独家 | 2019 ICCV 收录论文:基于弱监督学习的病理影像分析框架


论文传送门
▼
扫描下方二维码,或点击文末“阅读原文”

一、研究背景
恶性肿瘤是全球第二大死因,每年导致近千万人死亡。病理报告是肿瘤临床诊断和治疗的“金标准”,是癌症确诊和治疗的基本依据。为了缓解世界范围内病理医生短缺的现状,人工智能病理诊断成为当今学术研究和工程落地的热点。数字病理切片的体积通常都在500MB至2GB,像素数超过百亿,有监督的病理诊断模型需要进行繁琐的像素级切片标注,对这一领域的快速发展带来了挑战。
相比之下,弱监督学习仅需要图像级别的粗粒度标签,能够大幅降低标注的工作量。由于单个数字病理切片尺寸过大,仅通过切片级诊断很难获得高准确率的结果(建立弱监督学习模型通常需要超过1万张数字切片 [1]),研究人员通常将数字病理切片划分为若干的图像(image),对每一个图像打上标签(例如在二分类的场景下,如果图像包含有癌区,则标注为1,反之标注为0),进而获得弱监督学习模型。
但是,由于对监督信息利用率不足,在之前发表的研究工作中,弱监督学习算法的准确率远低于有监督学习 [2-5]。在本研究中,我们提出弱监督学习框架CAMEL,通过多实例学习(multiple instance learning, MIL),CAMEL能够通过建模自动生成细粒度(像素级)的标注信息,从而可以使用有监督的深度学习算法完成图像分割模型的建立。通过在CAMELYON16 [6]和解放军总医院肠腺瘤数据集上的验证,CAMEL能够取得接近完全有监督模型的准确率。
二、CAMEL算法设计
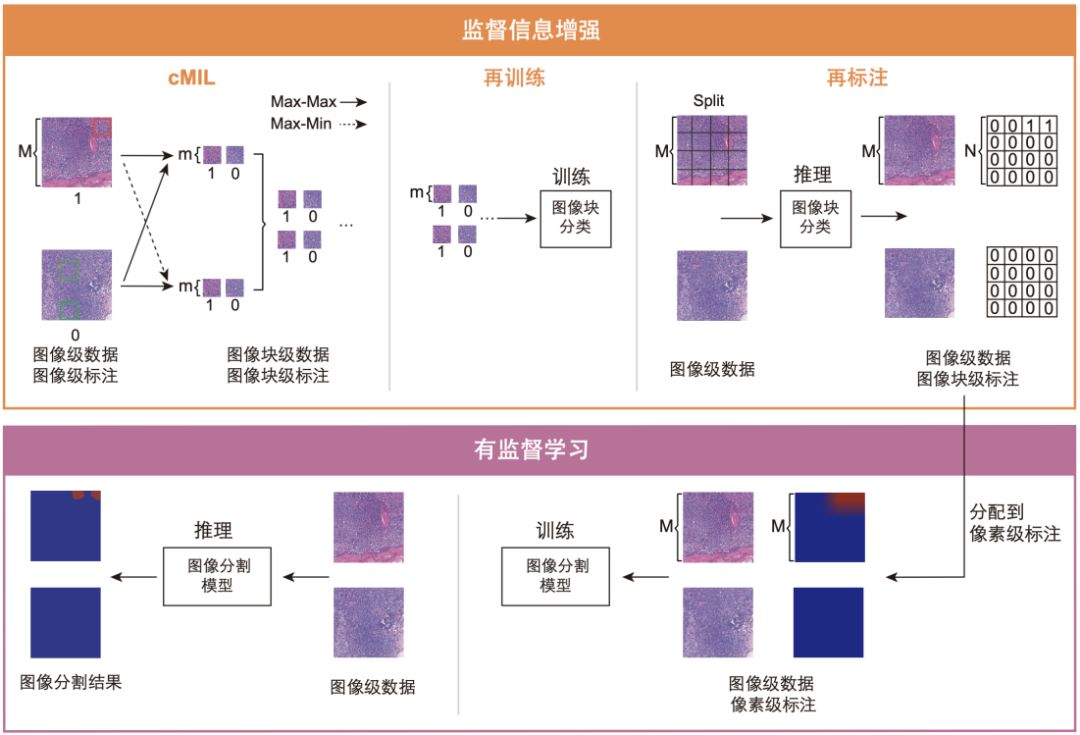
图1: CAMEL系统架构,M和m分别表示图像和图像块的尺寸,N=M/m为比例因子
CAMEL的运行过程包括两个步骤:监督信息增强(label enrichment)和有监督模型训练(supervised learning)(见图1)。CAMEL将图像(image)等距切分为更小的图像块(instance),在监督信息增强过程中自动为每一个块进行标注,进而将弱监督转化为有监督的问题。
CAMEL的有效性取决于监督信息增强后图像块标注的质量,为了提高标注的准确率,我们提出⼀种组合多实例学习(cMIL)的方法。在cMIL的训练过程中,我们需要找到图像中的代表图像块,其预测结果可以视为整张图像的分类标签(类比注意力机制)。在实际操作过程中,每一张图像被分成N×N个大小相等的块,同一张图像所对应图像块的集合被称为一个“图像包(bag)”。
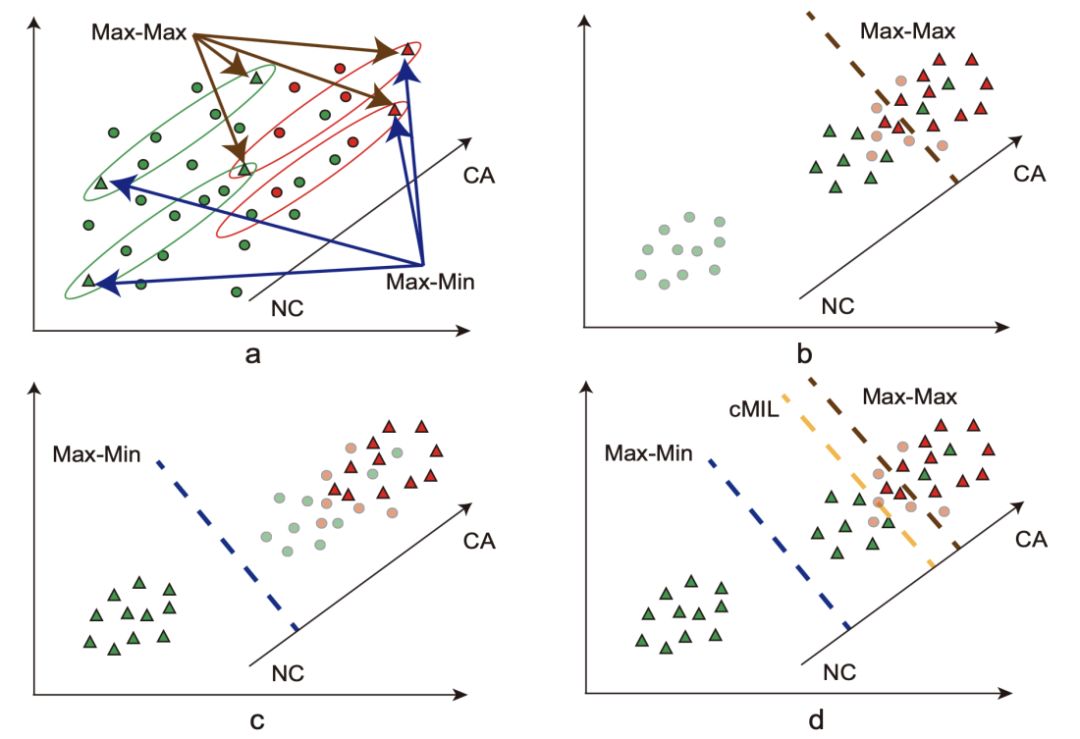
图2: Max-Max与Max-Min判据示意图,红色和绿色圆圈分别代表CA和NC图像块,这里我们使用三角形来表示选择出的图像块,每个椭圆代表一个图像包
如果一张图像中包含有癌变区域(CA),我们可以推断至少一个图像块包含有癌变区域。反之,若一张图像中没有癌变区域(NC),则所有的图像块均没有癌变。cMIL使用了两个不同的图像块选择判据(即Max-Max和Max-Min,见图2),如图3所示,在训练过程中,我们首先使用Max-Max(或Max-Min)从每个图像包中选择一个图像块,然后根据图像块的预测结果与图像的分类标签一起来计算成本函数。两种判据分别训练得到两个深度学习模型,我们将同一份训练数据分别送到两个模型中,并通过对应的判据选择出最有代表性的图像块(这里,我们排除了两个模型预测结果不同的图像块)。在本研究中,我们采用了ResNet-50作为图像块分类器,并使用交叉熵作为成本函数。
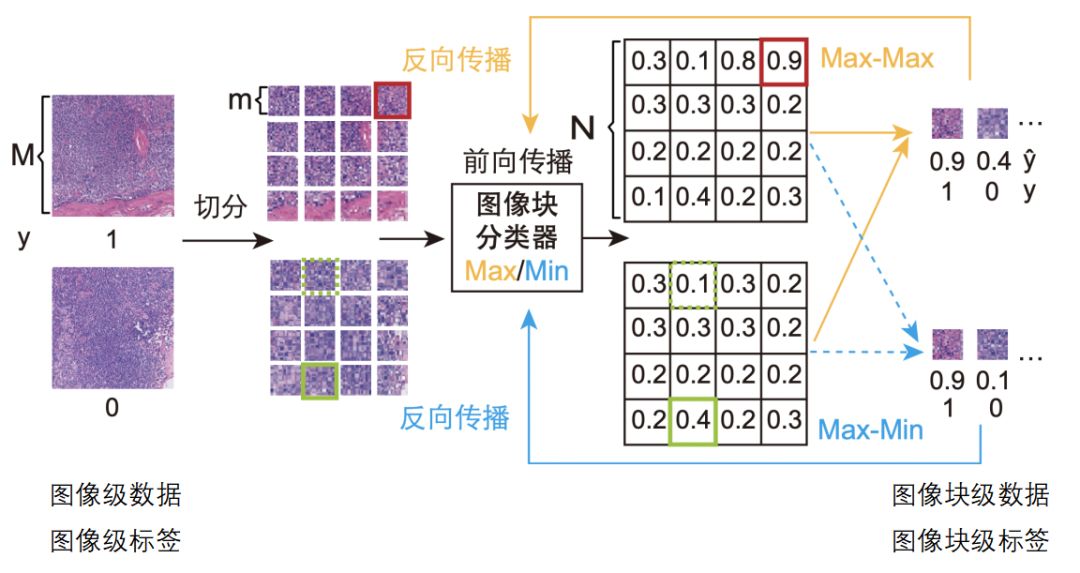
图3: cMIL的训练过程
最后,我们使用选择出的有标注图像块训练新的分类器,使用训练后的分类器对训练集的所有图像块进行预测。至此,我们将图像级的标注增强到了图像块级别,获得了N×N倍的有监督信息。
我们将图像块级别的标注直接赋给每一个像素点,便可以使用现有的图像分割模型,如DeepLab和U-Net,以有监督的方式训练像素级预测模型。
三、提升效果
为了更加充分的利用监督信息,我们提出了级联数据增强(cascade data enhancement)和图像级别约束(image-level constraint)两种方法,能够进一步提高模型的准确率。
获得比例因子为N的图像块数据,我们既可以使用cMIL(N),又可以使用cMIL(N1)和cMIL(N2)(其中N=N1×N2),级联数据增强方法通过两种方式来生成图像块标注数据。
在之前介绍的算法中,在使用增强信息后的图像块数据进行分类器训练的过程中,我们并没有使用图像级别的标签信息。为了将图像级监督信息引入到模型的训练过程中,我们可以在训练图像块级别分类模型时,将分类器的网络结构设置为与cMIL相同,并复用cMIL的训练框架,进而将图像级的分类数据作为另⼀个有监督信息源参与到训练过程中。
四、实验结果
CAMELYON16包含400张HE染色的乳腺淋巴结数字病理切片,我们将切片中200x视野1280×1280的影像作为图像级数据。CAMELYON16的训练集包含240张(110张包含CA)切片,对应5011张CA和96496张NC图像,我们对CA图像过采样以匹配NC图像的数量。此外,我们还构建了320×320和640×640两个完全有监督的训练数据集,以便与弱监督模型进行比较。测试集包括160张(49张包含CA)切片,可获得3392张CA图像,我们随机抽样了对应数目的NC图像。
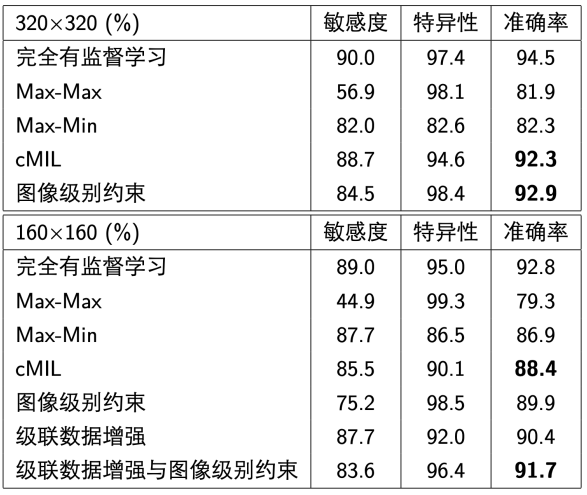
表1: 测试集上图像块监督信息增强效果
如表1和图4所示,Max-Max倾向于给出低敏感度高特异性的结果,Max-Min则恰好相反。结合二者所获得的数据,可以得到更加均衡的模型。可以看到,CAMEL获得的320×320和160×160图像块标注数据准确率仅比完全有监督模型低1.6%和1.1%。
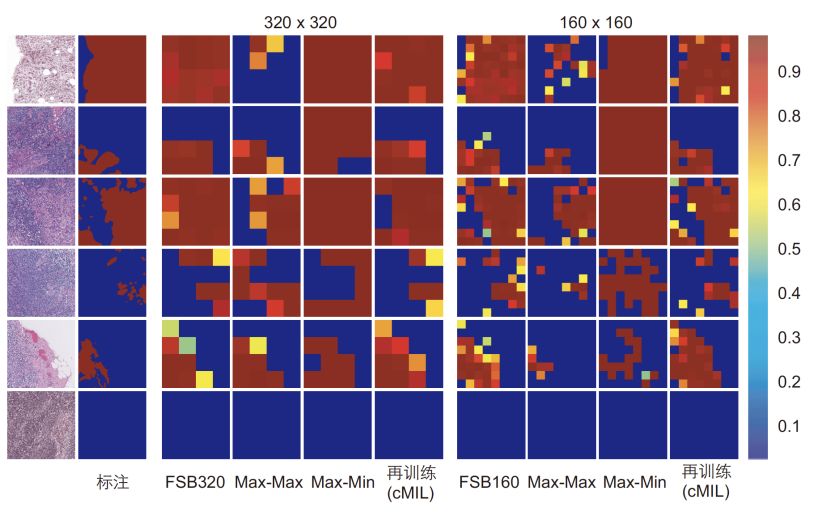
图4: 图像块分类结果,FSB代表完全有监督学习(fully supervised baseline)
我们测试了DeepLab v2(ResNet-34)和U-Net在图像分割上的表现,表2给出了不同模型的敏感度、特异性、准确率和交并比(intersection over union, IoU)。可以看到,CAMEL的效果远好于原始图像级标注,并接近完全有监督学习。
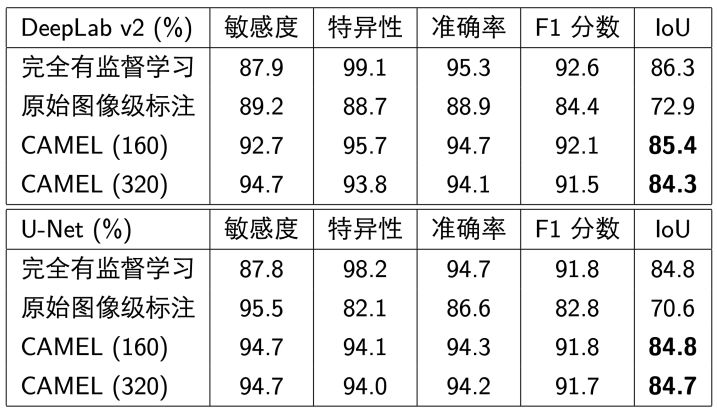
表2: 图像分割模型像素级准确率
使⽤160×160图像块所获得的模型准确率高于320×320(见图5),说明了监督信息增强方法的有效性。我们在图6给出了不同模型在切片级数据上的预测结果。

图5: CAMEL的像素级分割(DeepLab v2)结果
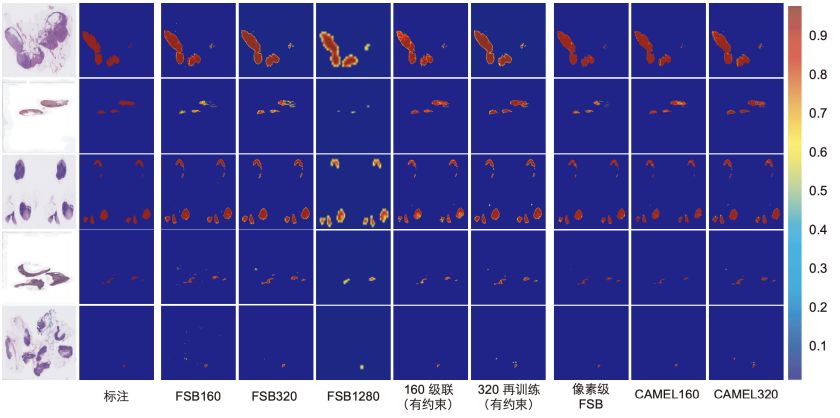
图6: 切片级图像块分类与像素级分割(DeepLab v2)结果
五、总结与展望
在本研究中,我们提出了仅使用图像级标签进行组织病理学图像分割的弱监督学习框架CAMEL,并获得了与有监督学习相当的模型准确率。CAMEL是一个通用的算法框架,同样适用于其他领域的相关应用。
CAMEL能够加速数字病理切片的标注过程,推进病理人工智能研究和落地的进程。人工智能病理辅助诊断系统可以帮助医生完成大部分简单、重复的工作,极大提高医生工作效率,减轻医生的工作负担。对于医疗资源较落后的地区,人工智能还可以提高当地的病理诊断水平。
【参考文献】
【作者介绍】
徐葳:清华大学交叉信息研究院副教授、助理院长、博士生导师,图灵人工智能研究院副院长,加州大学伯克利分校博士。
论文传送门
▼
扫描下方二维码,或点击文末“阅读原文”




