【学界】大幅减少训练迭代次数,提高泛化能力:IBM提出「新版Dropout」
来源:机器之心
Dropout 可以提高深度神经网络的泛化能力,因此被广泛应用于各种 DNN 任务中。训练时,dropout 会通过随机忽略一部分神经元来防止过拟合。本文基于此提出了 multi-sample dropout,这种改进版的 dropout 既能加快训练速度,又能提高泛化能力。
Dropout (Hinton et al.[2012]) 是提高深度神经网络(DNN)泛化能力的主要正则化技术之一。由于其简单、高效的特点,传统 dropout 及其他类似技术广泛应用于当前的神经网络中。dropout 会在每轮训练中随机忽略(即 drop)50% 的神经元,以避免过拟合的发生。如此一来,神经元之间无法相互依赖,从而保证了神经网络的泛化能力。在推理过程中会用到所有的神经元,因此所有的信息都被保留;但输出值会乘 0.5,使平均值与训练时间一致。这种推理网络可以看作是训练过程中随机生成的多个子网络的集合。Dropout 的成功推动了许多技术的发展,这些技术使用各种方法来选择要忽略的信息。例如,DropConnect (Wan et al. [2013]) 随机忽略神经元之间的部分连接,而不是神经元。
本文阐述的也是一种 dropout 技术的变形——multi-sample dropout。传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失。这种方法只要在 dropout 层后复制部分训练网络,并在这些复制的全连接层之间共享权重就可以了,无需新运算符。
通过综合 M 个 dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复训练 M 次。因此,它大大减少了训练迭代次数。
实验结果表明,在基于 ImageNet、CIFAR-10、CIFAR-100 和 SVHN 数据集的图像分类任务中,使用 multi-sample dropout 可以大大减少训练迭代次数,从而大幅加快训练速度。因为大部分运算发生在 dropout 层之前的卷积层中,Multi-sample dropout 并不会重复这些计算,所以对每次迭代的计算成本影响不大。实验表明,multi-sample dropout 还可以降低训练集和验证集的错误率和损失。
Multi-Sample Dropout
图 1 是一个简单的 multi-sample dropout 实例,这个实例使用了 2 个 dropout 样本。该实例中只使用了现有的深度学习框架和常见的操作符。如图所示,每个 dropout 样本都复制了原网络中 dropout 层和 dropout 后的几层,图中实例复制了「dropout」、「fully connected」和「softmax + loss func」层。在 dropout 层中,每个 dropout 样本使用不同的掩码来使其神经元子集不同,但复制的全连接层之间会共享参数(即连接权重),然后利用相同的损失函数,如交叉熵,计算每个 dropout 样本的损失,并对所有 dropout 样本的损失值进行平均,就可以得到最终的损失值。该方法以最后的损失值作为优化训练的目标函数,以最后一个全连接层输出中的最大值的类标签作为预测标签。当 dropout 应用于网络尾段时,由于重复操作而增加的训练时间并不多。值得注意的是,multi-sample dropout 中 dropout 样本的数量可以是任意的,而图 1 中展示了有两个 dropout 样本的实例。
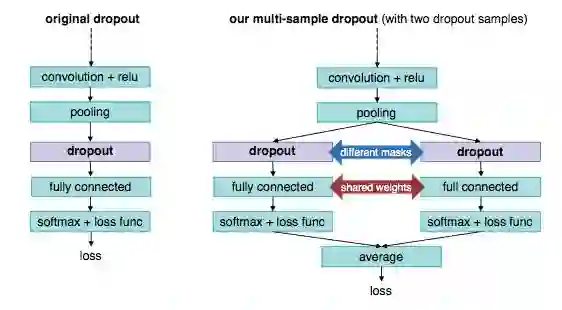
图 1:传统 dropout(左)与 multi-sample dropout(右)
神经元在推理过程中是不会被忽略的。只计算一个 dropout 样本的损失是因为 dropout 样本在推理时是一样的,这样做可以对网络进行修剪以消除冗余计算。要注意的是,在推理时使用所有的 dropout 样本并不会严重影响预测性能,只是稍微增加了推理时间的计算成本。
为什么 Multi-Sample Dropout 可以加速训练
直观来说,带有 M 个 dropout 样本的 multi-sample dropout 的效果类似于通过复制 minibatch 中每个样本 M 次来将这个 minibatch 扩大 M 倍。例如,如果一个 minibatch 由两个数据样本(A, B)组成,使用有 2 个 dropout 样本的 multi-sample dropout 就如同使用传统 dropout 加一个由(A, A, B, B)组成的 minibatch 一样。其中 dropout 对 minibatch 中的每个样本应用不同的掩码。通过复制样本来增大 minibatch 使得计算时间增加了近 M 倍,这也使得这种方式并没有多少实际意义。相比之下,multi-sample dropout 只重复了 dropout 后的操作,所以在不显著增加计算成本的情况下也可以获得相似的收益。由于激活函数的非线性,传统方法(增大版 minibatch 与传统 dropout 的组合)和 multi-sample dropout 可能不会给出完全相同的结果。然而,如实验结果所示,迭代次数的减少还是显示出了 multi-sample dropout 的加速效果。
实验
Multi-Sample Dropout 带来的改进
图 2 展示了三种情况下(传统 dropout、multi-sample dropout 和不使用 dropout 进行训练)的训练损失和验证集误差随训练时间的变化趋势。本例中 multi-sample dropout 使用了 8 个 dropout 样本。从图中可以看出,对于所有数据集来说,multi-sample dropout 比传统 dropout 更快。
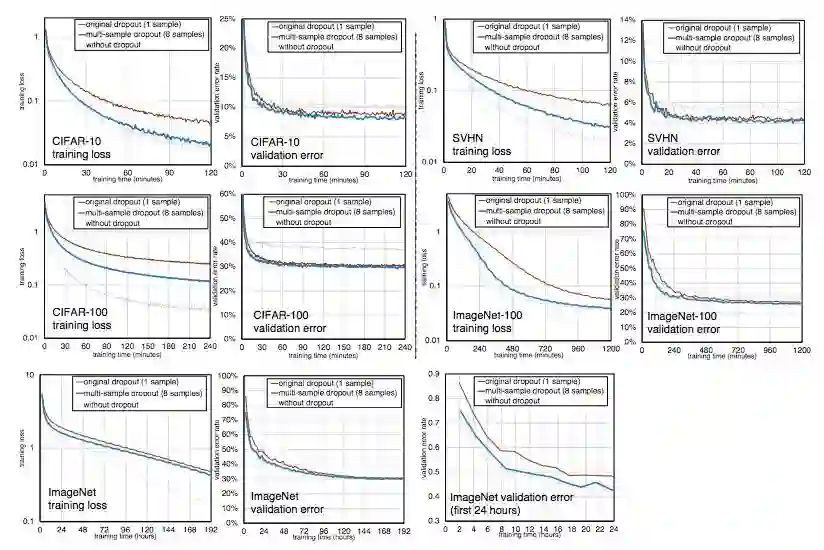
图 2:传统 dropout 和 multi-sample dropout 的训练集损失和验证集误差随训练时间的变化趋势。multi-sample dropout 展现了更快的训练速度和更低的错误率。
表 1 总结了最终的训练集损失、训练集错误率和验证集错误率。
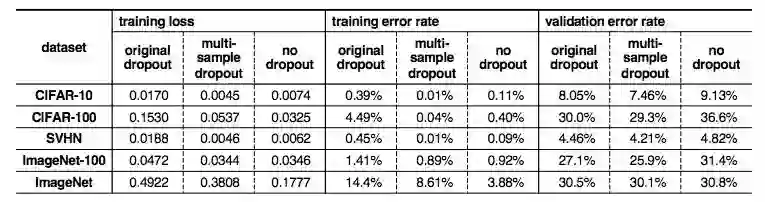
表 1:传统 dropout 和 multi-sample dropout 的训练集损失、训练集错误率和验证集错误率。multi-sample dropou 与传统 dropout 相比有更低的损失和错误率。
参数对性能的影响
图 3 (a) 和图 3 (b) 比较了不同数量 dropout 样本和不同的 epoch 下在 CIFAR-100 上的训练集损失和验证集误差。使用更多的 dropout 样本加快了训练的进度。当 dropout 样本多达 64 个时,dropout 样本的数量与训练损失的加速之间显现出明显的关系。对于图 3(b) 所示的验证集误差,dropout 样本在大于 8 个时,再增加 dropout 样本数量不再能带来显著的收益。
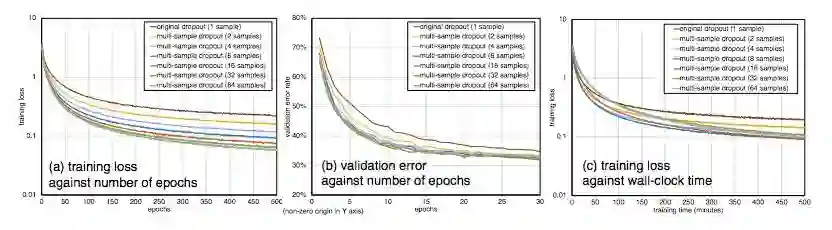
图 3:不同数量的 dropout 样本在训练过程中的训练集损失和验证集误差。
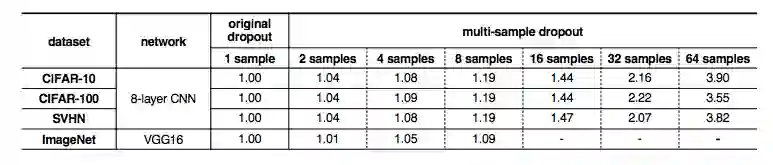
表 2:不同 dropout 样本数量下与传统 dropout 的迭代时间比较。增加 dropout 样本的数量会增加迭代时间。由于内存不足,无法执行有 16 个 dropout 示例的 VGG16。
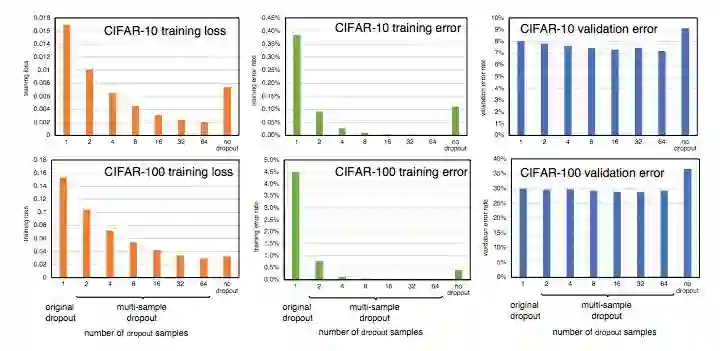
图 4:不同数量的 dropout 样本训练后的损失和错误率。
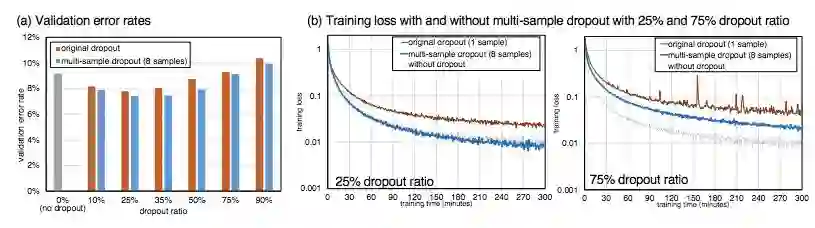
图 5:(a) 验证错误率,(b) 不同 dropout 率下的 multi-sample dropout 和传统 dropout 的训练损失趋势。其中 35% 的 dropout 率表示两个 dropout 层分别使用 40% 和 30%。
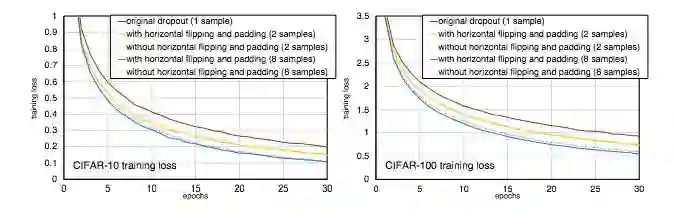
图 6:有水平翻转(增加 dropout 样本多样性)和没有水平翻转时训练损失的比较。x 轴表示 epoch 数。
为什么 multi-sample dropout 很高效
如前所述,dropout 样本数为 M 的 multi-sample dropout 性能类似于通过复制 minibatch 中的每个样本 M 次来将 minibatch 的大小扩大 M 倍。这也是 multi-sample dropout 可以加速训练的主要原因。图 7 可以说明这一点。
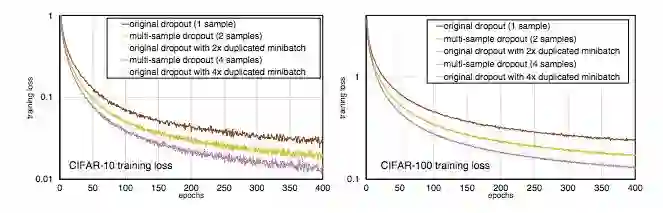
图 7:传统 dropout 加数据复制后的 minibatch 与 multi-sample dropout 的比较。x 轴表示 epoch 数。为了公平的比较,研究者在 multi-sample dropout 中没有使用会增加样本多样性的横向翻转和零填充。

论文链接:https://arxiv.org/pdf/1905.09788.pdf
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得

