![]()
作者 | Uber AI Labs
编译 | MrBear
我们目前身处的人工智能浪潮在很大程度上是数据驱动的。在这个「数据为王」的时代,数据的壁垒为研究者们开展研究带来了大量的障碍。然而,
我们真的只有利用这些「真实」的数据才能训练出性能优秀的模型吗?
最近,来自 Uber 的研究人员提出了一种
生成式教学网络(GTN)
,可以通过生成非真实的训练数据,可以看下通过 GTN 生成的数字,基本没有一个是我们能够认得出来的:
把这些数据用在神经网络架构的搜索(NAS)上,
能够获得9倍的提速,且计算量下降几个数量级。
这项工作非常有意义,按照作者的说法,
“GTN开辟了一个新的研究方向”
;此外,GTN 并不仅仅适用于NAS,它是一种通用的工具,可以被用于机器学习的所有领域。
作者为此专门写了一篇解读博客,内容详实有趣,AI 科技评论翻译并稍作修改——
九倍提速
通过使用大量由人类标注的数据,我们推动了机器学习技术的发展,但是要制作出这种带标签的数据需要付出大量的时间和金钱。
在 Uber 人工智能实验室,我们研究了一个非常有趣的问题:是否可以创建一些学习算法,通过学习智能体所处的环境以及「课程」(curricula)自动地生成训练数据,从而帮助人工智能体迅速地学习呢?
对这个问题的回答,发表在我们最近的论文论文「Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data」(https://arxiv.org/abs/1912.07768)中。
![]()
我们通过
「生成式教学网络」(GTN)
实现这样的算法。
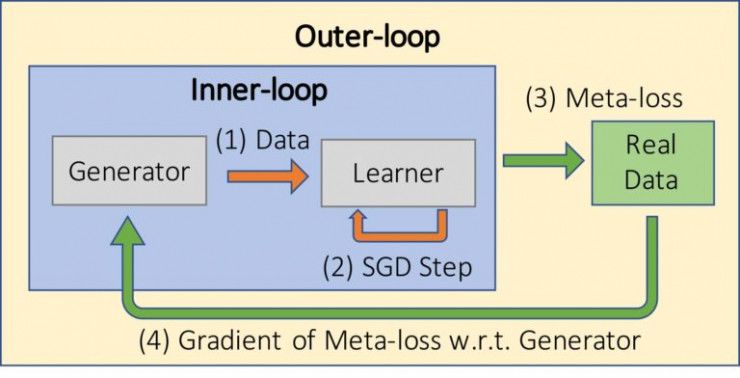
GTN 是一种深度神经网络,它能够生成数据或生成训练环境,学习器(例如,某种刚刚经过初始化的神经网络)在接受目标任务(例如,识别图中的物体)之前,可以使用 GTN 生成的数据或训练环境进行训练。
这种方法的一个优点是,
GTN 可以生成「合成」的数据
。其它的神经网络使用 GTN 生成的数据进行训练时,可以获得比在真实数据上进行训练更快的训练速度。这使我们能够以比使用真实数据训练快九倍的速度搜索新的神经网络架构。
基于 GTN 的神经网络架构搜索(GTN-NAS)可以与目前最先进的神经网络架构搜索(NAS)方法相媲美,它能够在使用比经典的 NAS 方法少几个数量级的计算量的情况下,获得目前最佳的性能。而且,实现这种最佳性能的新技术非常有趣!
神经网络的架构与它的一些设计选择有关(例如,它应该有多少层,每层应该有多少神经元,层与层之间应该具有怎样的连接关系,等等)。不断改进的神经网络架构使机器学习在诸多领域(例如,计算机视觉、自然语言处理、语音转文本)都取得了重大进展。然而,搜索高性能网络架构的任务通常是由科学家手动完成的,这极其耗时。
渐渐地,神经网络架构搜索(NAS,http://www.cs.ucf.edu/~kstanley/neat.html)算法被部署到自动化的架构搜索工作中,得到了很好的结果。尽管大量的人类科学家已经针对ImageNet 和 CIFAR 等流行的计算机视觉对比基准试图找到最佳的模型架构,但是 NAS 仍然得出了目前性能最佳的实验结果(https://arxiv.org/abs/1802.01548)。如果我们可以提升 NAS 的效率,那么整个机器学习社区中的从业人员都会大大受益。
NAS 需要大量的计算资源。朴素的 NAS 算法会使用完整的数据集训练每个神经网络,从而对其进行评估,直到模型性能不再提升。
对于数千个(甚至更多的)在 NAS 过程中需要考虑的网络架构重复这个过程的计算开销机器高昂,并且速度极慢。
NAS 算法通过仅仅进行少量时间的训练并且将得到的性能作为真实性能的估计值,避免了如此高昂的计算开销。
进一步加速这一过程的方法可能是:从完整的数据集中精心地选择信息量做大的训练样本。
论文「Learning Active Learning from Data」(https://arxiv.org/abs/1703.03365)中提到的方法已经被证明可以加速训练(该论文的主题超出了 NAS 的范畴)。
然而,我们想知道是否可以通过更激进的思路来加速这一过程:
让机器学习模型可以自己创建训练数据。
这种算法不仅仅局限于创建逼真的图像,相反,它也可以创建有助于学习的非真实数据,就像在篮球训练中我们学习同时运两个球可以加快学习速度(即使这与实际的比赛完全不一样)。因此,GTN 自由地创建非真实的数据,可以使得模型比使用个真实数据更快地学习。例如,GTN 可以融合许多不同类型的对象的信息,并且集中利用最困难的示例进行训练。
图1:生成式教学网络(GTN)示意图。生成器(一个深度神经网络)生成合成数据,一个新创建的学习器会使用这些数据进行训练。使用 GTN 生成的数据集进行训练后,该学习器可以在目标任务上取得很好的性能(尽管它们从未见过真实的数据)。
GTN 就好比生成对抗网络(GAN,http://papers.nips.cc/paper/5423-generative-adversarial-nets)中的生成器,只是它没有生成逼真数据的压力。
相反,它产生的是完全人造的数据,一个之前没有见到过的学习器神经网络(具有随机采样的架构和权值初始化结果)会使用这些数据训练少量的学习步(例如,可以通过随机梯度下降实现这些学习步)。
然后,我们会使用真实的数据评估学习器网络(到目前为止还没有见过真实的数据),例如评估该网络是否能识别经典 MNIST 数据集中的手写数字图像,该过程可以得到正在被优化的元损失目标函数(meta-loss objective)。
接着,我们通过元梯度(https://arxiv.org/abs/1502.03492)对整个学习过程进行微分,更新GTN 的参数,从而提高目标任务上的性能。之后,我们会弃用该学习器,并重复这个过程。另一个细节是,我们发现学习一个「课程」(一组按照特定顺序排列的训练示例)相较于训练一个生成无序随机示例分布的生成器更加能够提高模型性能。
GTN 涉及到了一种被称为
「元学习」
的令人激动的机器学习类型。在
这里,元学习被用于网络架构搜索。过去的研究者们(https://arxiv.org/abs/1502.03492)已经使用元学习直接(逐像素地)优化了「合成」数据。
在这里,通过训练一个生成器,我们可以重用更多的抽象信息(例如,关于数字「3」的形态特征)来编码各种各样的样本(例如,许多不同的「3」)。
我们进行的实验证明了,GTN 生成器比直接优化数据的性能更好。
更多关于 GTN 与之前相关工作比较的细节讨论,请参阅我们的论文。
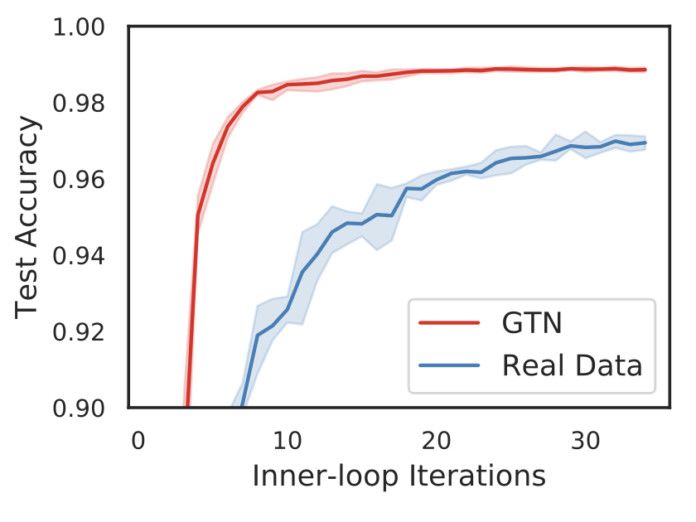
在对 GTN 进行元训练后,当学习仅限于少量的随机梯度下降学习步时(例如,32),新的学习器可以使用合成数据比使用真实数据学习得更快(如图 2 中红色的曲线代表使用合成数据,蓝色曲线代表使用真实数据)
图 2:使用 GTN 生成的合成数据进行训练比使用数据训练更快,当仅仅经过少量随机梯度下降步训练时,可以得到更高的 MNIST 性能。
在 MNIST 数据集上获得 98.9% 准确率本身并没有多么经验,但是能够使用这么少的样本做到的一点是:
使用 GTN 合成数据训练的学习器可以在仅仅 32 个随机梯度下降步(约 0.5 秒)的训练后达到这个水平
。同时,学习器仅仅在「课程」中「看」过了一次 4,096 个合成数据,这个数据规模还不到 MNIST 训练数据集的十分之一。
有趣的是,尽管我们可以使用这些合成图片训练神经网络,并且学着识别真正的手写数字,但
许多由 GTN 生成的图片实际上在我们人类看来是十分奇怪的,我们并不能将它们识别为数字,
如
图 3:
图 3:GTN 生成的具有「课程」性质的 MNIST 图像。课程的顺序从左到右排列(每一列是 32 批数据中的一批)。
这些非真实的图片可能对神经网络产生有意义的影响,这种现象反过来也会让人不禁想起深度神经网络很容易被「愚弄」(https://arxiv.org/abs/1412.1897)。同样非常有趣的是,在课程的末期,当模型性能达到平稳期之后,手写数字的可识别性会急剧提升(详见图 2 中的第 32 步)。关于「为什么图片大部分是非真实的」,以及「为什么在课程的末期它们的真实性会提升」的假设的讨论,请参阅我们的论文。
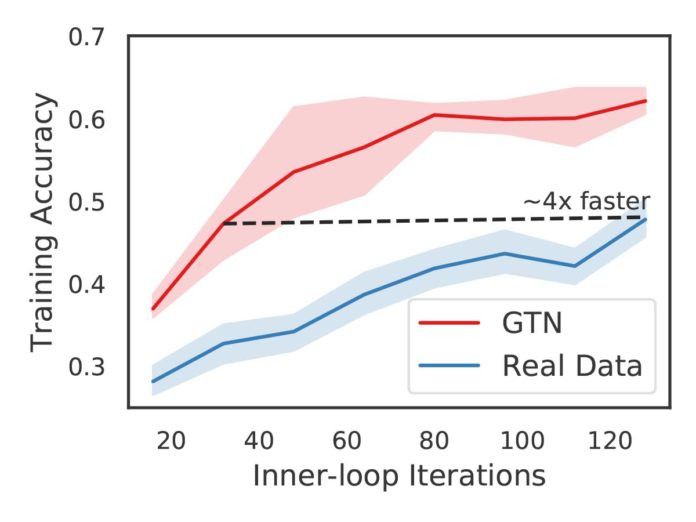
在确定 GTN 可以加速在 MNIST 数据集上的训练后,我们在 CIFAR-10 数据集上进行了测试,这同样也是一个常用的 NAS 对比基准。和在 MNIST 数据集上训练的情况相似,在这里,学习器使用 GTN 生成的数据学习的速率要快于使用真实数据学习的速率。具体而言,即使与高度优化的使用真实数据的学习算法相比,使用合成数据训练的学习器在性能水平相同的情况下,学习的速率也要比前者快四倍(详见图 4)。
图 4:在 CIFAR 数据集上,使用 GTN 生成的合成数据进行训练的速率比使用真实数据也更快一些,在性能水平相同的情况下,速率提升了 4 倍。
为了搜索网络架构,我们采用了来自许多论文(https://arxiv.org/abs/1611.01578,https://arxiv.org/abs/1802.03268,https://arxiv.org/abs/1808.07233)的思想。我们先搜索一个小型的架构模块,然后通过一个预先确定的「蓝图」重复组合这样的模块,从而创建不同规模的架构。一旦我们发现了一个高质量的模块,它就可以被用来创建一个更大的网络,然后用真实的数据训练这个网络,在目标任务上收敛。
在GTN-NAS中,
最终目标是找到一种经过在真实数据上训练许多步(即直到收敛)后,能够取得很好的性能表现的神经网络架构。
因此,测量在使用 GTN 生成的数据训练少量的学习步后得到的任何模型的性能,都只是一种估计当我们最终使用真实数据训练时,哪些架构会表现良好的手段。
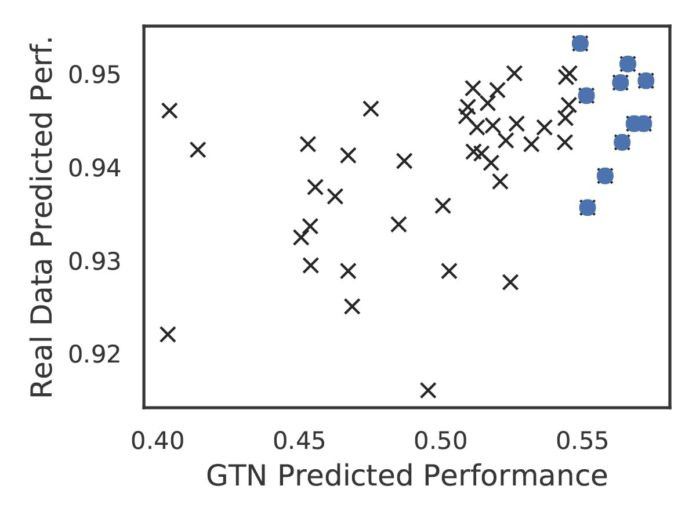
我们发现,使用 GTN 数据训练得到的模型性能可以被用来预测真实情况下的模型性能(使用 GTN 估计的排名前 50% 的架构与真实情况的 Spearman 等级相关系数为 0.56)。
例如,根据 GTN 非常快的估计,排名前 10% 的架构实际上性能非常高(详见图 5 中的蓝色方块)。
图 5:针对根据 GTN 估计得到的前 50% 的架构,使用 GTN 合成数据训练 30 秒后最终得到的性能与使用真实数据训练 4 小时后取得性能的相关系数图。图中的相关系数足够高(Spearman 等级相关系数为 0.5582),当我们选用根据 GTN 估计得到的性能最好的架构时,我们也会选择出真实性能最好的架构。根据 GTN 估计的结果,蓝色方块代表性能前 10% 的架构。
这意味着我们可以通过 GTN 生成的数据快速地评估许多网络架构,从而识别出一些看起来有潜力的架构,然后使用真实数据训练这些架构,最终确定哪些架构在目标任务上真正性能优异。
有趣的是,我们发现,
要实现与使用 GTN 生成的数据仅仅在 128 个随机梯度下降训练步上取得的相同的预测能力(等级相关系数),你需要使用真实数据训练 1,200 个梯度下降训练步。这说明,使用 GTN 生成的数据比使用真实数据进行网络架构搜索要快 9 倍!
因此,GTN 生成的数据在 NAS 算法中可以更快地替代真实数据。
为了说明该过程,我们选用了最简单的 NAS 方法:
随机搜索
。该算法非常简单,我们可以确定不存在复杂的算法组件和使用 GTN 生成的数据之间特殊的、令人困惑的相互作用。
在随机搜索过程中,该算法随机采样得到网络架构,并且在给定计算资源预算的情况下尽可能多地进行估计。在我们的实验中,这些估计要么是针对使用 GTN 生成的数据训练 128 个随机梯度下降训练步后的架构,要么是针对使用真实数据训练的架构。接着,对于每一种方法,根据估计得到的最佳架构会使用真实数据训练很长的时间。在真实数据上最终取得的性能才是我们真正关心的结果。
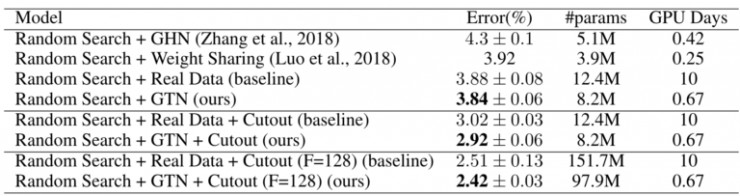
由于 GTN 能够更快地评估每个架构,它们能够在给定一定的计算资源的情况下,对更多整体框架进行估计。在我们实验的每一种情况下,我们都证明了:使用 GTN 生成的数据比使用真实数据更快,并取得了更好的性能(详见表 1)。甚至,当我们将使用真实数据训练 10 天的结果与使用 GTN 生成数据训练 2/3 天的结果进行比较时,这个结论也成立(详见表 1)。
表 1:GTN 可以直接替代真实数据,加速 NAS 的过程。在上表中,实验结果是使用简单的随机搜索 NAS 策略实现的,但是 GTN 应该也可以加速任意的 NAS 方法。参数的个数指的是学习器神经网络中权重的个数。
此外,采用随机搜索策略(以及表 1 中列出的一些附加功能)的 GTN-NAS 也可以与采用了比随机搜索复杂得多的策略的 NAS 方法相抗衡。重要的是,GTN 生成的数据也可以直接被这些算法使用,我们期望这将同时在这两种场景下取得最佳的效果,提升目前最佳模型的性能。
生成式教学网络(GTN)生成了合成数据,这种数据使新的学习器网络能够迅速地针对某种任务进行学习。
这使得研究者们可以快速地评估一种新提出的候选网络架构的学习潜力,这促进了对新的、更强大的神经网络架构的搜索。
通过我们的研究,我们说明了:GTN 生成的训练数据创建了一种更快的 NAS方法,它与目前最先进的 NAS 算法旗鼓相当(但实现的方式完全不同)。在我们的 NAS 工具箱中加入这种额外的 GTN 工具,对 Uber、所有的公司,以及全世界的所有科学家大有助益,可以帮助它们提升深度学习在每个应用领域的性能。
除了我们的直接成果,我们对
GTN 开辟的新的研究方向
也感到十分兴奋。当算法可以生成他们自己的问题和解决方案时,我们就可以解决比以前更难的问题。然而,生成问题需要定义一个环境搜索空间,这意味着我们需要编码一个丰富的环境空间来进行搜索。
GTN 有一种很好的特性,那就是它们可以生成几乎任意类型的数据或训练环境,这使其具有巨大的潜在影响力
。然而,虽然能够生成任意的环境令人十分激动,但仍然需要通过更多的研究充分利用这种表达能力,从而不会迷失在 GTN 产生的各种各样的可能性的海洋中。
从更宏观的角度来说,我们认为
GTN 是一种通用的工具,它可以被用于机器学习的所有领域。
我们这份工作中展示出了其潜力,但是我们也相信它们可以在无监督学习、半监督学习,以及强化学习中得到有效的应用(我们的论文已经得到了强化学习方面的初步结果)。
如果把目标定得更大一些,GTN 可以通过以下方式帮助我们朝着能够自动创建强大的人工智能形式的「人工智能生成算法」迈进:
本文说明了,GTN 有助于这三种方法中的第一种(对网络架构进行元学习),但它们也可以通过生成复杂的训练环境、成功地训练智能体,来促进第三个方面的发展(自动生成训练环境)。
更多细节,请参阅我们的论文。我们计划在未来几周内发布这项研究的源代码:敬请期待!
![]()
招 聘
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com