CVPR 2018 | 腾讯AI Lab、MIT等机构提出TVNet:可端到端学习视频的运动表征
来源:机器之心
作者:Lijie Fan、Wenbing Huang、Chuang Gan、Stefano Ermon、Boqing Gong、Junzhou Huang
尽管端到端的特征学习已经取得了重要的进展,但是人工设计的光流特征仍然被广泛用于各类视频分析任务中。
为了弥补这个不足,由来自腾讯 AI Lab、MIT、清华、斯坦福大学的研究者完成并入选 CVPR 2018 Spotlight 论文的一项研究提出了一种能从数据中学习出类光流特征并且能进行端到端训练的神经网络:TVNet。
该研究成果的 TensorFlow 实现已经发布在 GitHub 上。
论文地址:https://arxiv.org/abs/1804.00413
代码地址:https://github.com/LijieFan/tvnet
图像分类和目标检测等基于图像的任务已经在深度学习(尤其是卷积神经网络(CNN))的推动下实现了革命性的发展。
但是,视频分析方面的进展却并不尽如人意,这说明学习时空数据的表征是非常困难的。我们认为其中主要的难点是:寻找视频中明显的运动信息(motion cue)需要某种新型网络设计,而这些设计尚未被找到和测试。
尽管已经有些研究在尝试通过在空间和时间维度上同时执行卷积运算来学习特征,但是人工设计的光流(optical flow)特征在视频分析上仍有广泛和有效的应用。
光流,顾名思义,是指两个连续帧之间的像素位移。因此,将光流应用到视频理解任务上可以明确而方便地实现运动线索的建模。然而,这种方法很低效,估计光流的计算和存储成本往往很高。
目前成功将光流应用于视频理解的重要方法之一是 two-stream model [33],其在光流数据上训练了一个用于学习动作模式的卷积网络。研究者们已经提出了一些不同的 two-stream model 的扩展,并在动作识别和动作检测等多种任务上实现了当前最佳水平。
尽管表现出色,但当前的基于光流的方法存在一些显著缺陷:
训练是一种双阶段过程。第一个阶段是通过基于优化的方法(比如 TVL1 [42])提取每两个连续帧的光流。第二个阶段是基于提取出的光流数据上训练一个 CNN。这两个阶段是分开的,而且来自第二个阶段的信息(比如梯度)无法被用于调节第一个阶段的过程。
光流提取的空间和时间成本很高。提取出的光流必须写入到磁盘上,以便训练和测试。对于包含大约 1 万段视频的 UCF101 数据集而言,通过 TVL1 方法提取所有数据的光流需要消耗一个 GPU 一整天时间,而将原来的场作为浮点数来存储这些光流需要至少 1TB 的存储空间(为了节省存储成本,通常需要线性归一化成 JPEG)。
为了解决上述问题,我们提出了一种全新的神经网络设计,可以端到端的方式学习类光流的特征。这个名叫 TVNet 的网络是通过模仿和展开 TV-L1 的迭代优化过程而获得的。尤其值得一提的是,我们将 TV-L1 方法中的迭代形式化为了神经网络的自定义层。因此,我们的 TVNet 的设定基础良好,无需任何额外训练就能直接被使用。
此外,我们的 TVNet 是可以端到端地训练的,因此可以自然地连接到特定任务的网络上(比如动作分类网络),进而实现「更深度」的可端到端训练的架构。因此,无需再预计算或存储光流特征。
最后,通过执行端到端学习,被初始化为标准的光流特征提取器的 TVNet 的权重可以得到进一步的调节。这让我们可以发现更丰富且更针对任务的特征(相比于原始的光流),从而实现更优的表现。
为了验证我们提出的架构的有效性,我们在两个动作识别基准(HMDB51 和 UCF101)上执行了实验,比较了我们提出的 TVNet 和几种互相竞争的方法。
总体而言,本论文有以下贡献:
我们通过将 TV-L1 方法的迭代展开成自定义的神经层,开发了一种学习视频中的运动的全新神经网络。这个网络名叫 TVNet,具有良好的初始化。
尽管我们提出的 TVNet 是以特定的 TV-L1 架构初始化的,但相比于标准的光流,它可以在进一步微调之后学习到更丰富和更面向任务的特征。
相比于其它动作表征学习的方法(比如 TV-L1、FlowNet2.0 和 3D Convnets),我们的 TVNet 在两个动作识别基准上实现了更优的准确度,即在 HMDB51 上实现了 72.6% 的准确度、在 UCF101 上实现了 95.4% 的准确度。

算法 1:用于光流提取的 TV-L1 方法

图 1:由 TV-L1、TVNet(无训练)、TVNet(有训练)得到的类光流运动特征的可视化结果
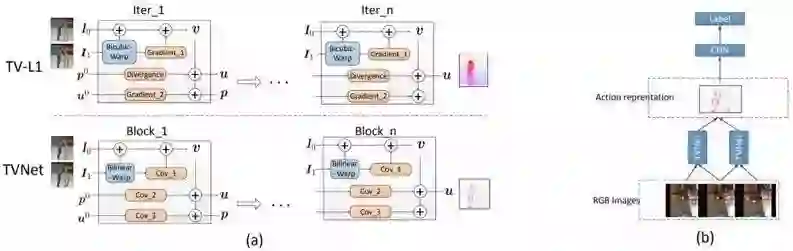
图 2:(a)将 TV-L1 展开成 TVNet 的过程示意图。对于 TV-L1,我们只描述了算法 1 中的单次迭代。我们将 TV-L1 中的双三次翘曲(bicubic warping)、梯度和散度计算重新形式化为了 TVNet 中的双线性翘曲(bilinear warping)和卷积运算。(b)用于动作识别的端到端模型。

图 3:TV-L1 和 TVNet-50 在 MiddleBurry 上估计得到的光流示例。经过训练后,TVNet-50 可以提取出比 TV-L1 更精细的特征。
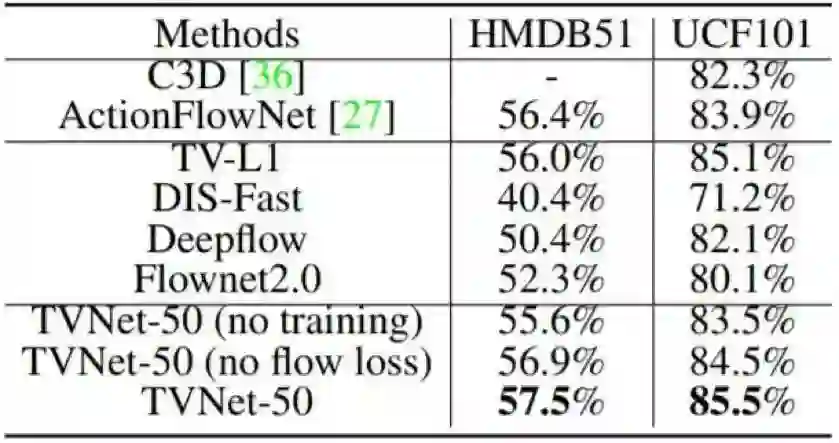
表 3:在 HMDB51 和 UCF101 上的各种运动描述器的分类准确度。上面一部分是之前最佳的动作表征方法的结果;中间一部分给出了 4 种基准方法的准确度;下面的结果表明我们的 TVNet-50 模型在这两个数据集上都得到了最佳表现。
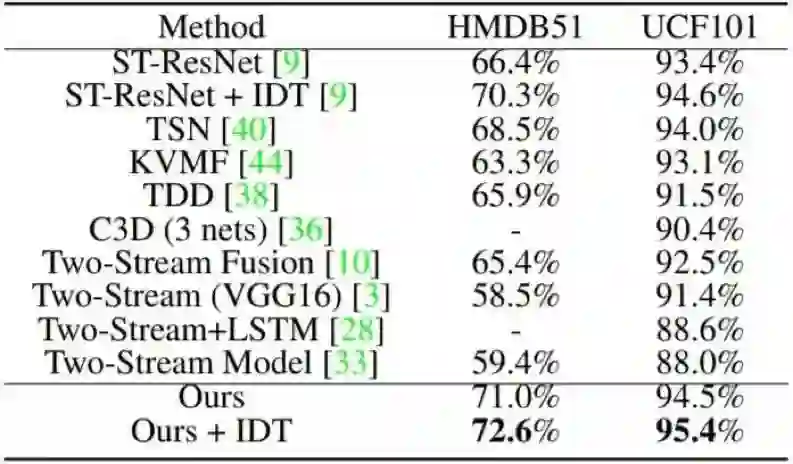
表 4:在 HMDB51 和 UCF101 上的平均分类准确度
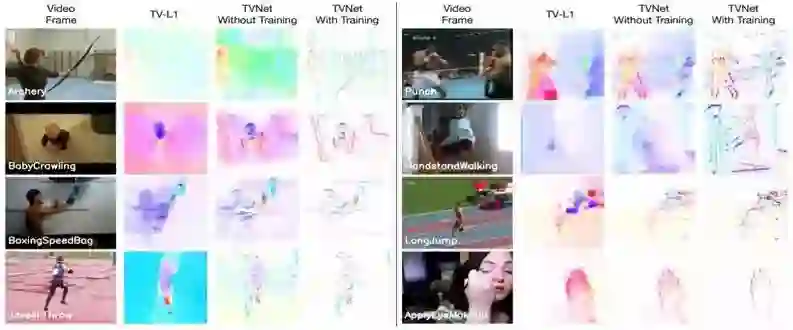
图 4:TV-L1 和 TVNet-50 在 UCF101 数据集上得到的运动特征。从第一列到最后一列,我们分别展示了输入图像对(仅第一张图像)、TV-L1 得到的运动特征、无训练和有训练的 TVNet-50 得到的运动特征。有意思的是,使用训练后,TVNet-50 可以得到比 TV-L1 及 TVNet-50 的非训练版本更抽象的运动特征。这些特征不仅自动移除了背景的运动(参见「punch」示例),而且还捕捉到了运动物体的轮廓。
论文:用于视频理解的运动表征的端到端学习(End-to-End Learning of Motion Representation for Video Understanding)

尽管端到端学习的表征近来取得了成功,但视频分析任务广泛使用的仍然还是人工设计的光流特征。为了弥补这一不足,我们提出了一种全新的可端到端训练的神经网络 TVNet,可从数据中学习类光流特征。
TVNet 是一种特定的光流求解器 TV-L1 方法,并且通过将 TV-L1 中的优化迭代展开成神经层而进行了初始化。因此,TVNet 无需任何额外训练就能直接使用。
此外,它还可以自然地嫁接到其它特定任务的网络上,从而得到端到端的架构;因此,这种方法无需预计算和在磁盘上预存储特征,比之前的多阶段方法更加高效。
最后,TVNet 的参数可以通过端到端训练进一步优化。这让 TVNet 不仅可以学习光流,而且还可以学习到更丰富的且更针对任务的动作模式。
我们在两个动作识别基准上进行了广泛的实验,结果表明了我们提出的方法的有效性。我们的 TVNet 实现了比所有同类方法更优的准确度,同时在特征提取时间方面也能与最快的同类方法媲美。
*推荐文章*
PS.极市平台正寻求与开发者视觉算法的合作,欢迎联系小助手(微信:Extreme-Vision)沟通合作~ 填写表单http://form.mikecrm.com/wcotd9,即可加入极市CV开发者群,与CV大牛切磋交流~



