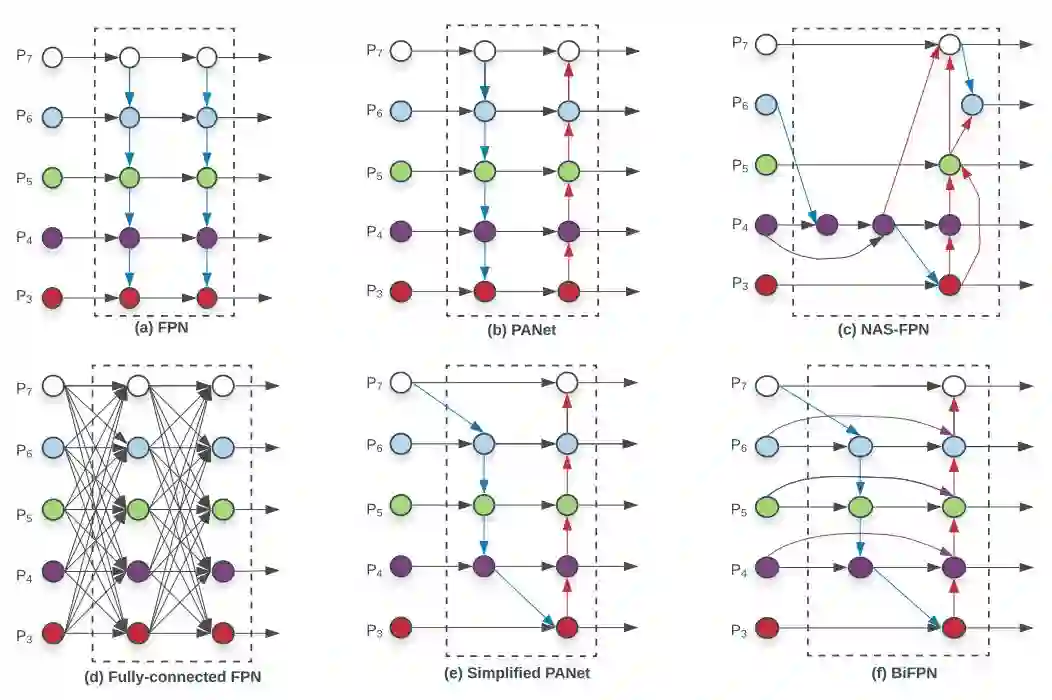
图 2:特征网络设计图。a)FPN 使用自上而下的路径来融合多尺度特征 level 3-7(P3 - P7);b)PANet 在 FPN 的基础上额外添加了自下而上的路径;c)NAS-FPN 使用神经架构搜索找出不规则特征网络拓扑;(d)-(f) 展示了该论文研究的三种替代方法。d 在所有输入特征和输出特征之间添加成本高昂的连接;e 移除只有一个输入边的节点,从而简化 PANet;f 是兼顾准确和效率的 BiFPN。
为了提高模型效率,谷歌大脑研究者提出了针对跨尺度连接的几项优化:
首先,移除仅具备一个输入边的节点。其背后的想法很简单:如果一个节点只有一个输入边没有特征融合,则它对特征网络的贡献较小。这样就得到了简化版 PANet(见图 2e)。
然后,研究者为同级原始输入到输出节点添加额外的边,从而在不增加大量成本的情况下融合更多特征(见图 2f)。
最后,与只有一条自上而下和自下而上路径的 PANet 不同,研究者将每个双向路径(自上而下和自下而上)作为一个特征网络层,并多次重复同一个层,以实现更高级的特征融合。
加权特征融合
在融合不同分辨率的输入特征时,常见的方法是先将其分辨率调整至一致再相加。金字塔注意力网络(pyramid attention network)引入了全局自注意力上采样来恢复像素定位,这在 [5] 中有进一步研究。
之前的特征融合方法对所有输入特征一视同仁,不加区分同等看待。但是,研究者观察到,由于不同输入特征的分辨率不同,它们对输出特征的贡献也不相等。为解决该问题,研究者提出在特征融合过程中为每一个输入添加额外的权重,再让网络学习每个输入特征的重要性。
EfficientDet
基于 BiFPN,研究者开发了新型检测模型 EfficientDet。下图 3 展示了 EfficientDet 的整体架构,大致遵循单阶段检测器范式。研究者将在 ImageNet 数据集上预训练的 EfficientNet 作为主干网络,将 BiFPN 作为特征网络,接受来自主干网络的 level 3-7 特征 {P3, P4, P5, P6, P7},并重复应用自上而下和自下而上的双向特征融合。然后将融合后的特征输入边界框/类别预测网络,分别输出目标类别和边界框预测结果。
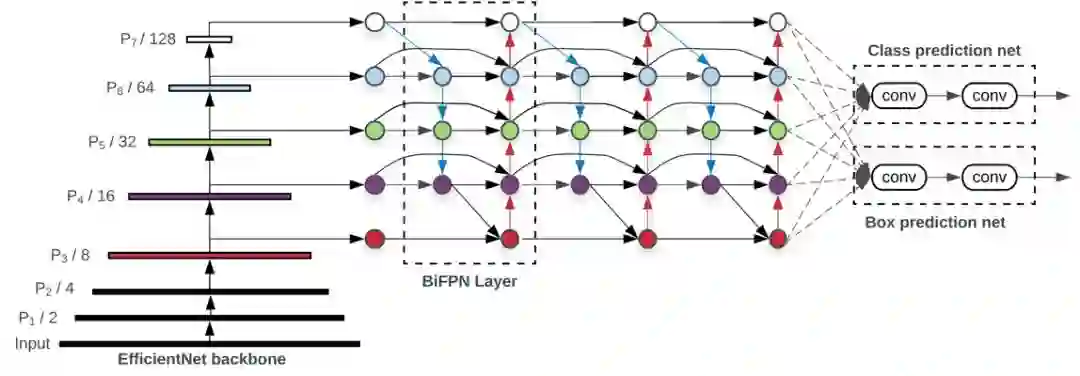
图 3:EfficientDet 架构。它使用 EfficientNet 作为主干网络,使用 BiFPN 作为特征网络,并使用共享的边界框/类别预测网络。
为了优化准确率和效率,研究者试图开发出能够满足广泛资源约束的模型。这里的重要挑战在于,如何扩大基线 EfficientDet 模型。
受近期研究 [5, 31] 的启发,研究者提出一种目标检测复合缩放方法,它使用简单的复合系数 φ 统一扩大主干网络、BiFPN 网络、边界框/类别预测网络的所有维度。
实验
研究者在 COCO 2017 检测数据集上对 EfficientDet 进行评估。EfficientDet 模型是使用批大小 128 在 32 块 TPUv3 芯片上训练而成的。
下表 2 在单个模型单一尺度且没有测试时间增强的设置下,对比了 EfficientDet 和其他目标检测器。在大量准确率或资源限制下,EfficientDet 的准确率和效率均优于之前的检测器。
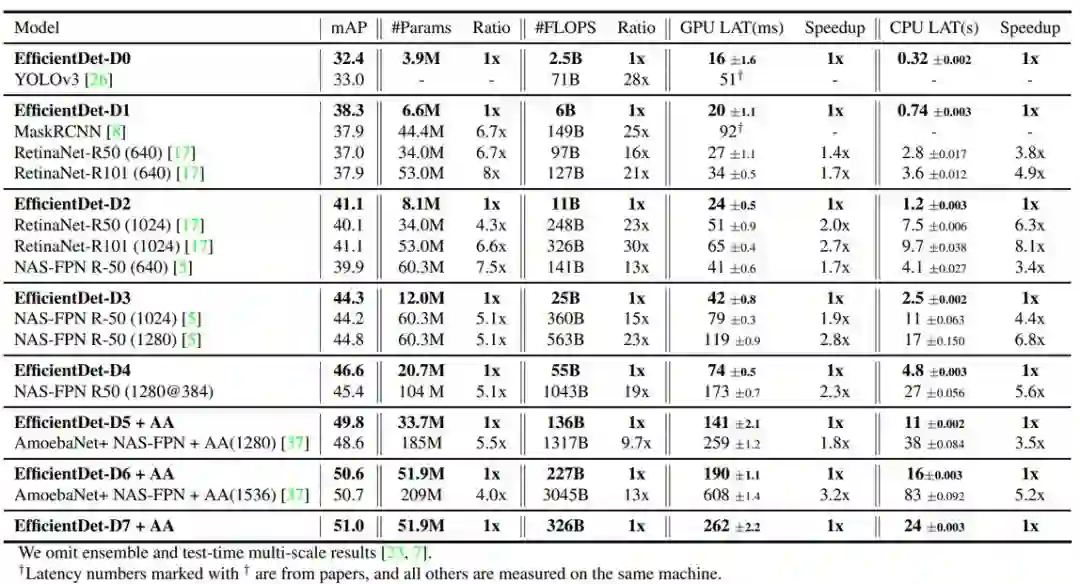
表 2:EfficientDet 在 COCO 数据集上的性能。#Params 和 #FLOPS 表示参数量和 multiply-add 次数。LAT 表示在批大小为 1 时的推断延迟。AA 表示自增强。研究者将准确率类似的模型归类在一起,并对比了每一组中 EfficientDet 与其他检测器的比例或加速。
由于 EfficientDet 既使用了强大的主干网络又应用了新型 BiFPN,研究者想了解这两个网络对准确率和效率提升的贡献。表 3 即对比了二者对模型性能的影响。
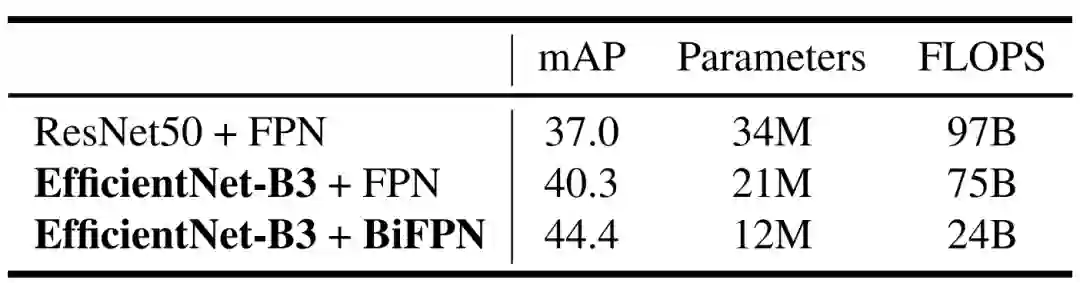
表 3:主干网络和 BiFPN 对模型性能的影响。第一行是标准的 RetinaNet (ResNet50+FPN),研究者首先将其主干网络替换为 EfficientNet-B3(第二行),然后将基线 FPN 替换成 BiFPN(第三行)。
表 4 展示了当特征网络具备图 2 列举的不同跨尺度连接时模型的准确率和复杂度。
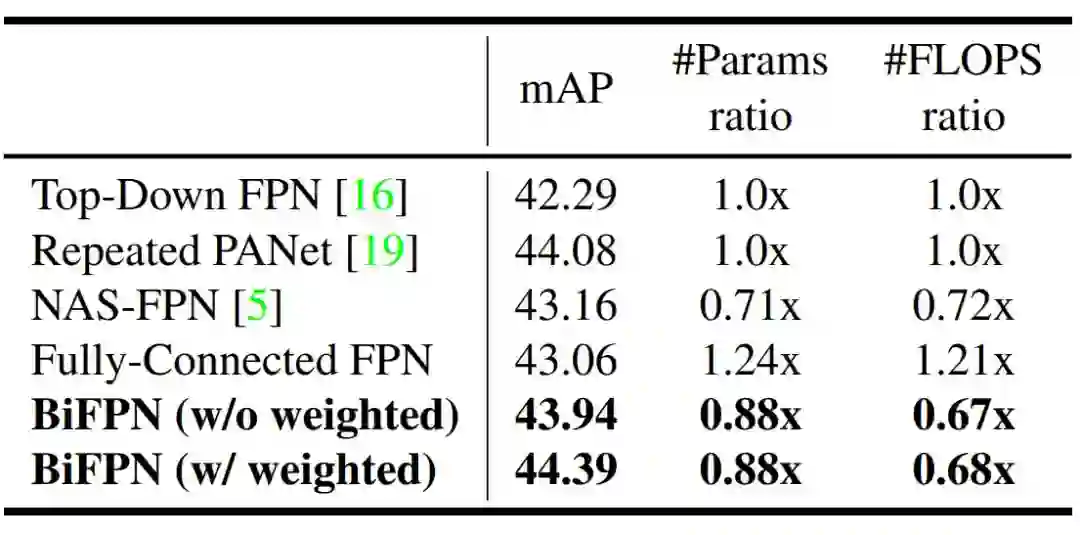
表 4:不同特征网络的对比情况。加权 BiFPN 以更少的参数和 FLOPS 取得了最好的准确率。
研究者使用复合缩放方法,统一扩大主干网络、BiFPN 和边界框/类别预测网络的所有维度——深度/宽度/分辨率。图 6 对比了该复合缩放方法和其他仅扩大其中一个维度的方法。
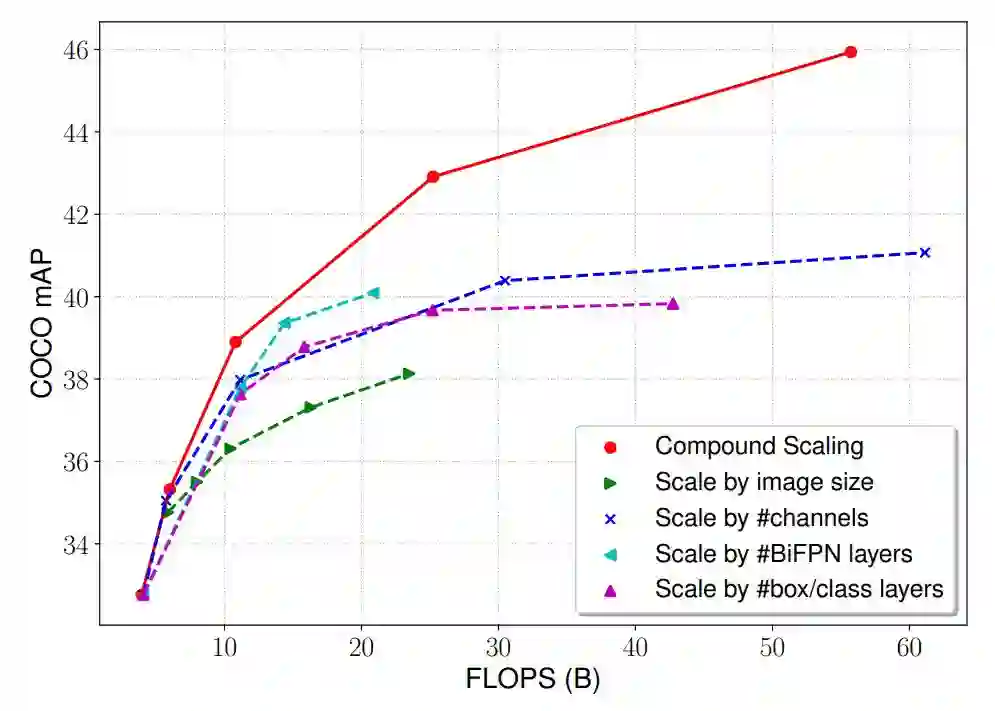
图 6:不同缩放方法的对比。所有方法都能提升准确率,但研究者提出的复合缩放方法实现了更好的准确率和效率的平衡。
推荐阅读:
移动端AI应用太抢手,高通这次要送开发者20万+的SUV!
特殊时期,一起在家打比赛吧!


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~