港中大等打造光流预测新模型SelFlow,自监督学习攻克遮挡难题 | CVPR 2019

新智元报道
新智元报道
来源:arxiv
编辑:大明
【新智元导读】对光流的学习和跟踪是计算机视觉领域的基本任务。在3D目标跟踪、处理和重建等实际任务中,经常需要对被遮挡的光流进行预测。本文介绍在CVPR2019上发表的一篇论文,在多个数据集的光流预测任务上大幅提升了预测性能。
光流是计算机视觉的一个基本任务,它描述了视频中的运动信息,相关技术广泛应用于视频理解和处理、物体跟踪、三维重建、自动驾驶等场景。近日,来自香港中文大学和腾讯AI实验室团队的一篇论文入选了CVPR2019。
论文题为《一种自监督的光流学习方法》。论文团队探索了使用卷积神经网络估计光流的一个关键挑战:预测被遮挡像素的光流。

论文地址:
https://arxiv.org/abs/1904.09117
论文第一作者刘鹏鹏详细阐述了该论文的意义:“首先,我们提出了一种从没有标注的数据中学习光流的自监督训练框架。这个方法会人为创造一些遮挡,然后利用已经学习到的比较准确的没有被遮挡像素的光流去指导神经网络学习被遮挡像素的光流。其次,我们设计一个可以利用多帧图像时序连续性的网络结构来更好地学习光流。
基于这两个原则,我们的方法在MPI Sintel, KITTI 2012和KITTI 2015等数据集上取得了最好的无监督学习效果。更重要的是,我们的无监督方法得到的模型为有监督的微调提供了一个很好的初始化,消除了训练光流神经网络对仿真数据的依赖。经过有监督微调,我们的模型在以上三个数据集上取得了目前最优的性能,这是光流研究历史上第一次不使用额外仿真数据达到的最高准确度。
我们在写这篇文章的时候(2018年11月),我们的模型在Sintel评测集上取得EPE=4.26,超过来自世界各地研究机构的所有180多种已经提交的方法。直到今天,我们的算法在Sintel榜单上还是第一。”
自监督光流学习框架SelFlow:刷新多项预测精度纪录
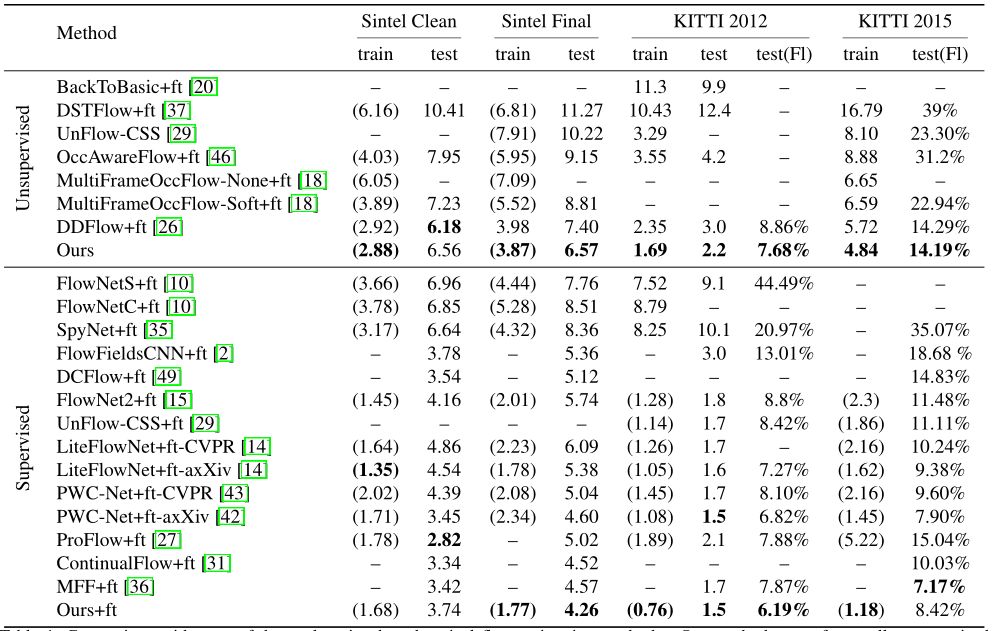
表1:与基于最先进学习的光流估计方法的比较。我们的方法优于所有数据集上的所有无监督光流学习方法。我们的监督微调模型在Sintel Final数据集和KITTI 2012数据集上实现了最高精度。除KITTI 2012和KITTI 2015测试集的最后一列外,所有数字均为EPE,我们报告了所有像素(Fl-all)上的错误像素百分比。( - )表示未报告相应方法的结果。括号表示训练和测试是在同一数据集上执行的。粗体字为无监督和监督方法中的最佳结果。
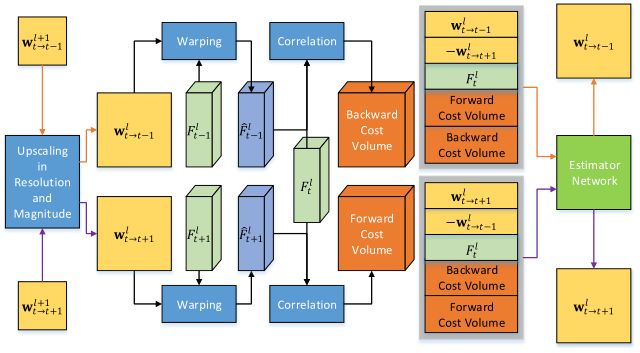
图2 在每个级别的网络架构(类似于PWC-Net)。˙wl表示水平l的初始粗流,F l表示翘曲的特征表示。在每个级别,将初始流量和成本量作为输入交换,以便同时估计前向流量和后向流量。再将这些估计传递到l-1层上,估计更高分辨率的流。
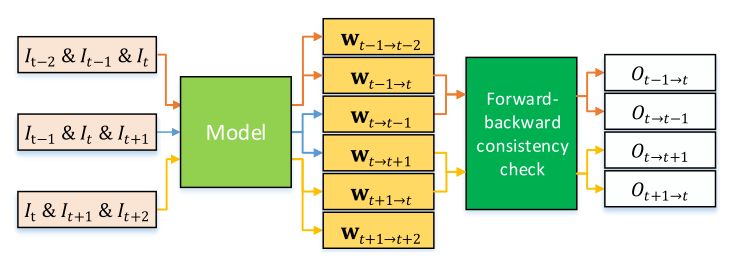
图3 多帧自训练的数据流。为了估计三帧流学习的遮挡图,我们使用五个图像作为输入。这样,我们可以进行前后一致性检查,以分别估计I t和I t + 1之间,I t和I t-1之间的遮挡图。

图4 在Sintel和KITTI数据集上对无监督结果进行抽样。图中由上至下依次为在Sintel Final,KITTI 2012和KITTI 2015数据集上的取样。
图5 在Sintel Clean培训和Sintel Final测试数据集的不同设置下的定性比较。遮挡处理,多帧制定和自我监督不断提高性能
实验结果与分析:多项数据集预测性能显著提升
如表1所示,我们在所有评估指标下的所有数据集上实现了无监督和监督光流学习的最新结果。图4所示为Sintel和KITTI的样本结果。
无监督学习
本文中的方法在基准测试中实现了无监督学习方法的最高精度。在Sintel Final基准测试中,将之前的最佳EPE从7.40 降低到6.57,相对提升幅度为11.2%。这甚至比包括FlowNetS,FlowNetC和SpyNet在内的几种完全监督方法更优秀。在KITTI数据集上的改进更为明显。
对于训练数据集,我们实现了EPE = 1.69,KITTI 2012的相对改进幅度为28.1%,EPE = 4.84,与之前最佳无监督方法DDFlow相比,KITTI 2015的相对改进为15.3%。在KITTI 2012测试集中,实现了Fl-all = 7.68%,这比包括FlowNet2,PWC-Net,ProFlow和MFF在内的最先进的监督学习方法实现了更好的性能。在KITTI 2015基准测试中,实现了Fl-all=14.19%,优于所有无监督方法。其中一些无监督学习的结果也优于一些完全监督的方法,包括DCFlow和ProFlow等。
监督式微调
使用Ground-truth流程进一步对无监督学习模型进行微调后,模型在所有三个数据集上都获得了最先进的结果,KITTI 2012上的Fl-all = 6.19%,KITTI 2015上的Fl-all = 8.42%。最重要的是,我们的方法在Sintel Final数据集上实现了EPE = 4.26 ,在所有提交的方法中实现Sintel了基准测试的最高精度。所有这些都表明,我们的方法减少了预训练对合成数据集的依赖,不必再遵循不同数据集来专门制定训练计划。
结论与未来方向:有效降低对标记数据集的依赖
本文提出了一种自我监督的方法来学习准确的光流估计,此方法将噪声注入到超级像素中以创建遮挡,让一个模型引导另一个模型来学习遮挡像素的光流。我们通过简单的CNN有效地聚合来自多个帧的时间信息,改进流量预测精度。大量实验表明,我们的方法明显优于所有现有的无监督光流学习方法。在使用我们的无监督模型进行微调后,模型在所有领先的基准测试中实现了最先进的流量估算精度结果。我们的研究可以完全降低预训练过程对合成标记数据集的依赖,并通过对未标记数据进行自监督的预训练,实现优异的预测性能。
论文链接:
SelFlow: Self-Supervised Learning of Optical Flow
https://arxiv.org/abs/1904.09117








