比标准Attention快197倍!Meta推出多头注意力机制“九头蛇”
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
尽管Transformer已经开始在诸多视觉任务上“大展身手”,但还有一个问题。
那就是在处理大图像上计算比较费劲。
比如面对一个1080p的图时,它会有超过60%的计算量都耗费在了创建和应用注意矩阵上。

究其原因,主要是因为自注意力头的数量是token的平方,而token的数量又与图形大小呈二次方的关系。
那能怎么办呢?
好消息是——
现在Meta捣鼓出了一种多头注意力操作方法,可以做到足足比标准注意力快197倍!
而且在提高计算速度的同时,它也不会牺牲准确率,有时甚至还能将准确率提高1-2个点。

具体怎么回事儿?
思路来源一个“矛盾点”
这个方法名叫Hydra Attention,主要针对Vision Transformer。
(“Hydra”有“九头蛇”之义,来自希腊神话。)
Hydra Attention的思路源于线性注意力中的一种有点矛盾的点:
使用标准的多头自注意力,再向模型中添加更多头可以保持计算量不变。
而在线性注意力中改变操作顺序后,增加更多的头实际上还会降低层的计算成本。
于是,作者通过将模型中的注意力头数量设置成特征(feature)数,创建出一个token和feature的计算都是线性的注意力模块,从而把上述特性发挥到极致。
具体来说:
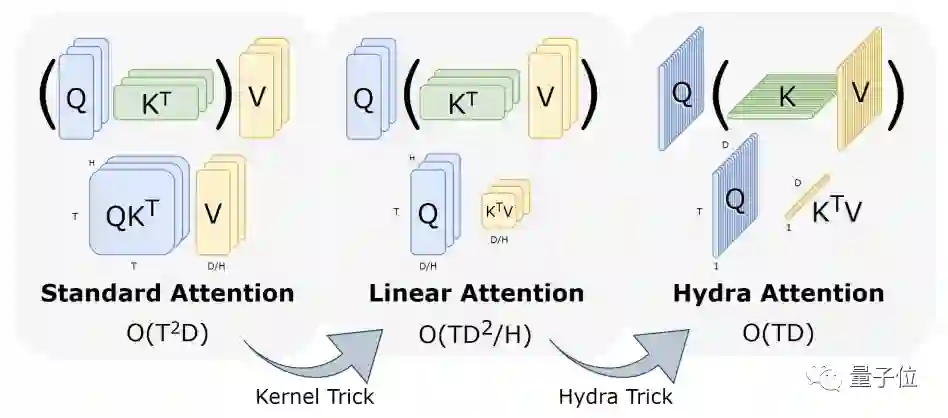
当标准自注意力头是token数的平方(O(T2D))时,通过使用可分解核(decomposable kernel),我们重新安排操作顺序,让注意力头的数量变为特征D的平方。
然后再使用Hydra Trick,最大化注意力头H的数量,让H=D,最终就可以化为一个在空间和时间上的O(TD)简化操作了。
其中,Hydra Trick的依据见下图:
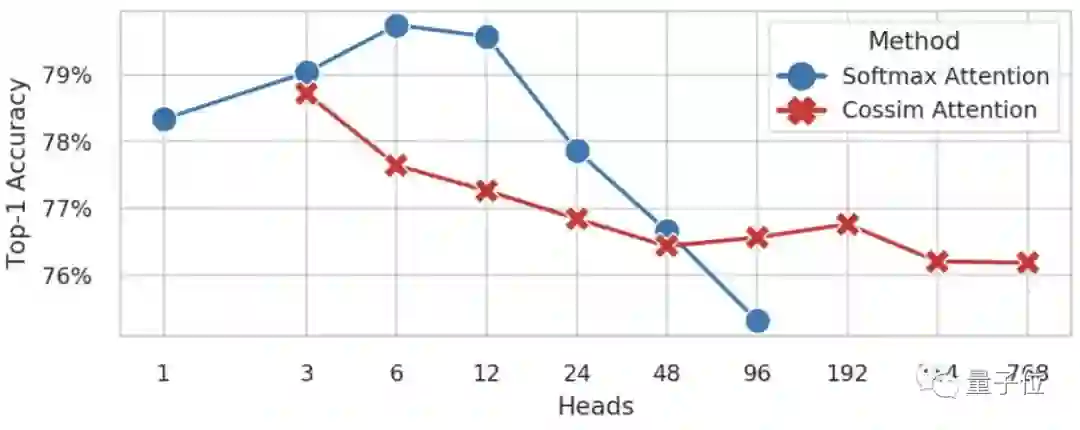
作者在ImageNet-1k上训练了具有不同头数的DeiT-B模型,包括使用标准自注意力(蓝线,基于softmax)和使用多头线性注意(红线,基于余弦相似性)的。
前者在H>96、后者在H<3时出现内存不足的情况。
当他们往模型中添加更多的头时,Softmax注意力模型的准确性似乎会崩溃,而多头线性注意力仍可以保持一致,因此就有了上述操作。
(需要注意的是,H必须除以D=768。)
速度快197倍,准确率还能更上层楼
来看看Hydra Attention交出的成绩单。
可以看到,Hydra注意力比标准注意力快197倍(T=197)。
随着图像大小的增加,它显著提高了模型的FLOP数,在创建和应用注意力矩阵所占的计算量上也始终只有0.02%。
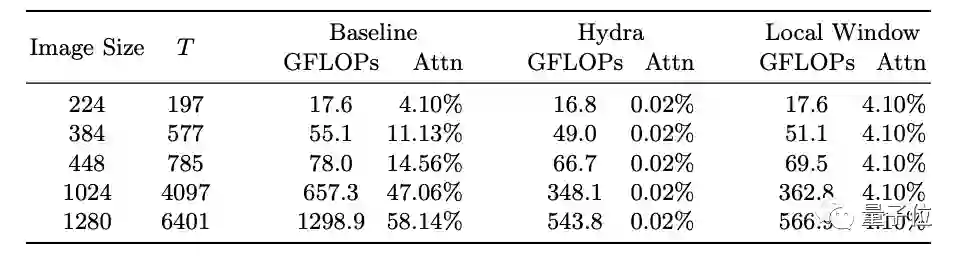
除此之外,作者发现,使用不同的内核,Hydra Attention还能让模型的准确率提高大约两个百分点。

或者用Hydra Attention替换特定的注意力层,也能将模型的精度在ImageNet上提高1%或者与基线维持不变。
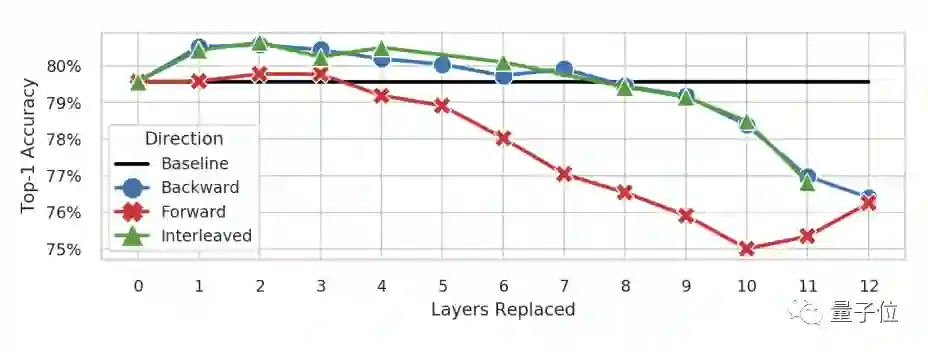
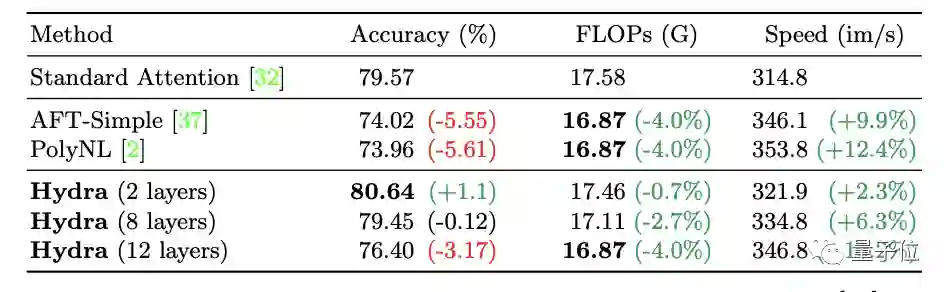
当然,最多可替换8层。
另外,作者表示,这个方法应该可以扩展到NLP领域,不过他们还没试。
作者介绍
这篇成果已入选ECCV 2022 Workshop。
作者一共5位,分别来自Meta AI和佐治亚理工学院。

其中华人3名,分别是:
Cheng-Yang Fu,本硕毕业于清华大学,博士毕业于美国北卡罗来纳大学教堂山分校,现在是Meta计算机视觉方面的研究科学家。
Xiaoliang Dai,本科毕业于北大,博士毕业于普林斯顿大学,同就职于Meta。
Peizhao Zhang,本硕毕业于中山大学,博士于美国德克萨斯A&M大学,已在Meta工作五年。
论文地址:
https://arxiv.org/abs/2209.07484
参考链接:
https://www.reddit.com/r/MachineLearning/comments/xgqwvu/r_hydra_attention_efficient_attention_with_many/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
PS. 加好友请务必备注您的姓名-公司-职位哦 ~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~

