挖掘极致,将head数设置为特征数,Meta AI多头高效注意力模块更准、更快
机器之心报道
研究者表示,他们提出的多头高效注意力 Hydra Attention 保留了注意力的可解释性等优点,能够同时提升基线 DeiT-B 模型的准确率和速度。
得益于自身的泛化性以及从大规模数据中学习的能力,Transformers 成为过去几年自然语言处理领域的主导技术。并且随着 Vision Transformers(ViTs)的出现,视觉领域也出现了类似的趋势。但我们应该看到,在 NLP 中使用 BERT 或在视觉中使用 ViT 得到的 Transformers 纯实例化并不是计算机视觉任务的主导。相反,更多基于 vision-specialized 注意力的架构(如 Swin 或 MViT)或注意力 - 卷积混合架构(如 LeViT)正在被使用。
究其原因,specialized ViT 可以通过更少算力实现更好的性能,它们要么添加卷积层、要么使用 vision-specific 局部窗口注意力,要么使用其他方式低成本地添加视觉归纳偏置。虽然纯 ViTs 在大型数据集上表现良好(如 ImageNet 上取得 90.45% top-1),但是当我们在多个下游任务所需的大图像上应用一个模型时,纯 Transformers 的主要机制(即多头自注意力)可能面临很大的瓶颈。
NLP 领域已经引入很多技术来解决这一问题。一些工作或通过「内核技巧」重新安排计算顺序或通过映射到与 token 无关的低秩空间或二者兼而有之,来引入线性注意力(就 token 而言)。但是,这些线性注意力方法中的大多数将跨 token 的计算转换成跨特征的计算,导致成本很高。最近,Flash Attention 已经展示了多头自注意力的 IO 高效实现优于大多数线性注意力方法,即便 token 数量 dadao 数千也是如此。
此外也有工作在视觉空间中尝试使用高效注意力,但还没有人在传统的 ViT shell 中单独进行探索。举例而言,PolyNL 将注意力视为高效的三阶多项式,但尚未在 ViT 架构中探索。Attention Free Transformer 提出一个同样高效的 AFTSimple 变体,但在纯 ViT 中表现不佳且需要卷积和位置编码的额外支持。因此我们亟需一个真正高效、准确率高且泛化性强的多头自注意力。
近日, Meta AI 和佐治亚理工学院的研究者填补了这一空白,提出了 Hydra Attention。该方法源于线性注意力中有些自相矛盾的行为,即在使用标准多头自注意力时,向模型中添加更多的 head 会保持计算量不变。但是,在线性注意力中改变操作顺序后,添加更多的 head 实际上降低了层的计算成本。
因此,研究者将这一观察结果发挥到了极致,将模型中 head 的数量设置为与特征数相同,从而创建了一个在计算上对于 token 和特征都呈线性的注意力模块。

论文地址:https://arxiv.org/pdf/2209.07484.pdf
下图为标准注意力、线性注意力和 Hydra Attention 的结构比较。
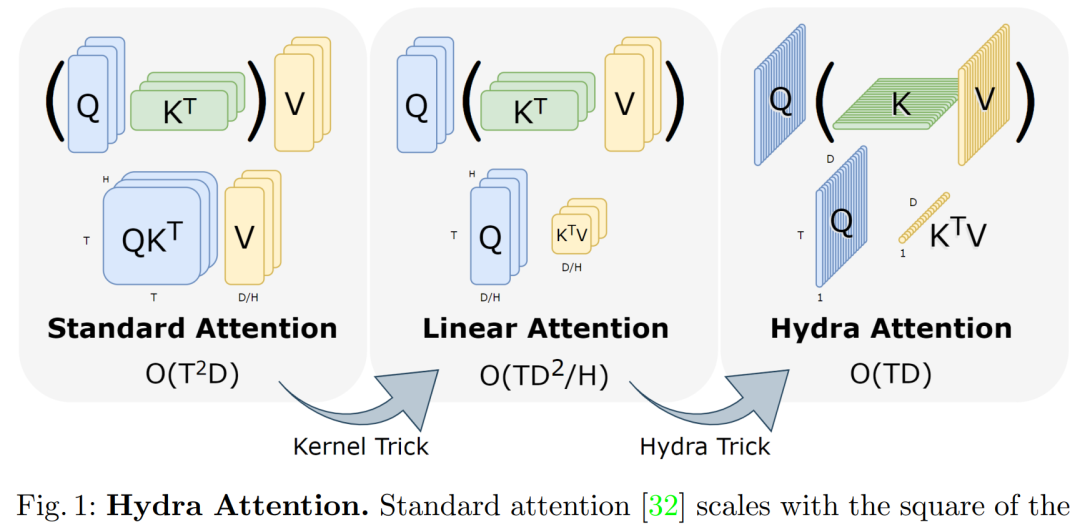
Hydra Attention 不仅比先前高效注意力工作的泛化性更强,而且在使用正确的内核时能够显著提升准确率。事实上,当与标准多头注意力混合时,Hydra Attention 可以提高基线 DeiT-B 模型的准确率同时速度也更快。由于源自多头注意力,Hydra Attention 保留了注意力的几个优点,比如可解释性以及对不同任务的泛化性。
然而,虽然 Hydra Attention 对于大图像高效且泛化强,但在本文中只关注使用 DeiT-B 的 ImageNet 分类任务,通常只使用较小的 224×224 和 384×384 图像。虽然对于这些图像的效率提升不是太大(根据图像大小不同可以实现 10-27% 的提升),但其他高效注意力方法遭受较大的准确率下降,Hydra Attention 则没有。
未来,研究者希望可以探索在其他更多 token 密集领域中的应用,比如检测、分割或视频。作为一种通用技术,Hydra attention 不对 token 之间的关系做任何假设,因而可以进一步用来提升 token 稀疏应用的速度,比如掩码预训练或 token 剪枝。
研究者还希望 Hydra Attention 可以为更强大、更高效、更通用的纯 transformers 模型打下基础。
Hydra Attention
在标准的多头自注意力中,其计算量随图像中 token 的数量呈二次增长。更具体地说,如果 T 是 token 数量,D 是特征维度数量,那么形成的注意力矩阵是 O(T^2D)的。当 T 很大时,这种操作在计算上变得不可行。
因此开始有研究者引入线性注意力。给定查询 Q、键 K、值 V 等,标准 softmax 自注意力计算为:
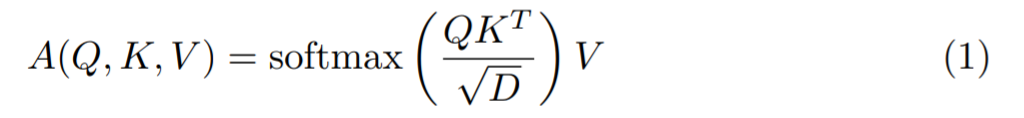
根据文献 [16] 的研究,公式(1)还可以用 sim(·)函数写成这样:
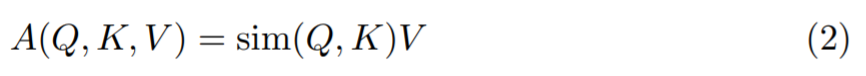
如果选择一个特征表示为ϕ(·)的可分解内核,那么 sim(x, y) = ϕ(x)ϕ(y)^T,又可以得到:
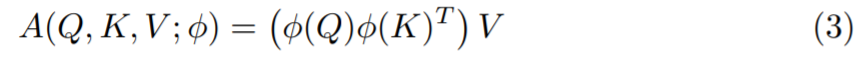
然后通过结合律,改变计算顺序,最终得到:
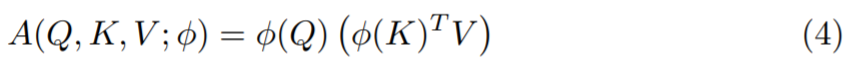
多头注意力
然而公式(1)到(4)为假设为单头注意力。想要多头注意力,则(1)应变为:
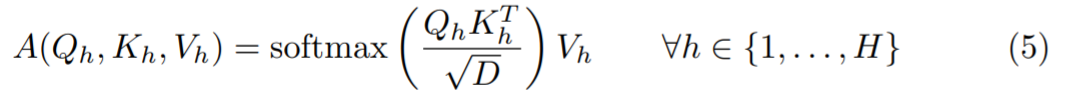
公式(4)变为:
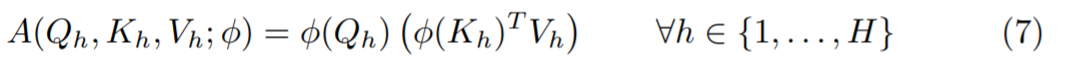
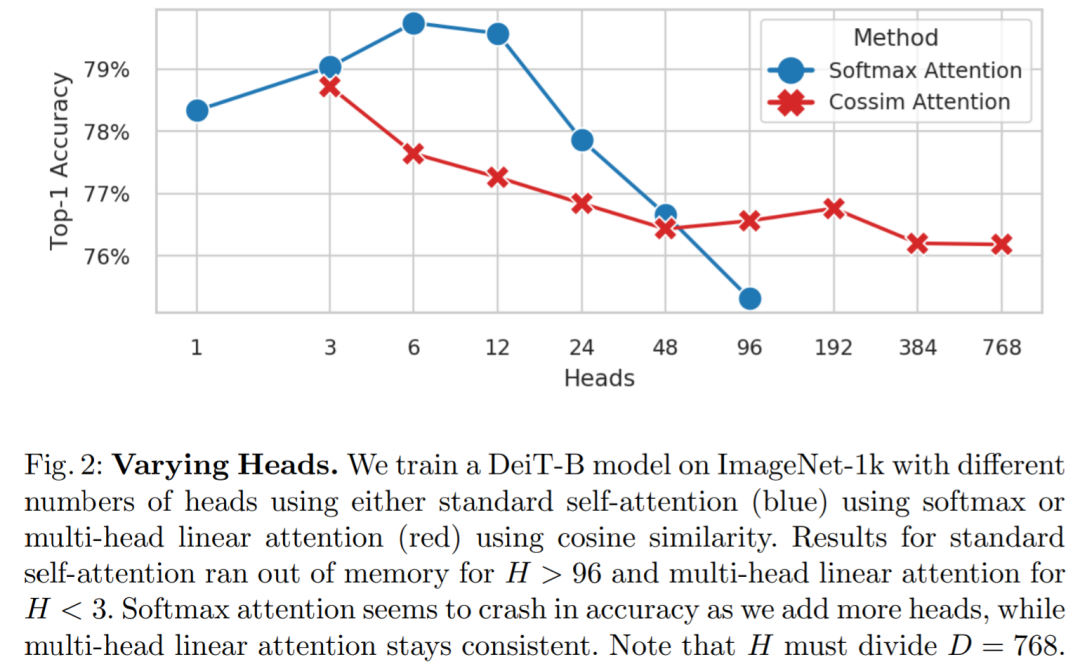
到底增加多少头合适呢?大多数的研究使用 6 到 16 个头,但头的数量超过这个范围,会发生什么?
为了找出答案,该研究在 ImageNet-1k 上训练 DeiT-B ,并使用带有 softmax 的标准多头自注意力(公式 5,MSA)或带有余弦相似度的多头线性注意力来改变头数 H (公式 7, MLA) 进行实验,结果绘制在图 2 中。在内存使用方面,MSA 在 H > 96 时内存不足,而 MLA 在 H < 3 时内存不足。
在性能方面,对于 MSA,当 H > 12 时,Softmax 注意力的准确率似乎会崩溃,而具有余弦相似度的 MLA 的准确率基本保持一致,直到 H=768。令人惊讶的是,处于这个头数时,H 等于 D,这意味着每个头只有一个标量特征可以使用!
hydra
如图 2 所示,只要相似度函数 sim(x, y)不是 softmax,H 任意放大都是可行的。为了利用这一点,该研究引入了 hydra ,即设置 H = D:
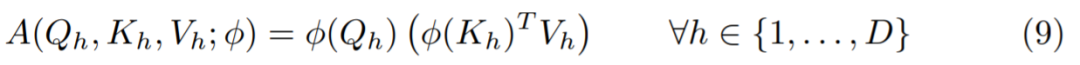
在这种情况下,每个 Q_h、K_h、V_h 都是 R^T ×1 中的列向量,然后得到:
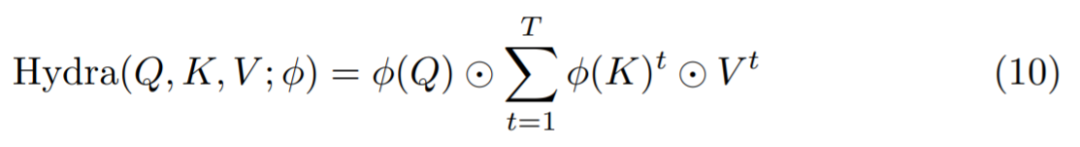
Hydra Attention 通过一个全局瓶颈混合信息,而不是像标准的自注意力那样进行显式的 token-to-token 混合。这导致计算复杂度为:

实验结果
对于所有实验,除非另有说明,该研究使用 DeiT-B,并在 ImageNet-1k 上进行默认设置训练。
在表 1 中,该研究探索了其他可能的 kernel 选择。

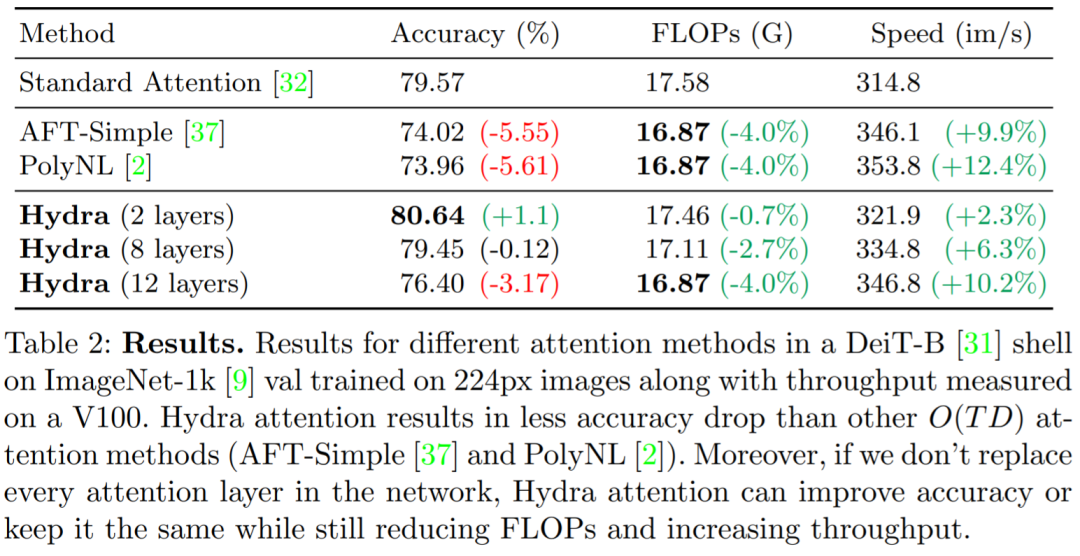
表 2 展示了使用 Hydra attention 与标准注意以及其他方法对比的结果:
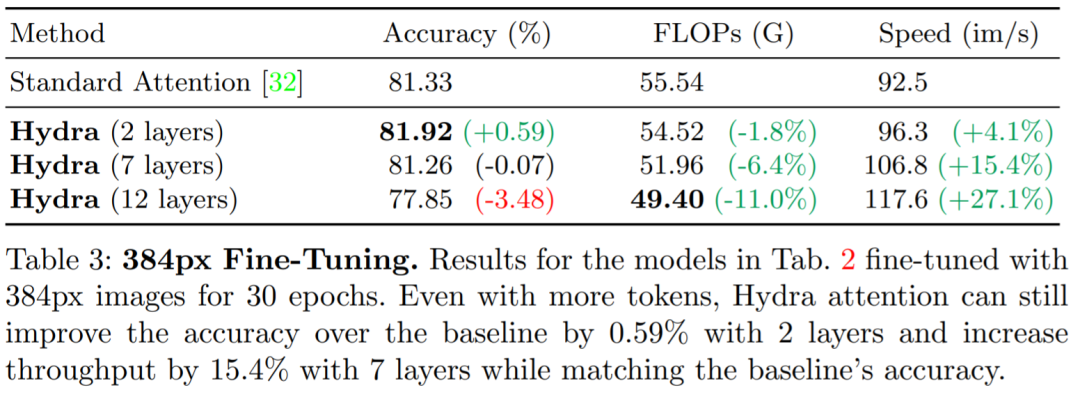
较大的图像:在表 3 中,我们看到 Hydra Attention 在 2 层时可以提高 0.59% 的准确率和 4.1% 的吞吐量,或者在 7 层时保持准确率基本不变,提高 15.4% 的吞吐量。
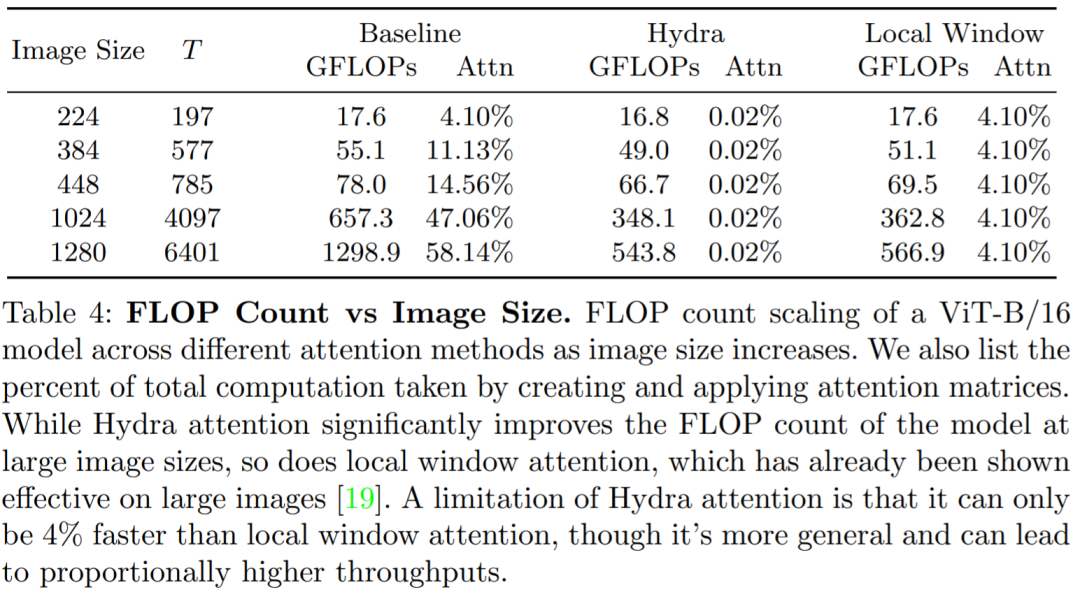
局限性:当 T(token) = 197 时,Hydra attention 比标准注意力快 197 倍,那么为什么最大 FLOP 计数减少只有 4%?事实证明,对于 ViT-B/16 224 × 224 图像(T = 197,D = 768),只有 4.10% 的模型 FLOP 用于创建和应用注意力矩阵。使用 Hydra attention,这一比例降低到 0.02%,基本上消除了模型中的注意力成本。
与高校顶尖学者、技术大神共论AI前沿进展与研究!9月24日上海,欢迎高校青年学子一起参与这场技术沙龙与私享晚宴。
-
聚焦前沿——围绕多模态、大模型、视频处理等 AI 前沿技术,高校顶尖学者、企业技术大神将带来最新研究与实践成果报告。 交流高效——设置报告、对谈、自由交流、晚宴等环节,不仅可以现场聆听业界前辈学术研究指导与建议,还可以与专家学者面对面自由深入交流。
参与便捷——视报名同学学校分布情况提供定点接驳车,获取接驳时间、地址与更多活动详情请添加小助手微信号REDtech01。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

