谷歌发布TensorFlowLite,用半监督跨平台快速训练ML模型!

谷歌刚刚宣布推出 TensorFlow Lite,这是 TensorFlow 的针对移动设备和嵌入式设备的轻量级解决方案。这个框架针对机器学习模型的低延迟推理进行了优化,重点是小内存占用和快速性能。作为库的一部分,谷歌还发布了一个设备上会话模型(on-device conversational model)和一个用于 demo 的 app,它提供了一个由 TensorFlow Lite 驱动的自然语言应用程序的示例,以便让开发人员和研究人员更容易地构建基于设备上推理(on-device inference)的新机器智能特征。这个模型能够在输入会话聊天信息时生成回复建议,通过有效的推理,可以很容易地插入到聊天应用程序中,从而为设备上会话智能提供动力。

谷歌发布的设备上会话模型使用了一种新的ML架构,用于训练紧凑的神经网络(以及其他机器学习模型),它基于一个联合优化的框架,最初是在 ProjectionNet 的论文中提出的(参考:ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections)。这个架构可以在具有有限计算能力和内存的移动设备上高效地运行,通过使用有效的“投影”(projection)操作,将任何输入转换为紧凑的位向量(bit vector)表示——类似的输入被投影到邻近的向量上,这些向量或密集,或稀疏,取决于投影的类型。例如,“嘿,你好吗?”(hey, how's it going?)”和“老兄,最近怎么样?”(How's it going buddy?),这两个消息可能被投影到相同的向量表示。
在这个想法下,会话模型在低计算力和内存占用的情况下将这些操作高效地结合起来。谷歌使用一个ML框架对这个设备上的模型进行了端到端的训练,这个框架联合训练两种类型的模型——一个紧凑的 projection 模型(如前文所述)和一个 trainer 模型。这两个模型采用联合的方式进行训练, projection 模型从 trainer 模型中学习—— trainer 具有专家的特征,并且使用更大、更复杂的ML架构进行建模,而projection 模型就像一个从专家那里学习的学生。在训练过程中,还可以利用量化(quantization) 或“蒸馏”(distillation)等其他技术,从而进一步压缩或选择性地优化目标函数的某些部分。训练完毕后,较小的 projection 模型就可以直接用于设备上的推理。
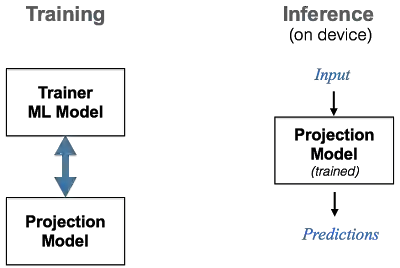
对于推理,训练的 projection 模型被编译成一组 TensorFlow Lite 操作,这些操作经过优化,可以在移动平台上快速执行,并直接在设备上执行。下图是用于设备上会话模型的 TensorFlow Lite 推理图。
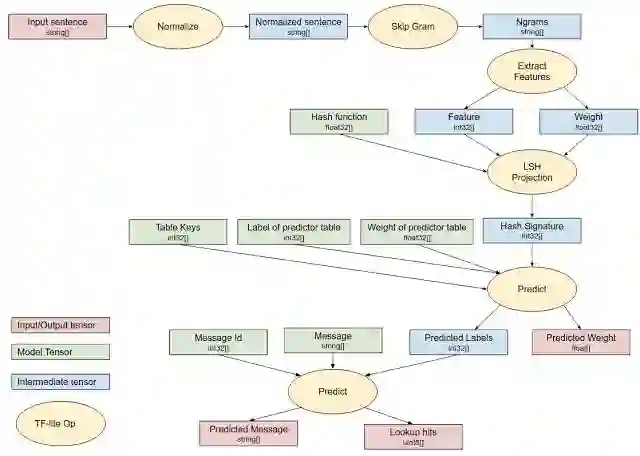
设备上会话模型的 TensorFlow Lite 执行
发布的开源对话模型(连同代码)都是使用上面描述的联合ML架构来进行端到端训练的。今天的发布还包括一个demo应用,你可以很容易地下载并在你的移动设备上试用一键智能回复。这个架构支持基于应用程序需求配置模型大小和预测质量。在GitHub库上我们提供了一个示例消息列表。系统还可以从聊天对话中观察到的流行回复意图中学习并编译的固定集的回复。其底层的模式与谷歌在其应用中使用的智能回复响应不同。
一、对话模型之外
上面描述的ML架构允许灵活选择底层模型。我们还设计了与不同机器学习方法兼容的架构——例如,当使用TensorFlow深度学习时,我们学习了一个用于底层模型的轻量级的神经网络(ProjectionNet),而不同的架构(ProjectionGraph)则使用图形框架代替神经网络来表示模型。
这个联合的框架还可以用来为其他任务使用不同的ML建模架构来训练轻量级的设备上模型。比如,我们推导出了一个 ProjectionNet 架构,该架构使用一个复杂的前馈或循环的架构(如LSTM),并结合一个由动态投影操作和几个窄的完全连接层组成的简单 projection 架构。整个架构都是在 TensorFlow 中使用反向传播进行端到端的训练。训练完成后,就可以直接使用紧凑的 ProjectionNet 进行推理。使用这种方法,我们已经成功地训练了小型的 ProjectionNet 模型,它可以显著地减小模型大小(最大能够减小几个数量级),并且在多个视觉和语言的分类任务上的准确性方面表现出色。类似地,我们使用图形学习框架训练其他的轻量级模型,即使是在半监督的设置下也如此。
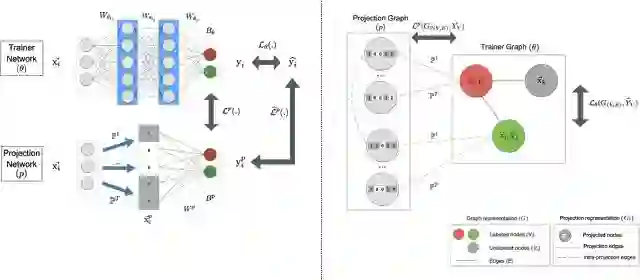
用于训练设备上模型的ML架构:使用深度学习训练的ProjectionNet(左)和使用图形学习训练的ProjectionGraph(右)
我们将继续改进并发布最新的 TensorFlow Lite 模型。我们认为,使用这些ML架构学习的现有模型(以及将来发布的模型)可以重复用于许多自然语言处理和计算机视觉的应用程序,或者插入到现有的应用程序中,以实现机器智能。我们希望机器学习和自然语言处理社区能够在这些基础上更进一步,解决新的问题并提出我们尚未想到的用例。
二、TensorFlow Lite 特征、架构、模型
今天,我们很高兴地宣布TensorFlow Lite的开发人员预览版,这是 TensorFlow 针对移动和嵌入式设备的轻量版解决方案! TensorFlow一直运行在许多平台上,从服务器机架到小型物联网设备。但随着过去几年机器学习模型的采用呈指数级增长,因此需要将其部署在移动和嵌入式设备上。 TensorFlow Lite能够对设备上的机器学习模型进行低延迟推断。
(一)TensorFlow Lite具有以下特征:
轻量使设备上机器学习模型推断具有小型二进制规模和快速初始化/启动。
跨平台:可以在多个平台运行,包括安卓和iOS。
快速:针对移动设备进行了快速优化,包括模型加载时间显著加快,并支持硬件加速等。
越来越多的移动设备采用专用的定制硬件来更有效地处理机器学习工作负载。TensorFlow Lite支持安卓神经网络API,以充分利用这些新的加速器。当加速器硬件不可用时,TensorFlow Lite会回退到优化的CPU执行状态,从而确保模型仍然可以在大量设备上快速运行。
(二)TensorFlow Lite的架构:下图展示了TensorFlow Lite的架构设计

组成部分如下
TensorFlow模型:保存在磁盘上经过训练的TensorFlow模型。
TensorFlow Lite转换器:是一个将模型转换为TensorFlow Lite文件格式的程序。
TensorFlow Lite模型文件:基于FlatBuffers的模型文件格式,已经过速度和大小优化。
TensorFlow Lite模型文件被应用在移动应用程序中:
Java API:在安卓平台上围绕着C++ API的包裹器。
C++ API:加载TensorFlow Lite模型文件并调用Interpreter。安卓和iOS上有同样的库。
Interpreter:使用一组operator来执行模型。Interprete支持选择性操作员加载。没有operator的情况下,只有70KB,加载了所有operator,有300KB。这比TensorFlow Mobile所要求的1.5M的明显降低。
在选定的安卓设备上,Interpreter将使用安卓神经网络API实现硬件加速。若无可用,则默认为CPU执行。
开发人员也可以使用C++ API实现定制内核。
(三)TensorFlow Lite的模型 :已支持许多经过训练和优化的模型
MobileNet:一类视觉模型,能够识别1000个不同的对象类别,专门为移动和嵌入式设备上的高效执行而设计。
Inception v3:图像识别模型,功能与MobileNet类似,提供更高的准确性,但更大。
Smart Reply:一种设备上的会话模型,可以对流入的对话聊天消息进行一键式回复。第一方和第三方消息传递应用在Android Wear上使用此功能。
Inception v3和MobileNets已经在ImageNet数据集上训练。你可以通过迁移学习,在自己的图像数据集上重新训练。
模型地址:
download.tensorflow.org/models/tflite/smartreply_1.0_2017_11_01.zip
代码地址:https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/models/smartreply
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!