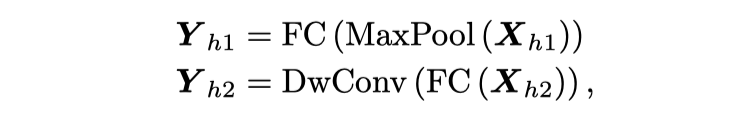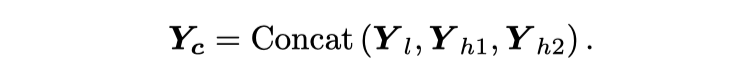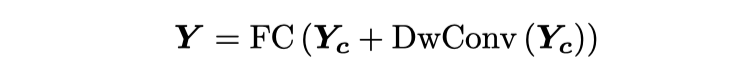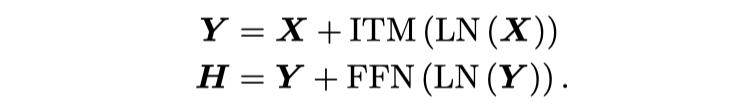![]()
©PaperWeekly 原创 · 作者 | Jason
研究方向 | 计算机视觉
摘要
最近的研究表明,Transformer 具有很强的构建远程相关性的能力,但在捕获传递局部信息的高频信息方面表现较差。为了解决这个问题,作者提出了一种新型的通用 Inception Transformer,简称 iFormer,它可以有效地学习视觉数据中的高频和低频信息的综合特征。
具体而言,作者设计了一个 Inception mixer,以移植卷积和最大池化的优点,将高频信息捕获到 Transformer。与最近的混合框架不同,Inception mixer 通过通道分裂机制带来了更高的效率,采用并行卷积/最大池化路径和自注意路径作为高频和低频混频器,同时能够灵活地建模分散在较宽频率范围内的鉴别信息。
考虑到底层在捕捉高频细节方面的作用更大,而顶层在建模低频全局信息方面的作用更大,作者进一步引入了一种频率渐变结构,即逐渐减小馈送到高频混频器的尺寸,增加馈送到低频混频器的尺寸,它可以有效地在不同层之间权衡高频和低频分量。
作者在一系列视觉任务中对 iFormer 进行了基准测试,并展示了它在图像分类、COCO 检测和 ADE20K 分割方面取得的惊人的性能。例如,iFormer-S 在 ImageNet-1K 上达到了83.4% 的 Top-1 精度,比 DeiT-S 高出了 3.6%,甚至比更大的 Swin-B(83.3%)略好,只有 1/4 的参数和 1/3 的 FLOPs。
![]()
论文和代码地址
![]()
论文标题:
Inception Transformer
https://arxiv.org/abs/2205.12956
https://github.com/sail-sg/iFormer
![]()
Motivation
Transformer 在自然语言处理(NLP)领域掀起了高潮,在许多 NLP 任务中取得了不错的高性能,例如机器翻译和问答。这在很大程度上归功于它具有强大的能力,能够利用自注意机制对数据中的长期依赖关系进行建模。它的成功使研究人员研究了它对计算机视觉领域的适应性,视觉 Transformer(ViT)是一个先驱工作,该结构直接继承自 NLP,但应用于以原始图像块作为输入的图像分类。后来,开发了许多 ViT 变体,以提高性能或扩展到更广泛的视觉任务,例如,目标检测和分割。
ViT 及其变体能够捕获视觉数据中的低频率信息,主要包括场景或对象的全局形状和结构,但对于学习高频率(主要包括局部边缘和纹理)的能力不是很强。这可以直观地解释:ViTs 中用于在非重叠 patch token 之间交换信息的主要操作 self-attention 是一种全局操作,比起局部信息(低频),它更适合捕获全局信息(高频)。
![]()
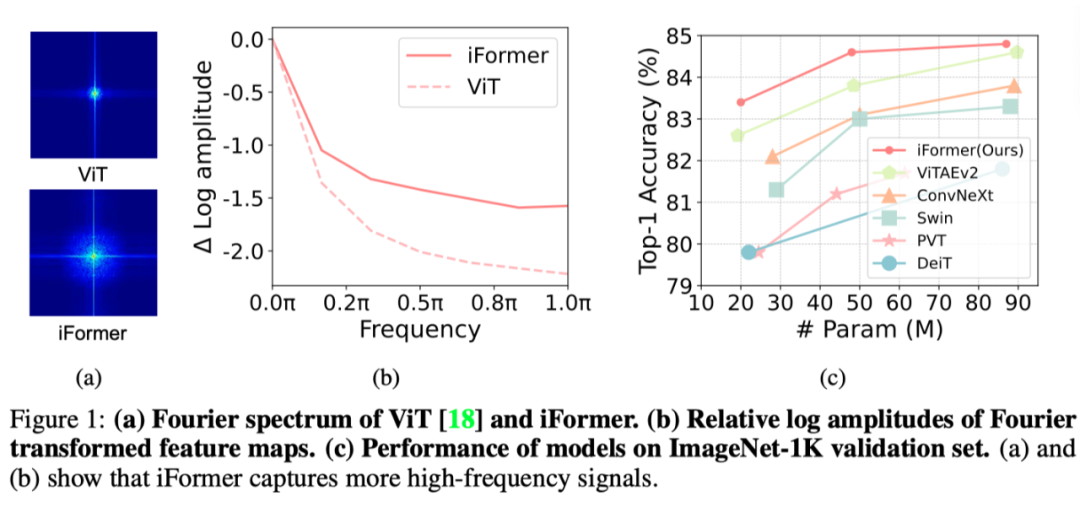
如图 1(a)和 1(b)所示,傅里叶频谱和傅里叶的相对对数振幅表明,ViT倾向于很好地捕捉低频信号,但很少捕捉高频信号。这表明ViT呈现出低通滤波器的特征。这种低频偏好性会损害 VIT 的性能,因为:1)所有层中的低频信息填充可能会恶化高频成分,例如局部纹理,并削弱 VIT 的建模能力;2) 高频信息也是有区别的,可以帮助完成许多任务,例如(细粒度)分类。
实际上,人类视觉系统以不同的频率提取视觉基本特征:低频率提供有关视觉刺激的全局信息,高频率传达图像中的局部空间变化(例如,局部边缘/纹理)。因此,有必要开发一种新的ViT结构,用于捕获视觉数据中的高频和低频。
CNN 是一般视觉任务最基本的支柱。与 VIT 不同,它们通过感受野内的局部卷积覆盖更多的局部信息,从而有效地提取高频表示。最近的研究考虑到 CNN 和 VIT 的互补优势,将其整合在一起。一些方法以串行方式堆叠卷积和注意层,以将局部信息注入全局上下文。
不幸的是,这种串行方式仅在一个层中对一种类型的依赖项(全局或局部)进
行建模,并在局部建模期间丢弃全局信息,反之亦然。其他的工作采用平行注意和卷积来同时学习输入的全局和局部依赖性。然而,一部分通道用于处理局部信息,另一部分用于全局建模,这意味着如果处理每个分支中的所有通道,则当前的并行结构具有信息冗余。
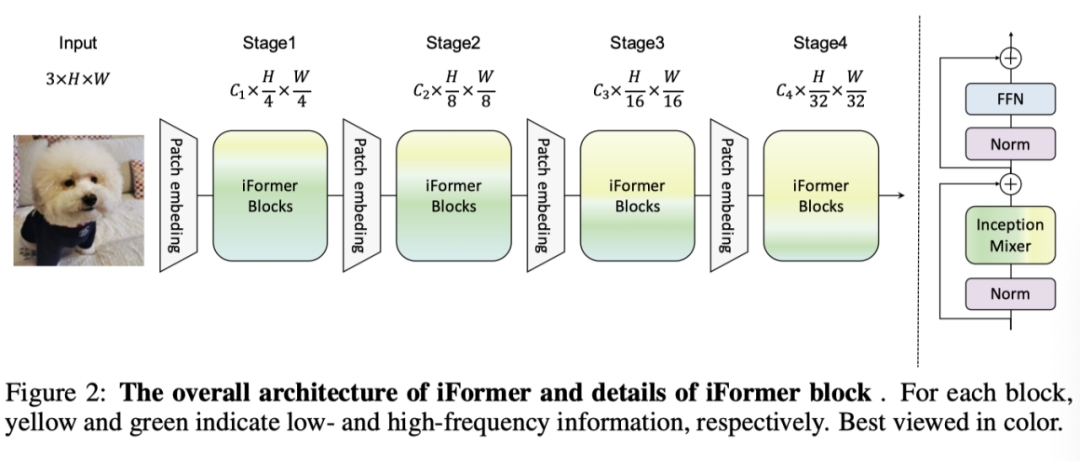
为了解决这个问题,作者提出了一种简单有效的 Inception Transformer(iFormer),它将 CNN 捕捉高频的优点移植到 ViT 上。iFormer 中的关键组件是 Inception token mixer。该 Inception mixer 旨在通过捕获数据中的高频和低频来增强 VIT 在频谱中的感知能力。
为此,Inception mixer 首先沿通道维度拆分输入特征,然后将拆分后的分量分别送入高频混频器和低频混频器。在这里,高频混频器由最大池化操作和并行卷积操作组成,而低频混频器由 ViTs 中的自注意力实现。通过这种方式,本文的 iFormer 可以有效地捕获相应通道上的特定频率信息,从而在较宽的频率范围内学习比 ViT 更全面的特征。
此外,作者发现,较低层通常需要更多的局部信息,而较高层需要更多的全局信息。这是因为,与人类视觉系统一样,高频成分中的细节有助于较低层捕捉视觉基本特征,并逐渐收集局部信息,以便对输入进行全局理解。受此启发,作者设计了一种频率斜坡结构(frequency ramp structure)。具体来说,从低层到高层,作者逐渐将更多的通道尺寸馈送到低频混频器和更少的通道送入到高频混频器。这种结构可以在所有层之间权衡高频和低频分量。
实验结果表明,iFormer 在图像分类、目标检测和分割等多项视觉任务上均优于 SOTA 的 ViTs 和 CNN。例如,如图 1(c)所示,在不同的模型尺寸下,iFormer 对 ImageNet-1K 上流行的框架进行了一致的性能提升,例如 DeiT、Swin 和 ConvNeXt。同时,iFormer 在 COCO 检测和 ADE20K 分割方面优于最近的框架。
![]()
方法
3.1 Revisit Vision Transformer
对于视觉任务,Transformers 首先将输入图像分割为一系列 token,每个 patch token 被投影到一个隐藏的表示向量中,该向量具有一个更精简的层,表示为
或
,其中 N 是 patch token 的数量,C 表示特征的维度。然后,将所有 token 与位置嵌入相结合,并馈送到包含多头自注意(MSA)和前馈网络(FFN)的 Transformer 层。
![]()
在 MSA 中,基于注意力的混合器在所有 patch token 之间交换信息,因此它将重点放在聚合所有层的全局依赖关系上。然而,全局信息的过度传播将加强低频表示。
从图 1(a)中傅里叶频谱的可视化可以看出,低频信息主导ViT的表示。但这实际上会损害ViT的性能,因为它可能会恶化高频成分,例如局部纹理,并削弱ViTs的建模能力。在视觉数据中,高频信息也是有区别的,可以帮助完成许多任务。因此,为了解决这个问题,作者提出了一种简单有效的 Inception Transformer,如上图所示,具有两个关键的新颖之处,即 Inception mixer 和频率斜坡结构。
3.2 Inception token mixer
![]()
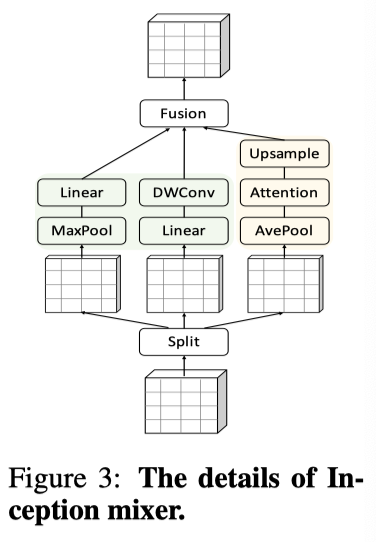
作者提出了一种 Inception mixer,将 CNN 提取高频表示的强大功能移植到 Transformer 中。其详细架构如上图所示。Inception mixer 不是直接将图像 token 输入 MSA 混频器,而是首先沿通道维度拆分输入特征,然后分别将拆分后的分量输入高频混频器和低频混频器。这里,高频混频器由最大池化操作和并行卷积操作组成,而低频混频器由自注意力实现。
从技术上讲,给定输入特征映射
,将
沿着通道维度分解为
和
,其中
。然后,
和
分别分配给高频混频器和低频混频器。
3.2.1 High-frequency mixer
考虑到最大滤波器的灵敏度和卷积运算的细节感知,作者提出了一种并行结构来学习高频组件。将
沿着通道维度划分为
和
。如上图所示,
嵌入最大池化和线性层,
馈入线性和深度卷积层:
![]()
![]()
作者设计了一个融合模块,在 patch 之间进行深度卷积交换信息,同时加入一个跨通道线性层,该层在每个位置工作,就像以前的 Transformer 一样。最终输出可表示为:
![]()
与 vanilla Transformer 一样,本文的 iFormer 配备了前馈网络(FFN),不同的是,它还集成了上述 Inception token mixer(ITM);LayerNorm(LN)被用到了 ITM 和 FFN 之前。因此,Inception Transformer 块表示为:
![]()
3.2.2 Low-frequency mixer
作者使用 vanilla multi-head self-attention 在低频混频器的所有 token 之间传递信息。尽管注意学习全局表示的能力很强,但特征图的分辨率较大会在较低层带来较大的计算开销。因此,需在注意力操作之前使用一个平均池化层来减小
的空间尺度,并在注意操作之后使用一个上采样层来恢复原始的空间维度。这种设计大大减少了计算开销,并使注意力操作集中于嵌入全局信息。该分支可以定义为:
![]()
其中,
是低频混频器的输出。池化和上采样层的内核大小和步长仅在前两个阶段设置为 2。
3.3 Frequency ramp structure
在一般的视觉框架中,底层在捕捉高频细节方面发挥着更多的作用,而顶层在建模低频全局信息方面发挥着更多的作用。与人类一样,通过捕获高频成分中的细节,较低层可以捕获视觉基本特征,并逐渐收集局部信息,以实现对输入的全局理解。作者受此启发,设计了一种频率斜坡结构,它将更多的通道尺寸从较低层到较高层逐渐分割到低频混频器,从而将更少的通道尺寸留给高频混频器。
具体而言,如图 2 所示,我们的主干网络有四个阶段,具有不同的通道和空间维度。对于每个块,作者定义了一个通道比(即,
,
,
),以更好地平衡高频和低频分量。在提出的频率斜坡结构中,从浅到深,
逐渐降低,而
逐渐增加。因此,借助灵活的频率斜坡结构,iFormer 可以有效地权衡所有层的高频和低频分量。
![]()
实验
![]()
上表总结了 ImageNet 上所有比较方法的图像分类精度。对于较小的模型尺寸(∼20M),本文的 iFormer 超越了 SoTA 的 VIT 和混合 VIT。具体而言,与 SoTA 的 ViTs(即 CSwin-T)和混合 ViTs(即 UniFormer-S)相比,本文的 iFormer-S 分别获得 0.7% 和 0.5% 的 top-1 精度优势,同时有相同或更小的模型尺寸。
![]()
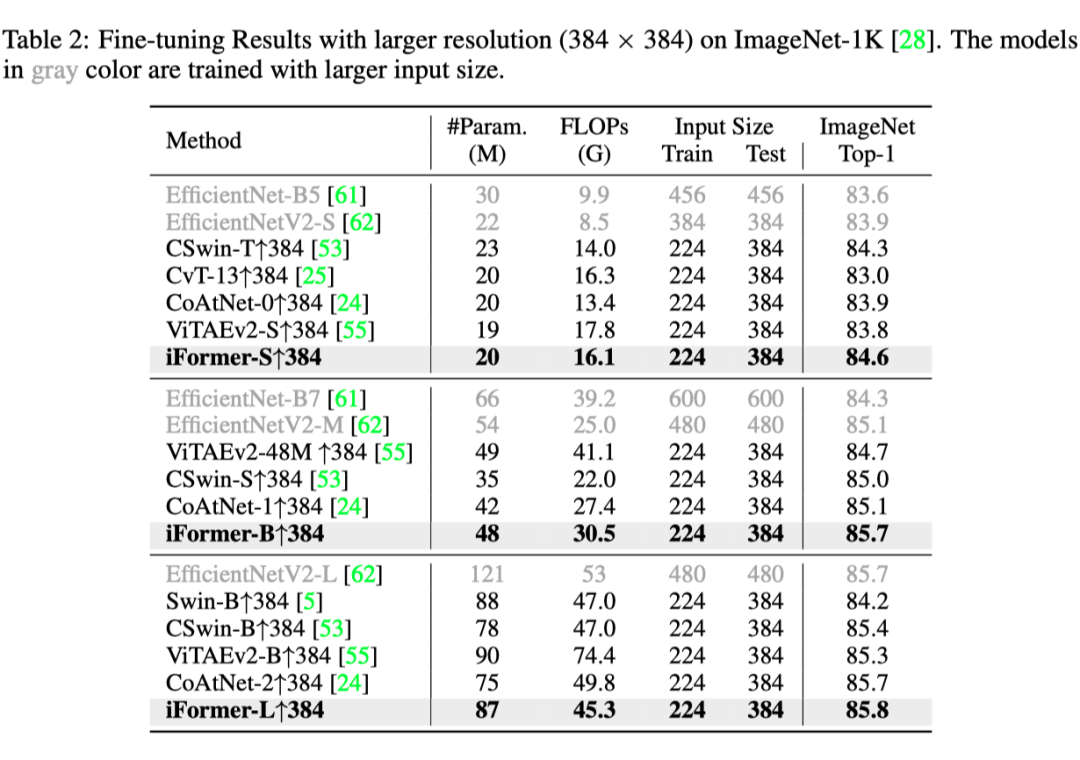
上表报告了较大分辨率(即 384×384)的微调精度。可以观察到,iFormer 在不同计算设置下的表现始终优于同类模型。这些结果清楚地表明了 iFormer 在图像分类方面的优势。
![]()
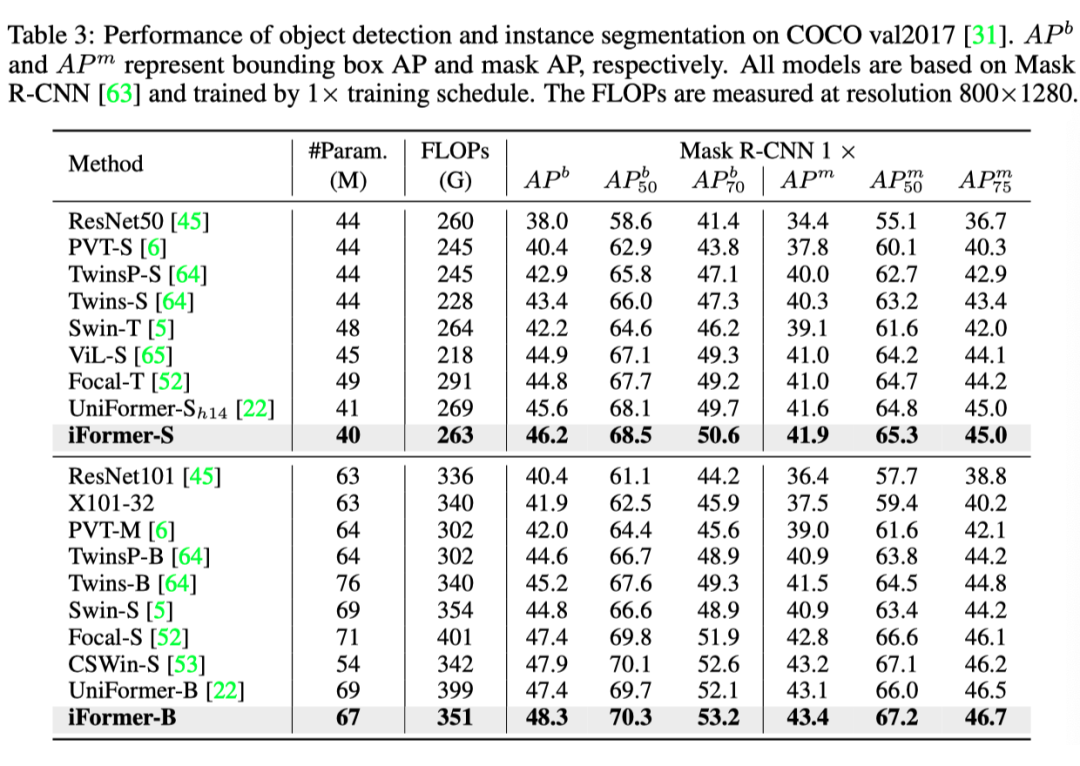
上表报告了比较模型的 box mAP 和 mask mAP。在类似的计算配置下,iFormers 的性能优于以前的所有主干网。
![]()
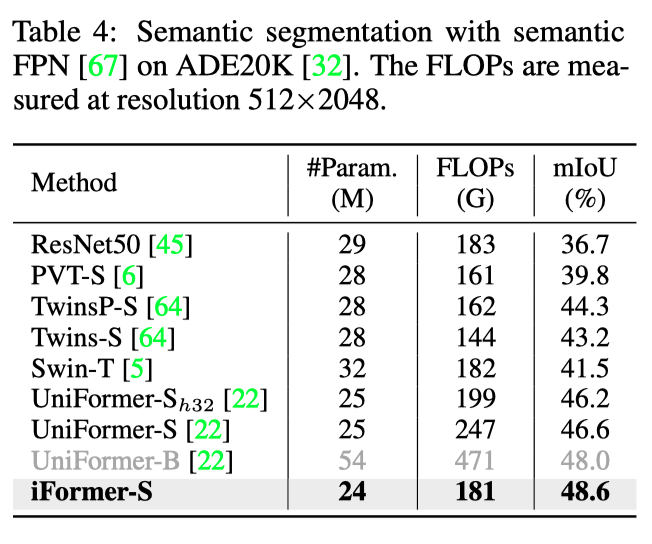
在上表中,作者报告了不同主干网络的 mIoU 结果。在语义 FPN 框架上,本文的 iFormer 在这项任务上始终优于以前的主干,包括 CNN 和(混合)VIT。
![]()
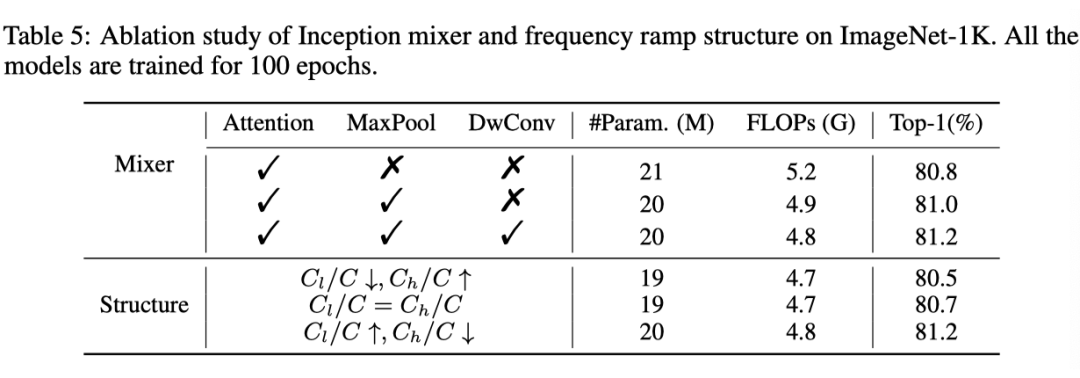
在上表中,可以看出将注意力与卷积和最大池化相结合,可以比仅注意混合器获得更好的精度,同时使用更少的计算复杂性,这意味着 Inception Token Mixer.的有效性。此外,表格中下半部分的结果证明了,频率斜坡结构的合理性及其在学习辨别性视觉表征方面的潜力。
![]()
为了进一步探索该方案,上图显示了 Inception mixer.中注意、MaxPool 和 DwConv 分支的傅立叶谱。
![]()
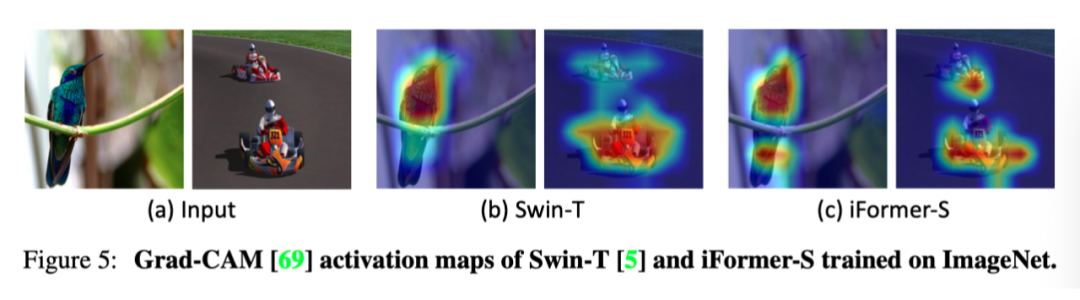
在上图中,作者可视化了 ImageNet-1K 上训练的 iFormer-S 和 Swin-T 模型的 Grad-CAM 激活图。可以看出,与 Swin 相比,iFormer 可以更准确、更完整地定位对象。例如,在蜂鸟图像中,iFormer 跳过树枝并准确地关注整个鸟,包括尾巴。
![]()
总结
在本文中,作者提出了一种 Inception Transformer(iFormer),这是一种新型的通用 Transformer 主干。iFormer 采用通道分割机制,简单有效地将卷积/最大化池化和自注意力耦合在一起,使其更专注于高频信息,并扩展了 Transformer 在频谱中的感知能力。基于灵活的 Inception token 混频器,作者进一步设计了一种频率斜坡结构,能够在所有层的高频和低频分量之间进行有效的权衡。大量实验表明,iFormer 在图像分类、目标检测和语义分割方面优于典型的视觉 Transformer,显示了 iFormer 作为计算机视觉通用主干的巨大潜力。
本文的一个缺点是提出的 iFormer 的一个明显限制是,它需要在频率斜坡结构中手动定义通道比率,即每个 iFormer 块的
和
,这需要丰富的经验来更好地定义不同任务。
![]()
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()