重磅开源! ICCV 2019,华为诺亚提出无需数据网络压缩技术

新智元专栏
【新智元导读】华为诺亚方舟实验室联合北京大学和悉尼大学,提出一种无需训练数据的网络压缩方法DAFL,并且达到了和需要数据的压缩算法类似的准确率。该论文已被 ICCV2019 接收。
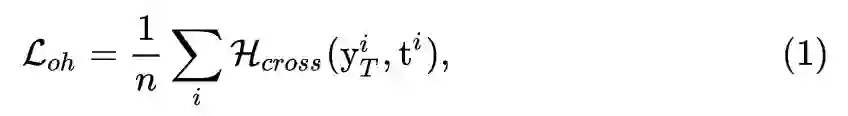
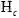 就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。
就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。
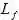 :
:

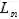 :
:
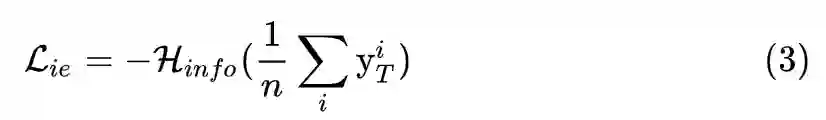
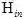 为标准的信息熵,信息熵的值越大,对于生成的一组样本来说,每个类别的数目就越平均,从而保证了生成样本的类别平均。
为标准的信息熵,信息熵的值越大,对于生成的一组样本来说,每个类别的数目就越平均,从而保证了生成样本的类别平均。
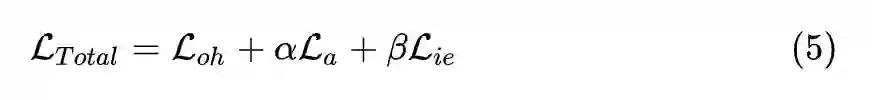
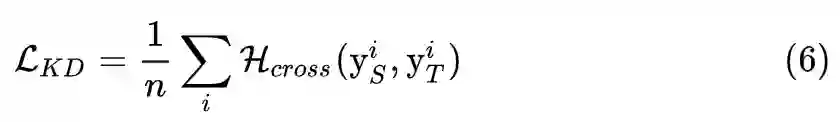


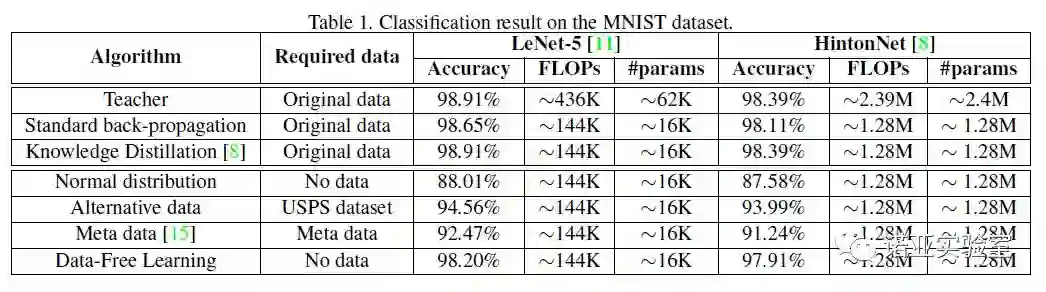
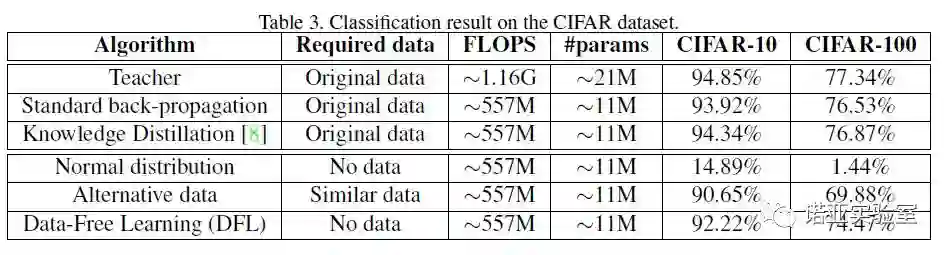
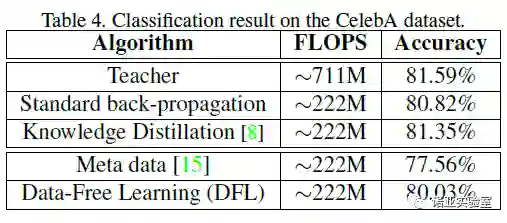



登录查看更多
相关内容
专知会员服务
26+阅读 · 2019年11月23日



相关VIP内容
专知会员服务
26+阅读 · 2019年11月23日
相关资讯
相关论文