学界 | CMU&FAIR ICCV论文:通过传递不变性实现自监督视觉表征学习
选自arXiv
机器之心编译
参与:路雪、黄小天
通过自监督学习学习视觉表征在计算机视觉领域逐渐开始流行。本文提出可通过不变性的传递实现视觉表征自监督学习,该网络在多种识别任务中均表现不俗,在表面正常评估任务中的表现甚至优于 ImageNet 网络。
论文:Transitive Invariance for Self-supervised Visual Representation Learning

论文地址:https://arxiv.org/abs/1708.02901
通过自监督学习学习视觉表征在计算机视觉领域逐渐开始流行。该方法是为了设计可随意获取标签的辅助任务。大多数辅助任务最终将提供数据来学习特定种类的有助于识别的不变性(invariance)。在本论文中,我们提出利用不同的自监督方法学习表征,这些表征与 (i) 实例间变体(inter-instance variation,相同类别的两个对象应该具备相似的特征)、(ii) 实例内变体(intra-instance variation,视角、姿势、变形、亮度等)无关。我们没有将这两种方法与多任务学习联结起来,而是组织和推理具备多种不变性的数据。具体来说,我们提出使用从成百上千个视频中挖掘出的数百万个对象生成一个图。这些对象由分别对应两种不变性的两种边缘(edge)联结起来:「具备相似的观点和类别的不同实例」和「相同实例的不同观点」。通过将简单的传递性(transitivity)应用到带有这些边缘的图上,我们能够获取具备更加丰富视觉不变性的成对图像。我们使用这些数据训练带有 VGG16 的 Triplet-Siamese 网络作为基础架构,将学得的表征应用到不同的识别任务中。关于物体检测,我们使用 Fast R-CNN 在 PASCAL VOC 2007 数据集上达到了 63.2% mAP(ImageNet 的预训练结果是 67.3%)。而对于有难度的 COCO 数据集,使用我们的方法得出的结果(23.5%)与 ImageNet-监督的结果(24.4%)惊人地接近。我们还证明了我们的网络在表面正常评估(surface normal estimation)任务中的表现优于 ImageNet 网络。
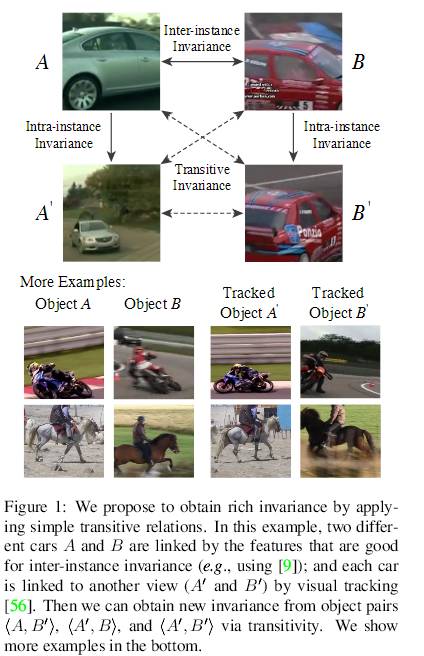
图 1:我们提出使用简单的传递关系获取丰富的不变性。在该示例中,两辆不同的汽车 A 和 B 被有利于实例间不变性的特征联结起来;每辆车通过视觉追踪与另一个视角(A′和 B′)联系起来。之后,我们能够借助传递性从物体对〈A, B′〉、〈A′, B〉和〈A′, B′〉中获取新的不变性。
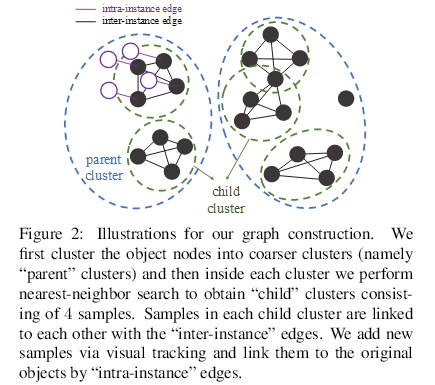
图 2:图构建描述。我们首先将物体节点聚集到更加粗糙的集群(叫作「父」集群),然后我们在每个集群内执行最近邻搜索(nearest-neighbor search)来得到包含 4 个样本的「子」集群。每个子集群内的样本通过「实例内」边缘互相联结。我们通过视觉追踪增加新样本,并通过「实例间」边缘将其与原始物体联结起来。

图 5:训练网络所用样本。每一列是一系列图像块 {A, B, A′, B′}。这里,A 和 B 通过实例间边缘联结,而 A′/B′与 A/B 通过实例内边缘联结。
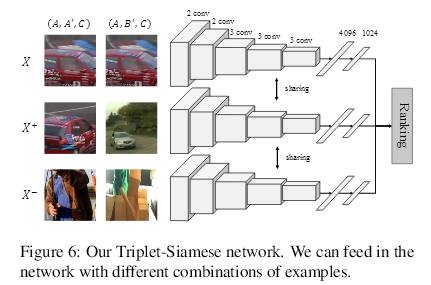
图 6:我们的 Triplet-Siamese 网络。我们向该网络输入样本的不同联结。

图 7:PASCAL VOC 数据集上的最近邻搜索。我们抽取三种特征:(a)语境预测网络,(b)使用我们的自监督方法训练的网络,(c)标注 ImageNet 数据集中预训练的网络。我们证明我们的网络可以展示出相同类别物体的更多种类(如视角)。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


